Department of Computer Science, Johns Hopkins University, Baltimore, USA.
Genome Biol. 2021 Jan 4;22(1):8. doi: 10.1186/s13059-020-02229-3.
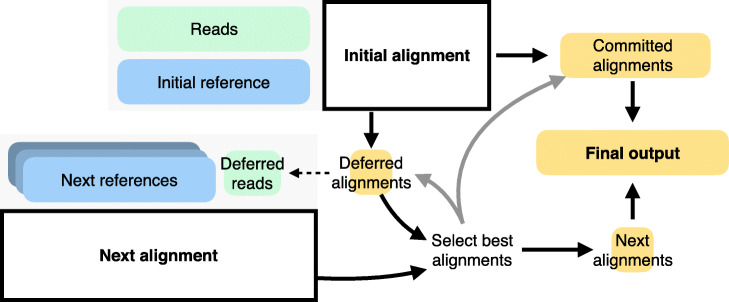
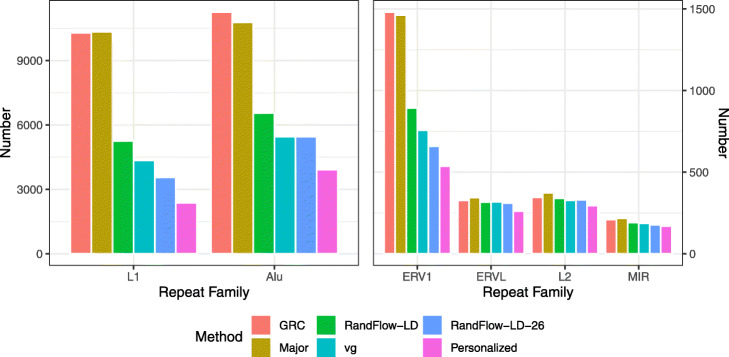
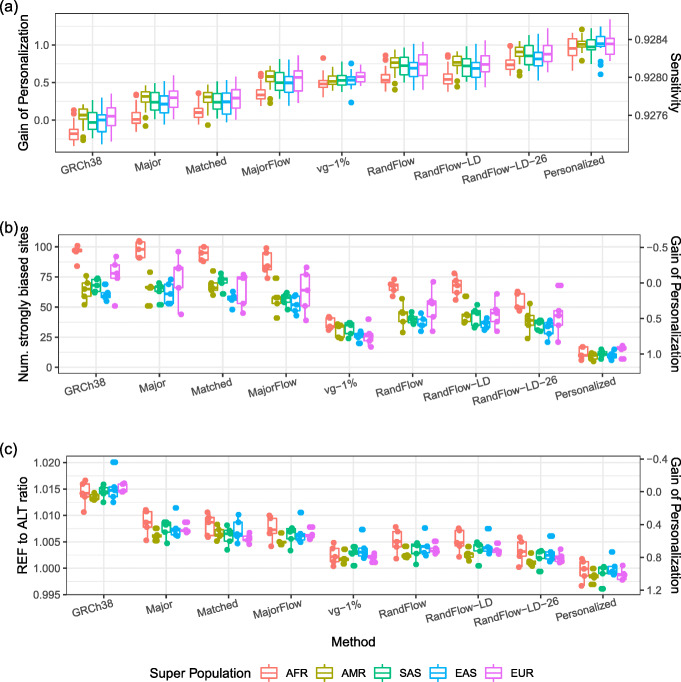
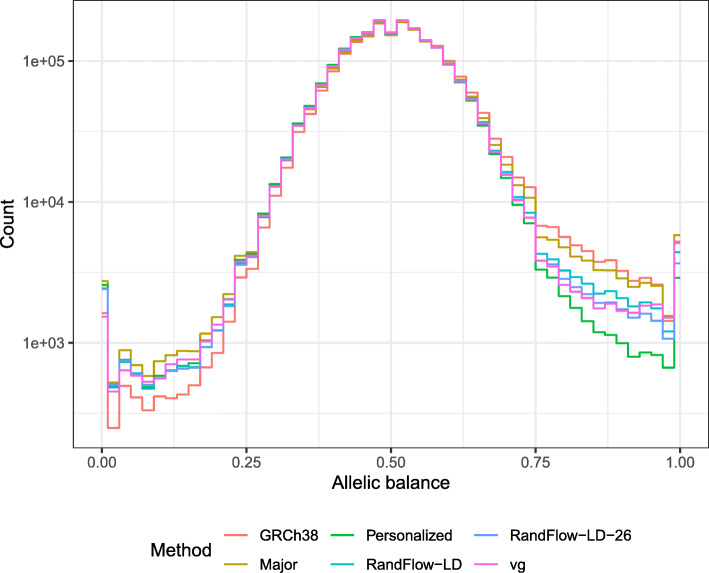
Most sequencing data analyses start by aligning sequencing reads to a linear reference genome, but failure to account for genetic variation leads to reference bias and confounding of results downstream. Other approaches replace the linear reference with structures like graphs that can include genetic variation, incurring major computational overhead. We propose the reference flow alignment method that uses multiple population reference genomes to improve alignment accuracy and reduce reference bias. Compared to the graph aligner vg, reference flow achieves a similar level of accuracy and bias avoidance but with 14% of the memory footprint and 5.5 times the speed.
大多数测序数据分析都是从将测序reads 与线性参考基因组比对开始的,但如果没有考虑遗传变异,就会导致参考偏差和下游结果的混淆。其他方法则用图等结构替代线性参考,这些结构可以包括遗传变异,但会带来巨大的计算开销。我们提出了参考流比对方法,该方法使用多个群体参考基因组来提高比对准确性并减少参考偏差。与图比对工具 vg 相比,参考流实现了相似的准确性和偏差避免水平,但内存占用仅为其 14%,速度则快了 5.5 倍。