Padrao Paulo, Fuentes Jose, Bobadilla Leonardo, Smith Ryan N
Knight Foundation School of Computing and Information Sciences, Florida International University, Miami, FL, United States.
Institute for Environment, Florida International University, Miami, FL, United States.
Front Robot AI. 2022 Sep 5;9:878246. doi: 10.3389/frobt.2022.878246. eCollection 2022.
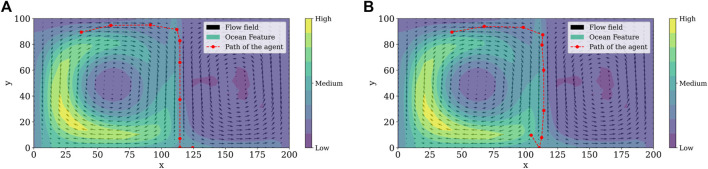
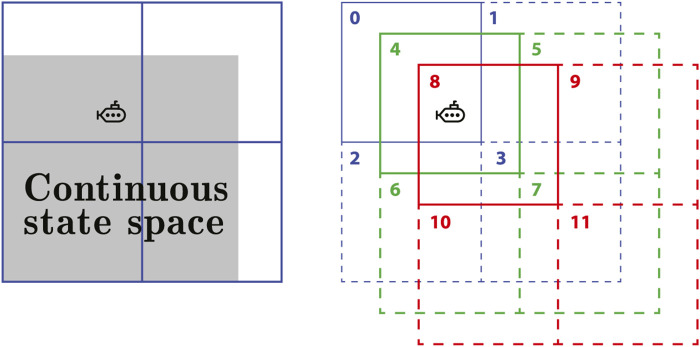
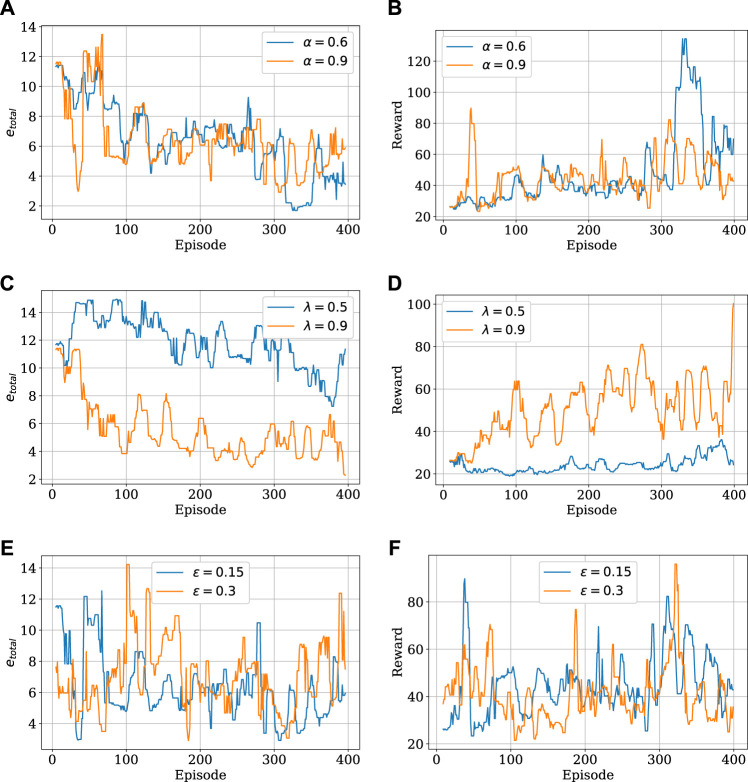
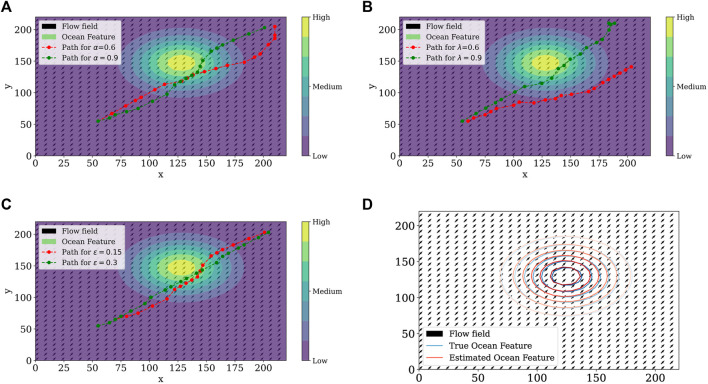
Prediction and estimation of phenomena of interest in aquatic environments are challenging since they present complex spatio-temporal dynamics. Over the past few decades, advances in machine learning and data processing contributed to ocean exploration and sampling using autonomous robots. In this work, we formulate a reinforcement learning framework to estimate spatio-temporal fields modeled by partial differential equations. The proposed framework addresses problems of the classic methods regarding the sampling process to determine the path to be used by the agent to collect samples. Simulation results demonstrate the applicability of our approach and show that the error at the end of the learning process is close to the expected error given by the fitting process due to added noise.
预测和估计水生环境中感兴趣的现象具有挑战性,因为它们呈现出复杂的时空动态。在过去几十年中,机器学习和数据处理的进步推动了使用自主机器人进行海洋探索和采样。在这项工作中,我们制定了一个强化学习框架,以估计由偏微分方程建模的时空场。所提出的框架解决了经典方法在采样过程中存在的问题,即确定智能体用于收集样本的路径。仿真结果证明了我们方法的适用性,并表明学习过程结束时的误差接近由于添加噪声而由拟合过程给出的预期误差。