R&D Headquarters, Petroleum Industry Health Organization Polyclinic, Eram Blvd, 7143837877, Shiraz, Iran.
Persian BayanGene Research and Training Center, Shiraz University of Medical Sciences, Shiraz, Iran.
Sci Rep. 2021 Jan 13;11(1):917. doi: 10.1038/s41598-020-79548-9.
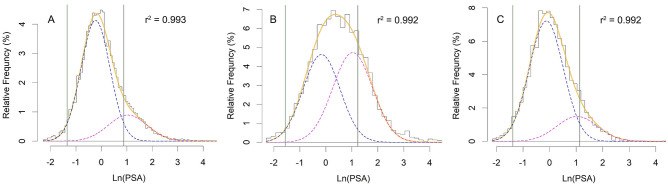
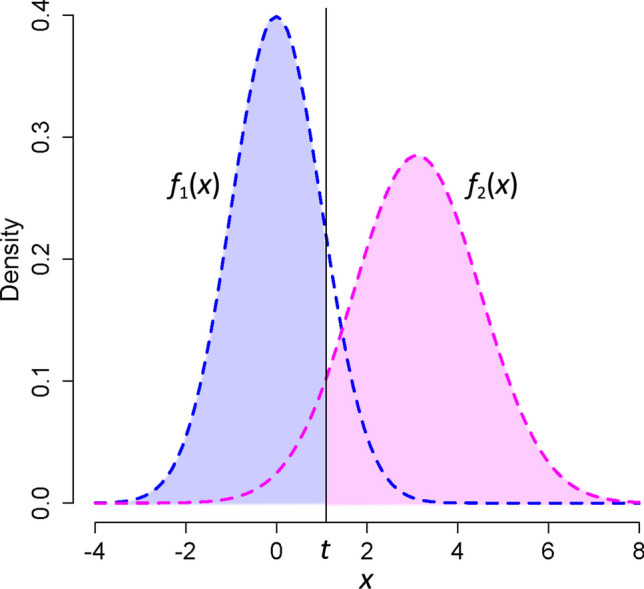
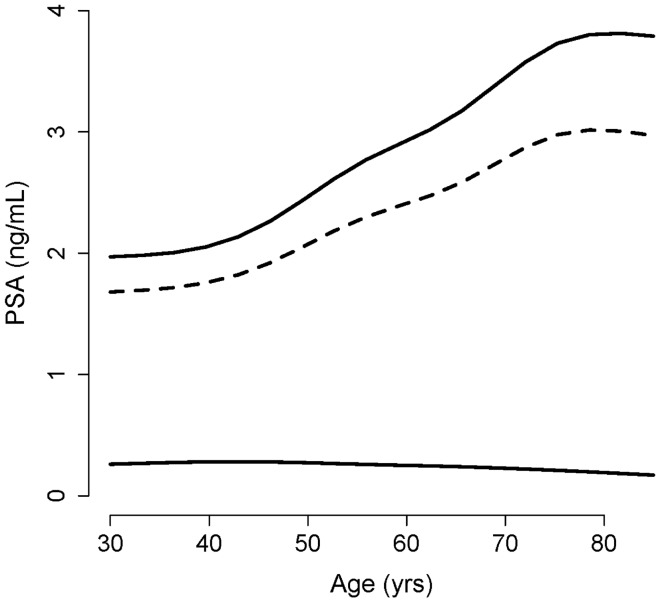
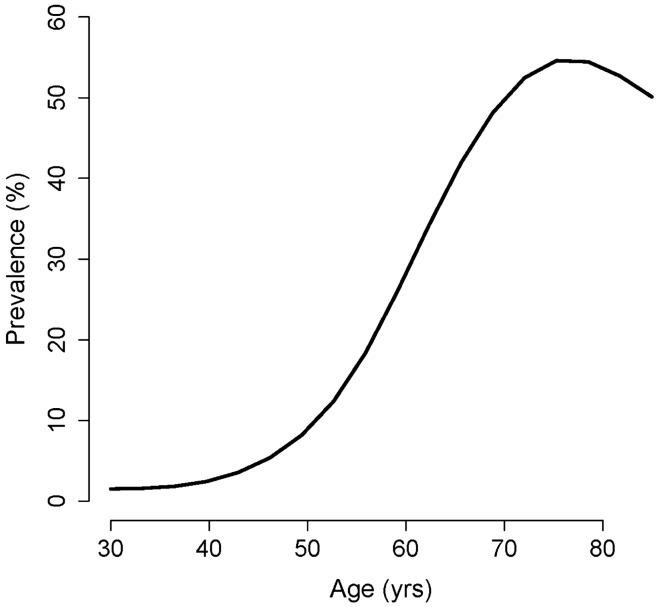
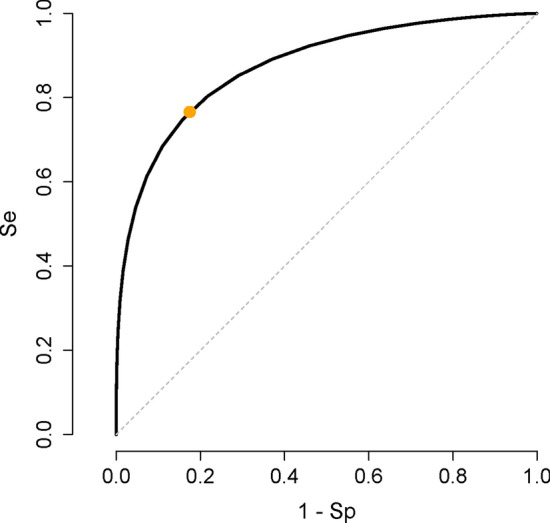
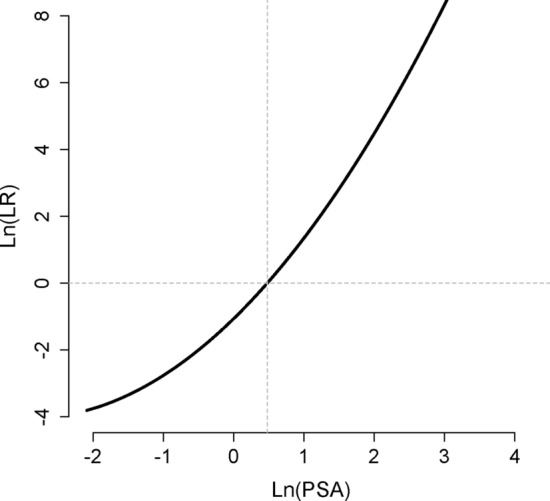
Classification tasks are a common challenge to every field of science. To correctly interpret the results provided by a classifier, we need to know the performance indices of the classifier including its sensitivity, specificity, the most appropriate cut-off value (for continuous classifiers), etc. Typically, several studies should be conducted to find all these indices. Herein, we show that they already exist, hidden in the distribution of the variable used to classify, and can readily be harvested. An educated guess about the distribution of the variable used to classify in each class would help us to decompose the frequency distribution of the variable in population into its components-the probability density function of the variable in each class. Based on the harvested parameters, we can then calculate the performance indices of the classifier. As a case study, we applied the technique to the relative frequency distribution of prostate-specific antigen, a biomarker commonly used in medicine for the diagnosis of prostate cancer. We used nonlinear curve fitting to decompose the variable relative frequency distribution into the probability density functions of the non-diseased and diseased people. The functions were then used to determine the performance indices of the classifier. Sensitivity, specificity, the most appropriate cut-off value, and likelihood ratios were calculated. The reference range of the biomarker and the prevalence of prostate cancer for various age groups were also calculated. The indices obtained were in good agreement with the values reported in previous studies. All these were done without being aware of the real health status of the individuals studied. The method is even applicable for conditions with no definite definitions (e.g., hypertension). We believe the method has a wide range of applications in many scientific fields.
分类任务是每个科学领域都面临的共同挑战。为了正确解释分类器提供的结果,我们需要了解分类器的性能指标,包括其灵敏度、特异性、最合适的截止值(对于连续分类器)等。通常需要进行多项研究来找到所有这些指标。在这里,我们表明它们已经存在于用于分类的变量的分布中,并且可以轻松地被挖掘出来。对每个类别中用于分类的变量的分布进行有根据的猜测,将有助于我们将总体中变量的频率分布分解为其组成部分——每个类别中变量的概率密度函数。基于收获的参数,我们可以计算分类器的性能指标。作为案例研究,我们将该技术应用于前列腺特异性抗原(PSA)的相对频率分布,这是医学中常用于诊断前列腺癌的一种生物标志物。我们使用非线性曲线拟合将变量相对频率分布分解为非患病和患病人群的概率密度函数。然后使用这些函数来确定分类器的性能指标。计算了灵敏度、特异性、最合适的截止值和似然比。还计算了生物标志物的参考范围和不同年龄组前列腺癌的患病率。获得的指标与之前研究报告的值吻合良好。所有这些都是在不知道研究个体真实健康状况的情况下完成的。该方法甚至适用于没有明确定义的情况(例如,高血压)。我们相信该方法在许多科学领域有广泛的应用。