School of Computer Science and Technology, College of Intelligence and Computing, Tianjin University, Tianjin, China.
School of Electronic and Information Engineering, Suzhou University of Science and Technology, Suzhou, China.
BMC Genomics. 2021 Jan 15;22(1):56. doi: 10.1186/s12864-020-07347-7.
Biological functions of biomolecules rely on the cellular compartments where they are located in cells. Importantly, RNAs are assigned in specific locations of a cell, enabling the cell to implement diverse biochemical processes in the way of concurrency. However, lots of existing RNA subcellular localization classifiers only solve the problem of single-label classification. It is of great practical significance to expand RNA subcellular localization into multi-label classification problem.
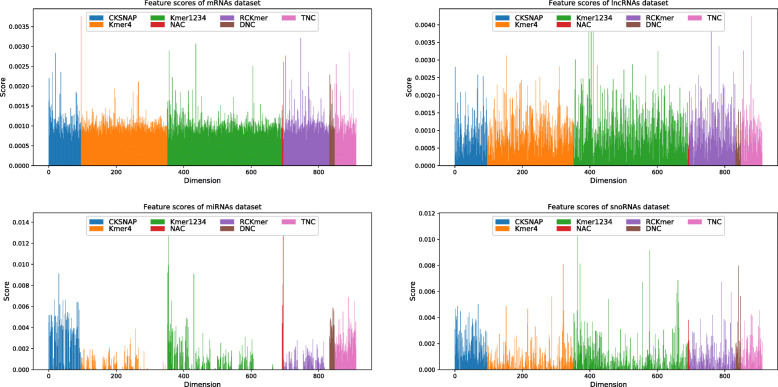
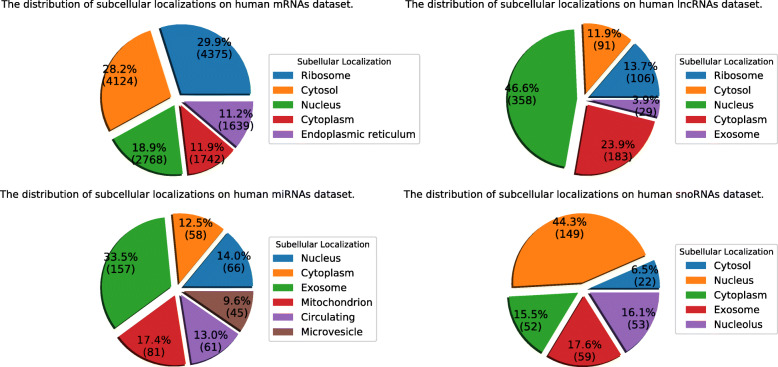
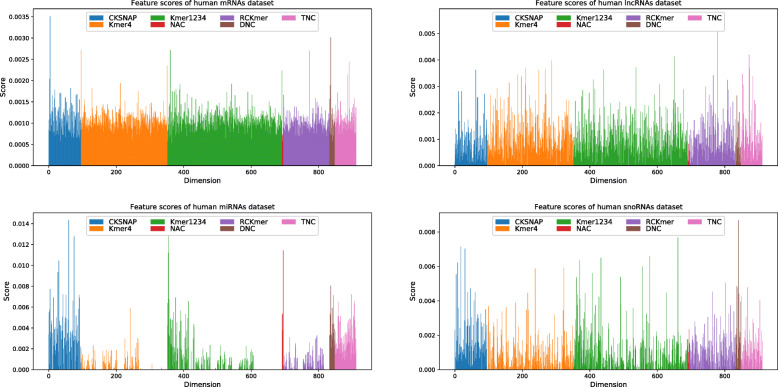
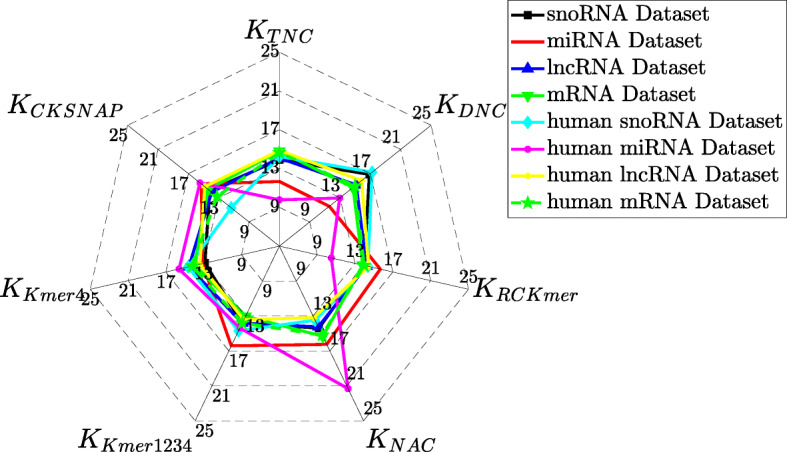
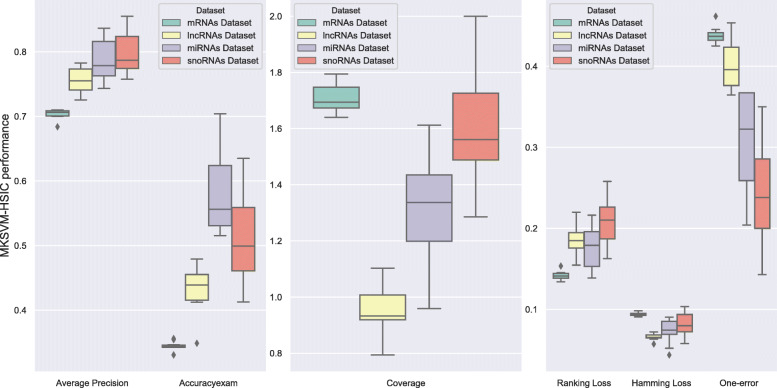
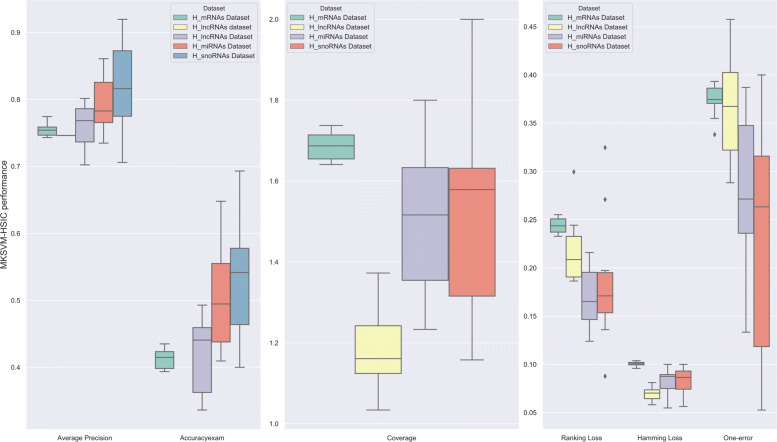
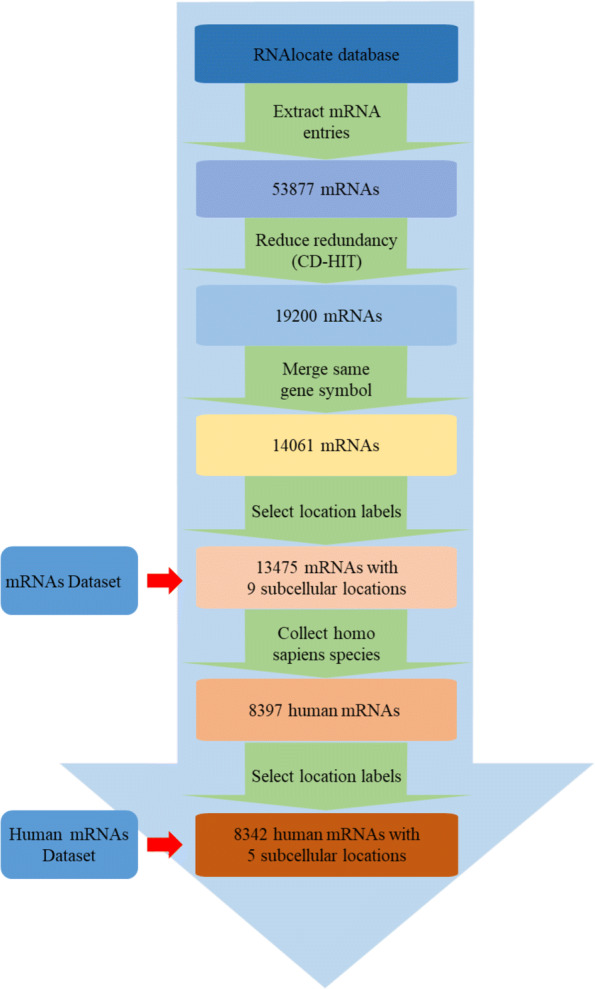
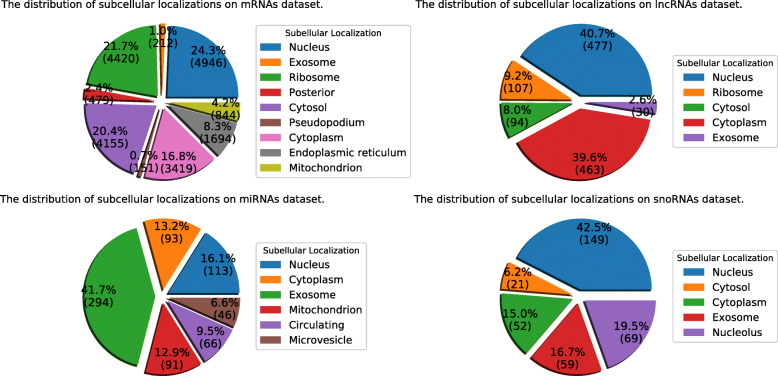
In this study, we extract multi-label classification datasets about RNA-associated subcellular localizations on various types of RNAs, and then construct subcellular localization datasets on four RNA categories. In order to study Homo sapiens, we further establish human RNA subcellular localization datasets. Furthermore, we utilize different nucleotide property composition models to extract effective features to adequately represent the important information of nucleotide sequences. In the most critical part, we achieve a major challenge that is to fuse the multivariate information through multiple kernel learning based on Hilbert-Schmidt independence criterion. The optimal combined kernel can be put into an integration support vector machine model for identifying multi-label RNA subcellular localizations. Our method obtained excellent results of 0.703, 0.757, 0.787, and 0.800, respectively on four RNA data sets on average precision.
To be specific, our novel method performs outstanding rather than other prediction tools on novel benchmark datasets. Moreover, we establish user-friendly web server with the implementation of our method.
生物分子的生物学功能依赖于它们在细胞中所处的细胞区室。重要的是,RNA 被分配到细胞的特定位置,使细胞能够以并发性的方式实施多种生化过程。然而,许多现有的 RNA 亚细胞定位分类器仅解决了单标签分类的问题。将 RNA 亚细胞定位扩展到多标签分类问题具有重要的实际意义。
在这项研究中,我们提取了关于各种类型 RNA 相关亚细胞定位的多标签分类数据集,然后构建了四个 RNA 类别的亚细胞定位数据集。为了研究智人,我们进一步建立了人类 RNA 亚细胞定位数据集。此外,我们利用不同的核苷酸特性组成模型来提取有效特征,以充分表示核苷酸序列的重要信息。在最关键的部分,我们通过基于 Hilbert-Schmidt 独立性准则的多核学习来实现融合多元信息的重大挑战。最优组合核可用于集成支持向量机模型,以识别多标签 RNA 亚细胞定位。我们的方法在四个 RNA 数据集上的平均精度分别达到了 0.703、0.757、0.787 和 0.800。
具体来说,我们的新方法在新的基准数据集上的表现明显优于其他预测工具。此外,我们还建立了一个用户友好的网络服务器,实现了我们的方法。