Martinsen Andreas B, Lekkas Anastasios M, Gros Sébastien, Glomsrud Jon Arne, Pedersen Tom Arne
Department of Engineering Cybernetics, Norwegian University of Science and Technology, Trondheim, Norway.
Centre for Autonomous Marine Operations and Systems, Norwegian University of Science and Technology, Trondheim, Norway.
Front Robot AI. 2020 Mar 20;7:32. doi: 10.3389/frobt.2020.00032. eCollection 2020.
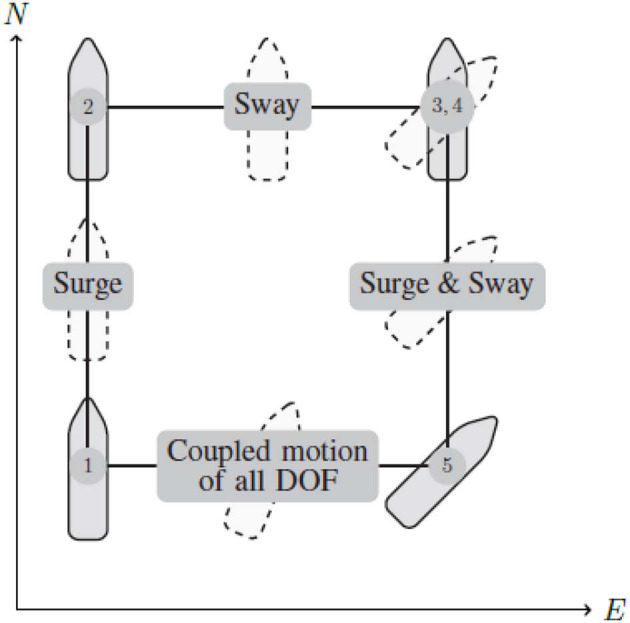
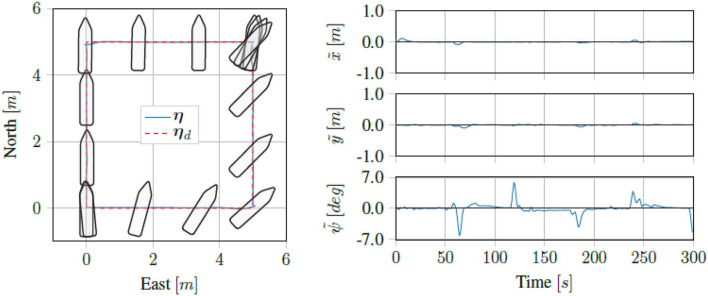
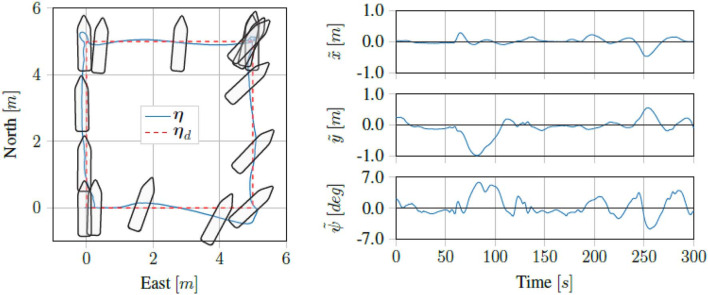
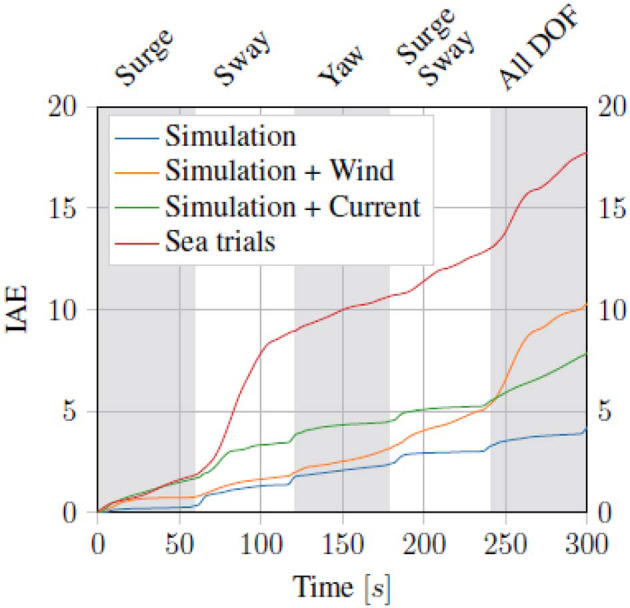
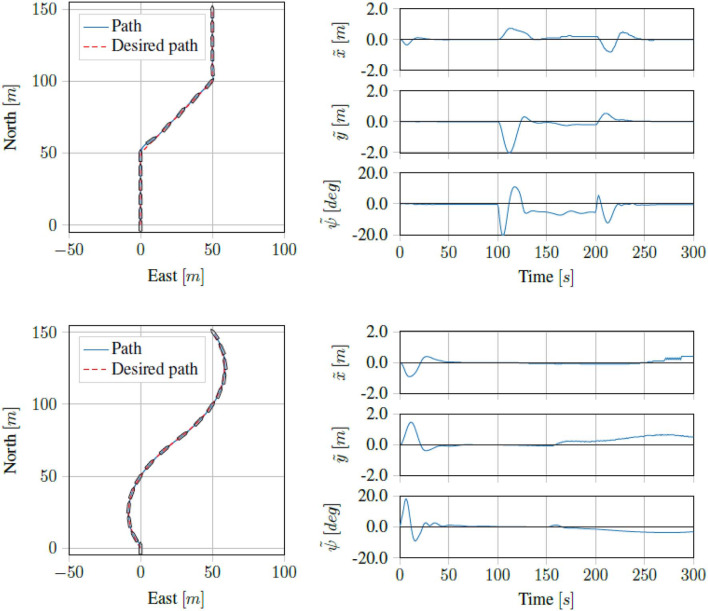
We present a reinforcement learning-based (RL) control scheme for trajectory tracking of fully-actuated surface vessels. The proposed method learns online both a model-based feedforward controller, as well an optimizing feedback policy in order to follow a desired trajectory under the influence of environmental forces. The method's efficiency is evaluated via simulations and sea trials, with the unmanned surface vehicle (USV) performing three different tracking tasks: The four corner DP test, straight-path tracking and curved-path tracking. The results demonstrate the method's ability to accomplish the control objectives and a good agreement between the performance achieved in the Revolt Digital Twin and the sea trials. Finally, we include an section with considerations about assurance for RL-based methods and where our approach stands in terms of the main challenges.
我们提出了一种基于强化学习(RL)的控制方案,用于全驱动水面舰艇的轨迹跟踪。所提出的方法在线学习基于模型的前馈控制器以及优化反馈策略,以便在环境力的影响下跟踪期望轨迹。通过仿真和海上试验评估了该方法的效率,无人水面舰艇(USV)执行了三种不同的跟踪任务:四角动力定位测试、直线路径跟踪和曲线路径跟踪。结果证明了该方法实现控制目标的能力,以及在Revolt数字孪生中实现的性能与海上试验之间的良好一致性。最后,我们纳入了一个部分,其中考虑了基于RL方法的保证,以及我们的方法在主要挑战方面的立场。