Hangl Simon, Dunjko Vedran, Briegel Hans J, Piater Justus
Intelligent and Interactive Systems, Department of Informatics, University of Innsbruck, Innsbruck, Austria.
LIACS, Leiden University, Leiden, Netherlands.
Front Robot AI. 2020 Apr 3;7:42. doi: 10.3389/frobt.2020.00042. eCollection 2020.
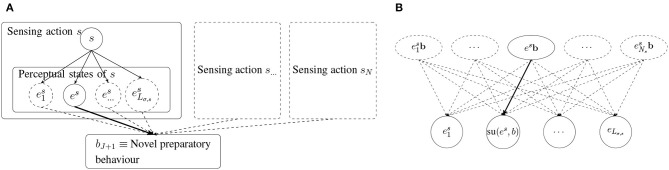
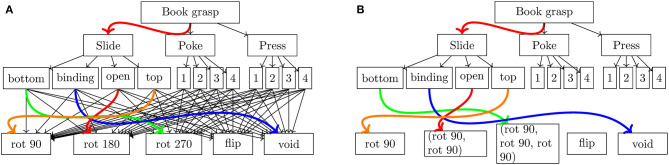
We consider the problem of autonomous acquisition of manipulation skills where problem-solving strategies are initially available only for a narrow range of situations. We propose to extend the range of solvable situations by autonomous play with the object. By applying previously-trained skills and behaviors, the robot learns how to prepare situations for which a successful strategy is already known. The information gathered during autonomous play is additionally used to train an environment model. This model is exploited for active learning and the generation of novel preparatory behaviors compositions. We apply our approach to a wide range of different manipulation tasks, e.g., book grasping, grasping of objects of different sizes by selecting different grasping strategies, placement on shelves, and tower disassembly. We show that the composite behavior generation mechanism enables the robot to solve previously-unsolvable tasks, e.g., tower disassembly. We use success statistics gained during real-world experiments to simulate the convergence behavior of our system. Simulation experiments show that the learning speed can be improved by around 30% by using active learning.
我们考虑自主获取操作技能的问题,其中解决问题的策略最初仅适用于狭窄范围的情况。我们建议通过与物体自主玩耍来扩展可解决情况的范围。通过应用先前训练的技能和行为,机器人学习如何为已经知道成功策略的情况做好准备。在自主玩耍期间收集的信息还用于训练环境模型。该模型用于主动学习和生成新颖的准备行为组合。我们将我们的方法应用于广泛的不同操作任务,例如书本抓取、通过选择不同的抓取策略抓取不同尺寸的物体、放置在架子上以及塔架拆卸。我们表明,复合行为生成机制使机器人能够解决以前无法解决的任务,例如塔架拆卸。我们使用在实际实验中获得的成功统计数据来模拟我们系统的收敛行为。仿真实验表明,通过使用主动学习,学习速度可以提高约30%。