Zefat Academic College, Zefat, Israel.
Department of Computer Engineering, Faculty of Engineering, Abdullah Gul University, Kayseri, Turkey.
F1000Res. 2020 Oct 19;9:1255. doi: 10.12688/f1000research.26880.2. eCollection 2020.
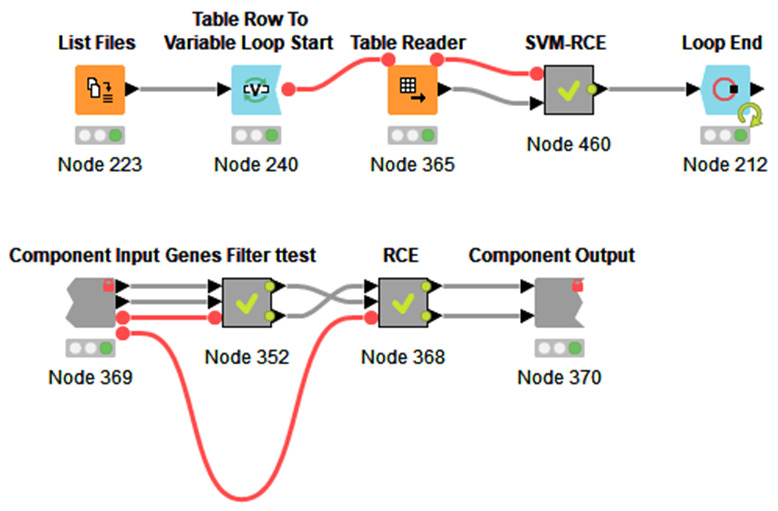
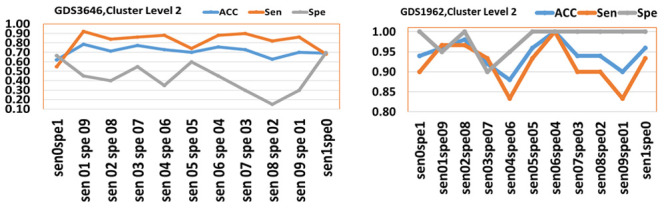
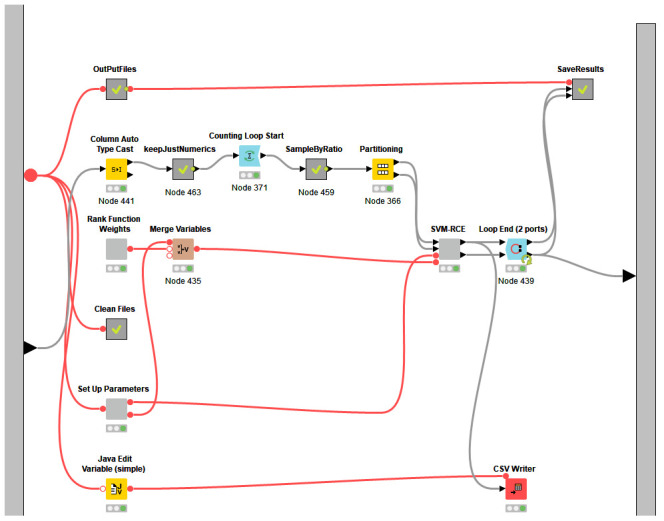
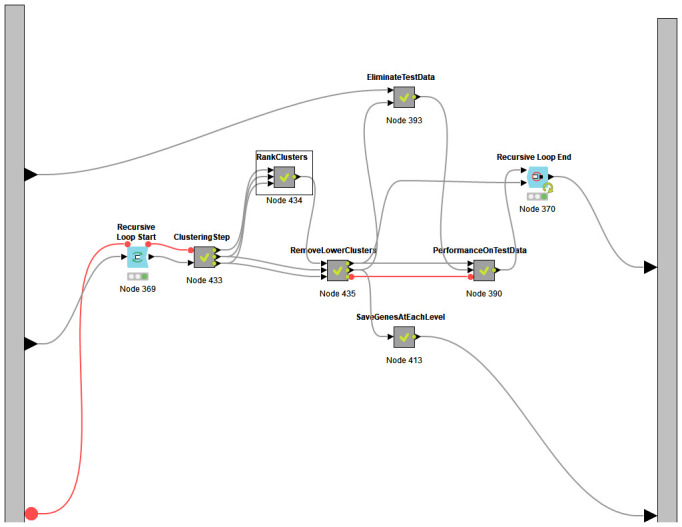
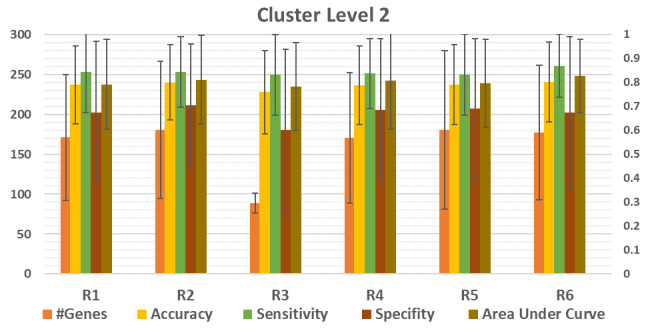
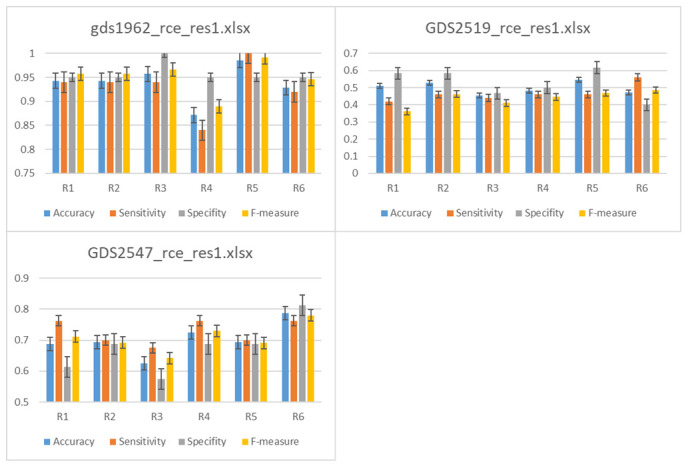
In our earlier study, we proposed a novel feature selection approach, Recursive Cluster Elimination with Support Vector Machines (SVM-RCE) and implemented this approach in Matlab. Interest in this approach has grown over time and several researchers have incorporated SVM-RCE into their studies, resulting in a substantial number of scientific publications. This increased interest encouraged us to reconsider how feature selection, particularly in biological datasets, can benefit from considering the relationships of those genes in the selection process, this led to our development of SVM-RCE-R. SVM-RCE-R, further enhances the capabilities of SVM-RCE by the addition of a novel user specified ranking function. This ranking function enables the user to stipulate the weights of the accuracy, sensitivity, specificity, f-measure, area under the curve and the precision in the ranking function This flexibility allows the user to select for greater sensitivity or greater specificity as needed for a specific project. The usefulness of SVM-RCE-R is further supported by development of the maTE tool which uses a similar approach to identify microRNA (miRNA) targets. We have also now implemented the SVM-RCE-R algorithm in Knime in order to make it easier to applyThe use of SVM-RCE-R in Knime is simple and intuitive and allows researchers to immediately begin their analysis without having to consult an information technology specialist. The input for the Knime implemented tool is an EXCEL file (or text or CSV) with a simple structure and the output is also an EXCEL file. The Knime version also incorporates new features not available in SVM-RCE. The results show that the inclusion of the ranking function has a significant impact on the performance of SVM-RCE-R. Some of the clusters that achieve high scores for a specified ranking can also have high scores in other metrics.
在我们之前的研究中,我们提出了一种新的特征选择方法,即递归聚类消除支持向量机(SVM-RCE),并在 Matlab 中实现了这种方法。随着时间的推移,人们对这种方法的兴趣越来越大,许多研究人员已经将 SVM-RCE 纳入他们的研究中,这导致了大量的科学出版物。这种日益增长的兴趣促使我们重新考虑如何从选择过程中考虑这些基因的关系中受益,这导致了我们开发 SVM-RCE-R。SVM-RCE-R 通过添加一个新的用户指定的排序函数,进一步增强了 SVM-RCE 的功能。该排序函数允许用户指定准确性、灵敏度、特异性、f 度量、曲线下面积和排序函数中的精度的权重。这种灵活性允许用户根据特定项目的需要选择更大的灵敏度或特异性。SVM-RCE-R 的有用性还得到了 maTE 工具的开发的支持,该工具使用类似的方法来识别 microRNA(miRNA)靶标。我们还在 Knime 中实现了 SVM-RCE-R 算法,以便更易于应用。在 Knime 中使用 SVM-RCE-R 非常简单直观,允许研究人员无需咨询信息技术专家即可立即开始分析。Knime 实现工具的输入是一个具有简单结构的 EXCEL 文件(或文本或 CSV),输出也是一个 EXCEL 文件。Knime 版本还包含 SVM-RCE 中不可用的新功能。结果表明,排序函数的包含对 SVM-RCE-R 的性能有显著影响。对于指定的排序,一些获得高分的聚类也可以在其他指标中获得高分。