Faculty of Computer Science, Dalhousie University, Halifax, NS, Canada.
Department of Psychiatry, Dalhousie University, Halifax, NS, Canada.
Sci Rep. 2021 Jan 13;11(1):1155. doi: 10.1038/s41598-020-80814-z.
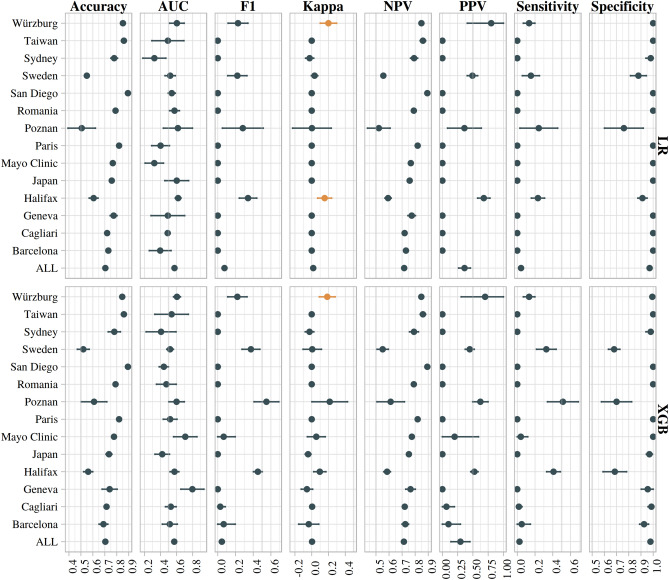
Predicting lithium response prior to treatment could both expedite therapy and avoid exposure to side effects. Since lithium responsiveness may be heritable, its predictability based on genomic data is of interest. We thus evaluate the degree to which lithium response can be predicted with a machine learning (ML) approach using genomic data. Using the largest existing genomic dataset in the lithium response literature (n = 2210 across 14 international sites; 29% responders), we evaluated the degree to which lithium response could be predicted based on 47,465 genotyped single nucleotide polymorphisms using a supervised ML approach. Under appropriate cross-validation procedures, lithium response could be predicted to above-chance levels in two constituent sites (Halifax, Cohen's kappa 0.15, 95% confidence interval, CI [0.07, 0.24]; and Würzburg, kappa 0.2 [0.1, 0.3]). Variants with shared importance in these models showed over-representation of postsynaptic membrane related genes. Lithium response was not predictable in the pooled dataset (kappa 0.02 [- 0.01, 0.04]), although non-trivial performance was achieved within a restricted dataset including only those patients followed prospectively (kappa 0.09 [0.04, 0.14]). Genomic classification of lithium response remains a promising but difficult task. Classification performance could potentially be improved by further harmonization of data collection procedures.
在治疗前预测锂反应既可以加快治疗速度,又可以避免副作用的发生。由于锂反应可能具有遗传性,因此基于基因组数据预测其可预测性是很有意义的。因此,我们使用机器学习 (ML) 方法评估使用基因组数据预测锂反应的程度。
使用锂反应文献中最大的现有基因组数据集(来自 14 个国际站点的 2210 名患者,29%为反应者),我们评估了基于 47465 个已测序的单核苷酸多态性(SNP)使用监督机器学习方法预测锂反应的程度。在适当的交叉验证程序下,在两个组成站点(哈利法克斯,科恩氏 κ 值为 0.15,95%置信区间为 [0.07, 0.24];和维尔茨堡,κ 值为 0.2 [0.1, 0.3])可以预测锂反应达到高于随机水平。在这些模型中具有共同重要性的变体表现出与突触后膜相关基因的过度表达。虽然在仅包括前瞻性随访患者的受限数据集内实现了非平凡的性能(κ 值为 0.09 [0.04, 0.14]),但在汇总数据集(κ 值为 0.02 [-0.01, 0.04])中锂反应无法预测。
基因组分类锂反应仍然是一项很有前途但具有挑战性的任务。通过进一步协调数据收集程序,分类性能可能会得到提高。