Sabah Ali, Tiun Sabrina, Sani Nor Samsiah, Ayob Masri, Taha Adil Yaseen
Center for Artificial Intelligence Technology (CAIT), Faculty of Information Science and Technology, Universiti Kebangsaan Malaysia, Bangi, Selangor, Malaysia.
PLoS One. 2021 Jan 15;16(1):e0245264. doi: 10.1371/journal.pone.0245264. eCollection 2021.
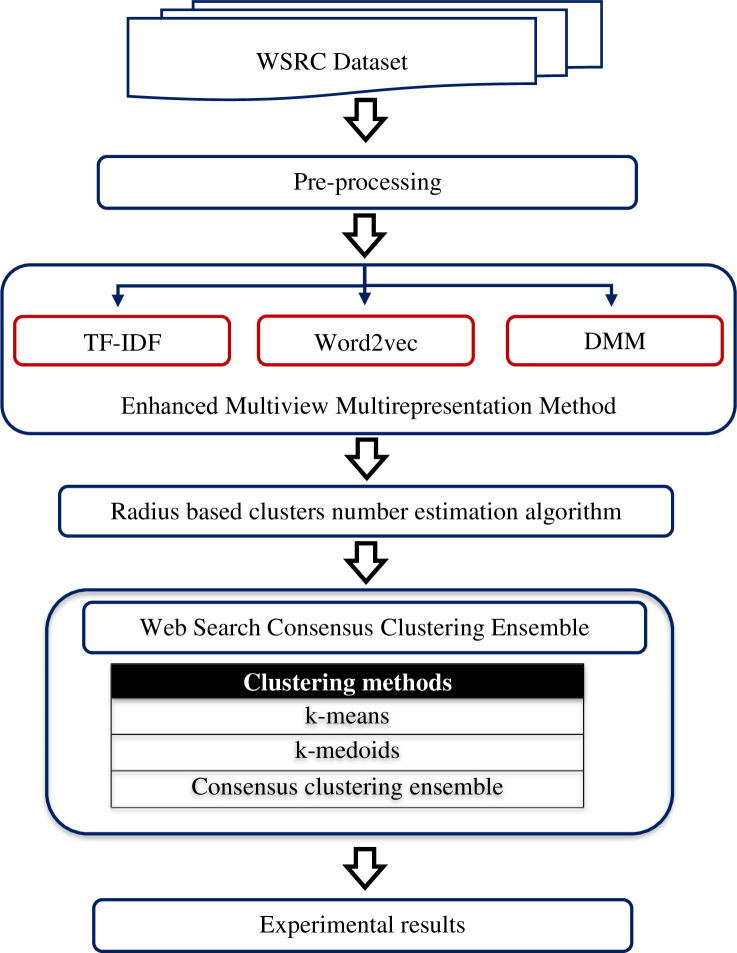
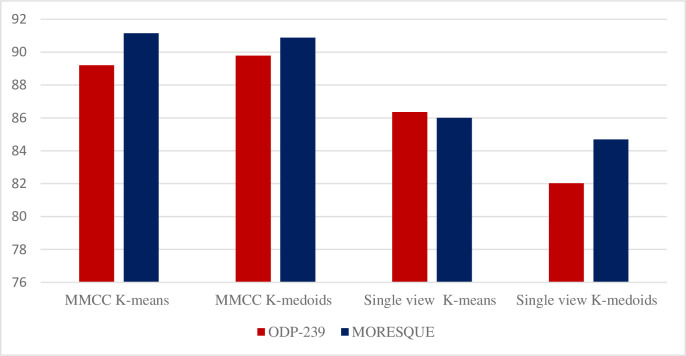
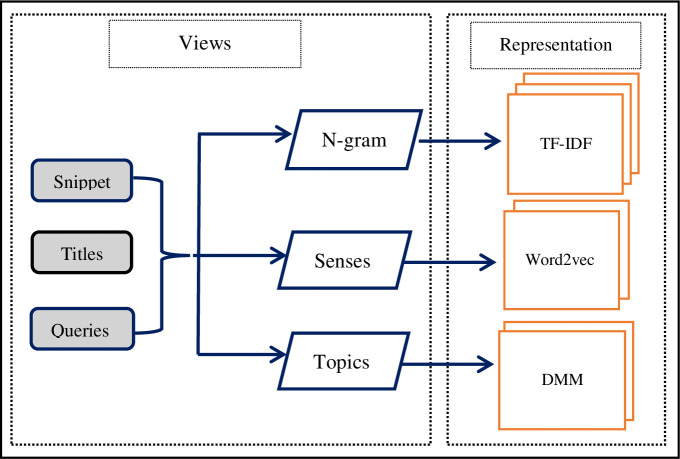
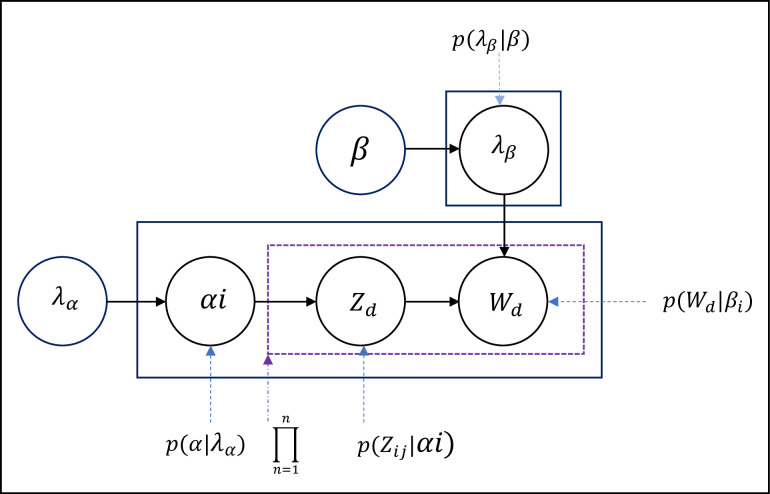
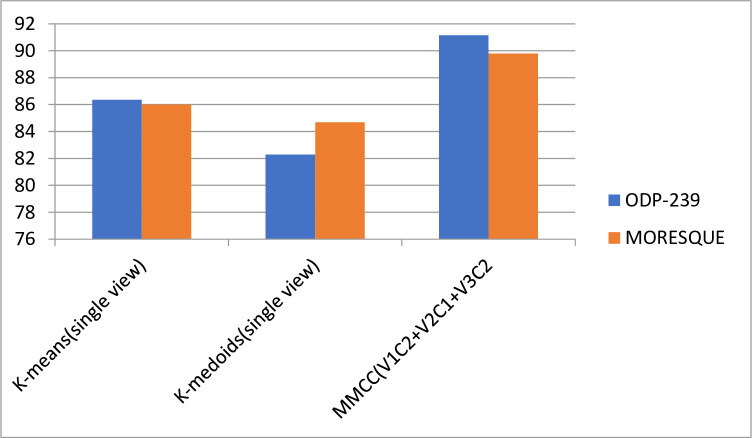
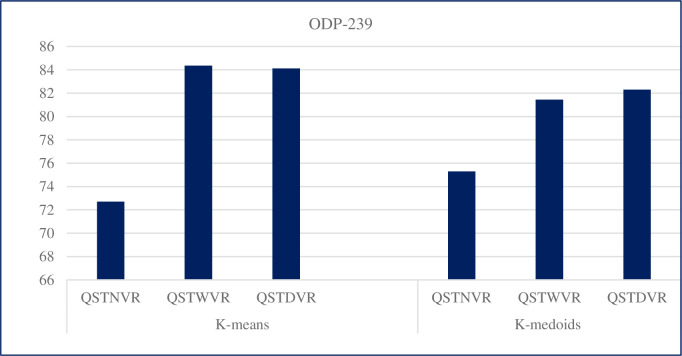
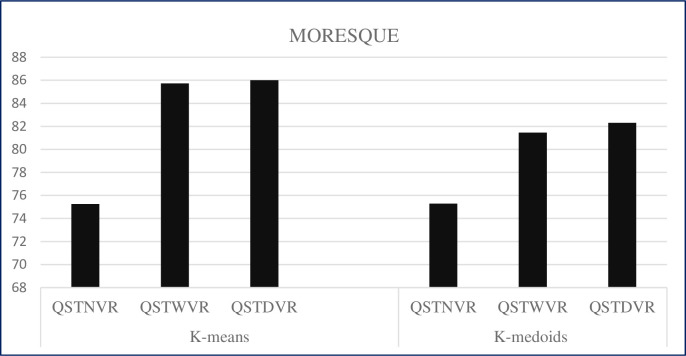
Existing text clustering methods utilize only one representation at a time (single view), whereas multiple views can represent documents. The multiview multirepresentation method enhances clustering quality. Moreover, existing clustering methods that utilize more than one representation at a time (multiview) use representation with the same nature. Hence, using multiple views that represent data in a different representation with clustering methods is reasonable to create a diverse set of candidate clustering solutions. On this basis, an effective dynamic clustering method must consider combining multiple views of data including semantic view, lexical view (word weighting), and topic view as well as the number of clusters. The main goal of this study is to develop a new method that can improve the performance of web search result clustering (WSRC). An enhanced multiview multirepresentation consensus clustering ensemble (MMCC) method is proposed to create a set of diverse candidate solutions and select a high-quality overlapping cluster. The overlapping clusters are obtained from the candidate solutions created by different clustering methods. The framework to develop the proposed MMCC includes numerous stages: (1) acquiring the standard datasets (MORESQUE and Open Directory Project-239), which are used to validate search result clustering algorithms, (2) preprocessing the dataset, (3) applying multiview multirepresentation clustering models, (4) using the radius-based cluster number estimation algorithm, and (5) employing the consensus clustering ensemble method. Results show an improvement in clustering methods when multiview multirepresentation is used. More importantly, the proposed MMCC model improves the overall performance of WSRC compared with all single-view clustering models.
现有的文本聚类方法一次仅使用一种表示形式(单视图),而多个视图可以表示文档。多视图多表示方法可提高聚类质量。此外,现有的一次使用多种表示形式(多视图)的聚类方法使用的是性质相同的表示形式。因此,将以不同表示形式表示数据的多个视图与聚类方法结合使用,以创建一组多样化的候选聚类解决方案是合理的。在此基础上,一种有效的动态聚类方法必须考虑结合数据的多个视图,包括语义视图、词汇视图(词加权)和主题视图以及聚类数量。本研究的主要目标是开发一种能够提高网络搜索结果聚类(WSRC)性能的新方法。提出了一种增强的多视图多表示共识聚类集成(MMCC)方法,以创建一组多样化的候选解决方案并选择高质量的重叠聚类。重叠聚类是从由不同聚类方法创建的候选解决方案中获得的。开发所提出的MMCC的框架包括多个阶段:(1)获取标准数据集(MORESQUE和开放目录项目 - 239),用于验证搜索结果聚类算法,(2)对数据集进行预处理,(3)应用多视图多表示聚类模型,(4)使用基于半径的聚类数量估计算法,以及(5)采用共识聚类集成方法。结果表明,使用多视图多表示时聚类方法有改进。更重要的是,与所有单视图聚类模型相比,所提出的MMCC模型提高了WSRC的整体性能。