Computational Genomics, IBM T.J. Watson Research Center, Yorktown Heights, NY, USA.
Computer Science Department, Purdue University, West Lafayette, IN, USA.
Mol Biol Evol. 2021 May 4;38(5):1809-1819. doi: 10.1093/molbev/msaa321.
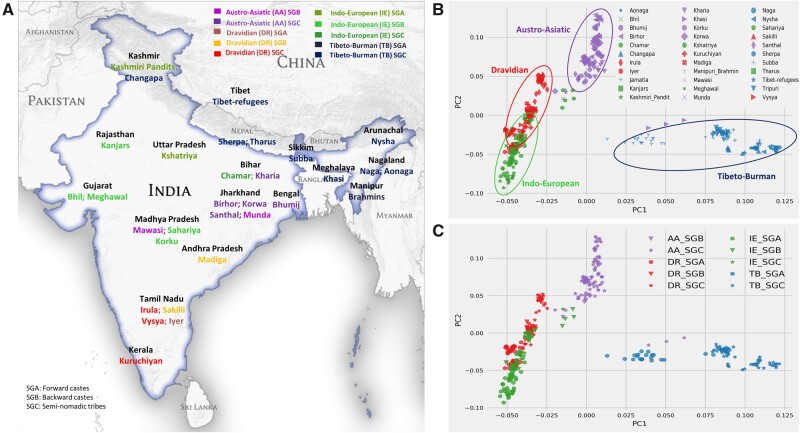
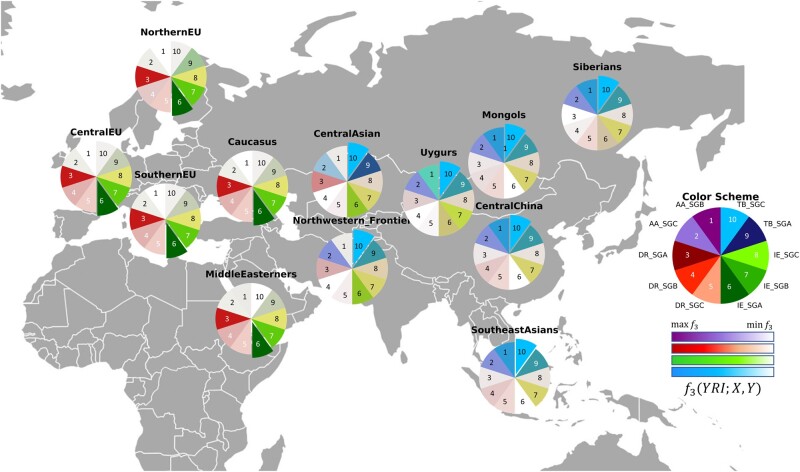
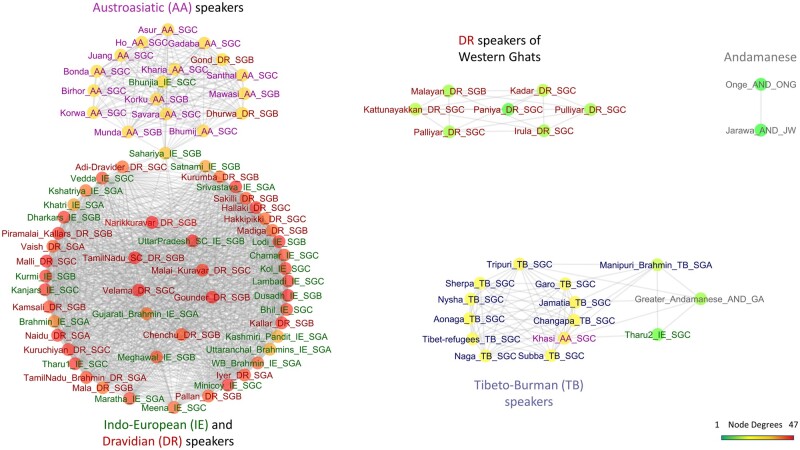
India represents an intricate tapestry of population substructure shaped by geography, language, culture, and social stratification. Although geography closely correlates with genetic structure in other parts of the world, the strict endogamy imposed by the Indian caste system and the large number of spoken languages add further levels of complexity to understand Indian population structure. To date, no study has attempted to model and evaluate how these factors have interacted to shape the patterns of genetic diversity within India. We merged all publicly available data from the Indian subcontinent into a data set of 891 individuals from 90 well-defined groups. Bringing together geography, genetics, and demographic factors, we developed Correlation Optimization of Genetics and Geodemographics to build a model that explains the observed population genetic substructure. We show that shared language along with social structure have been the most powerful forces in creating paths of gene flow in the subcontinent. Furthermore, we discover the ethnic groups that best capture the diverse genetic substructure using a ridge leverage score statistic. Integrating data from India with a data set of additional 1,323 individuals from 50 Eurasian populations, we find that Indo-European and Dravidian speakers of India show shared genetic drift with Europeans, whereas the Tibeto-Burman speaking tribal groups have maximum shared genetic drift with East Asians.
印度是一个人口结构复杂的国家,其人口结构受到地理、语言、文化和社会分层等多种因素的影响。尽管地理因素与世界其他地区的遗传结构密切相关,但印度种姓制度所强加的严格内婚制以及众多的语言使用情况进一步增加了理解印度人口结构的复杂性。迄今为止,尚无研究试图对这些因素如何相互作用以塑造印度内部遗传多样性模式进行建模和评估。我们将来自印度次大陆的所有公开可用数据合并到一个包含 891 个人的数据集中,这些人来自 90 个明确界定的群体。我们综合考虑了地理、遗传和人口统计学因素,开发了遗传与地理人口统计学相关性优化(Correlation Optimization of Genetics and Geodemographics),以构建一个可以解释观察到的人口遗传亚结构的模型。我们发现,共同的语言以及社会结构是在次大陆创造基因流路径的最强大力量。此外,我们还使用脊杠杆得分统计量发现了最能捕捉到不同遗传亚结构的族群。我们将来自印度的数据与来自 50 个欧亚人群的另外 1323 个人的数据进行整合,发现印度的印欧语系和达罗毗荼语系使用者与欧洲人表现出共同的遗传漂变,而讲藏缅语的部落群体与东亚人表现出最大的共同遗传漂变。