Melnikov Alexey A, Makmal Adi, Dunjko Vedran, Briegel Hans J
Institute for Theoretical Physics, University of Innsbruck, Technikerstraße 21a, 6020, Innsbruck, Austria.
Institute for Quantum Optics and Quantum Information, Austrian Academy of Sciences, Technikerstraße 21a, 6020, Innsbruck, Austria.
Sci Rep. 2017 Oct 31;7(1):14430. doi: 10.1038/s41598-017-14740-y.
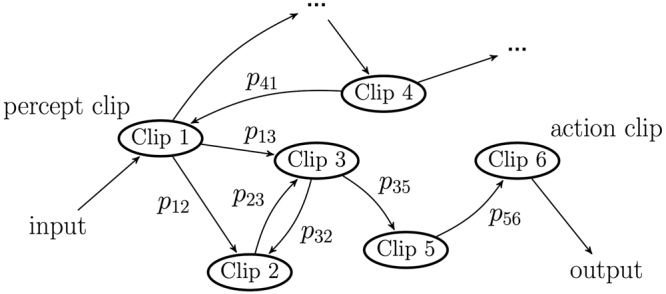
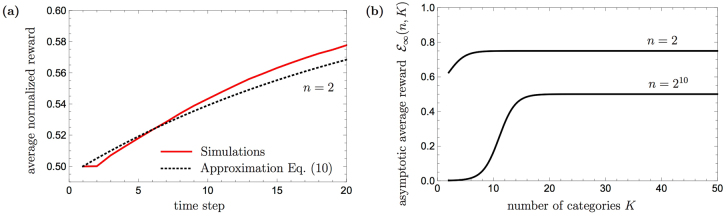
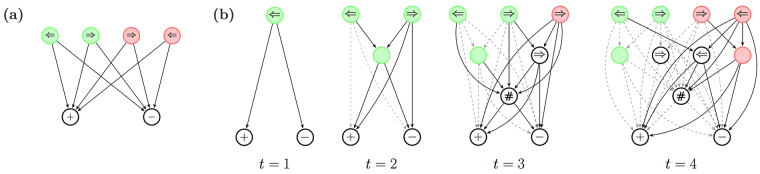
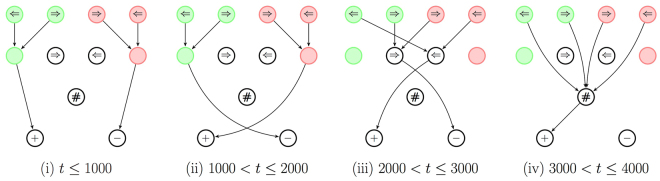
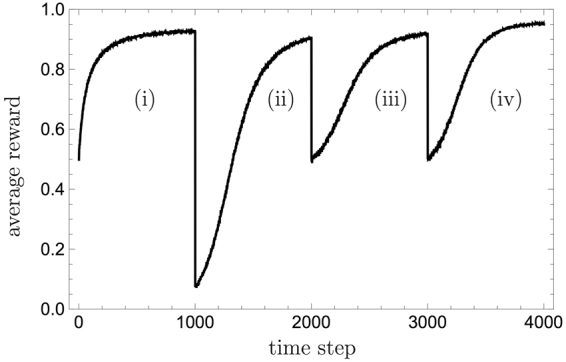
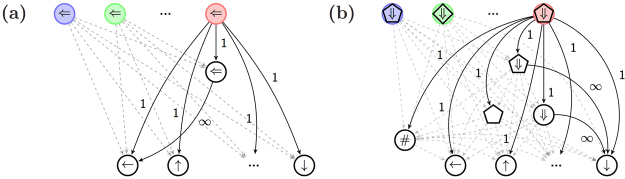
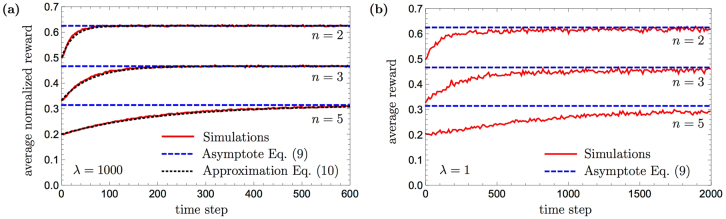
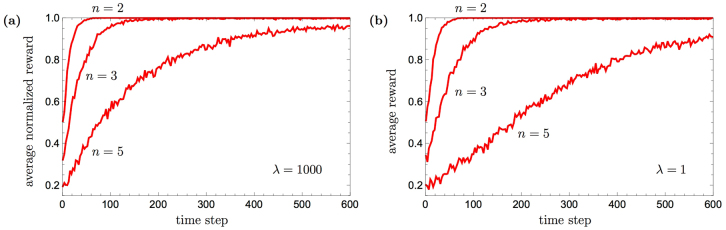
The ability to generalize is an important feature of any intelligent agent. Not only because it may allow the agent to cope with large amounts of data, but also because in some environments, an agent with no generalization capabilities cannot learn. In this work we outline several criteria for generalization, and present a dynamic and autonomous machinery that enables projective simulation agents to meaningfully generalize. Projective simulation, a novel, physical approach to artificial intelligence, was recently shown to perform well in standard reinforcement learning problems, with applications in advanced robotics as well as quantum experiments. Both the basic projective simulation model and the presented generalization machinery are based on very simple principles. This allows us to provide a full analytical analysis of the agent's performance and to illustrate the benefit the agent gains by generalizing. Specifically, we show that already in basic (but extreme) environments, learning without generalization may be impossible, and demonstrate how the presented generalization machinery enables the projective simulation agent to learn.
泛化能力是任何智能体的一个重要特征。这不仅是因为它可能使智能体能够处理大量数据,还因为在某些环境中,没有泛化能力的智能体无法学习。在这项工作中,我们概述了几个泛化标准,并提出了一种动态自主机制,使投影模拟智能体能够进行有意义的泛化。投影模拟是一种新颖的人工智能物理方法,最近被证明在标准强化学习问题中表现良好,可应用于先进机器人技术以及量子实验。基本的投影模拟模型和所提出的泛化机制都基于非常简单的原理。这使我们能够对智能体的性能进行全面的分析,并说明智能体通过泛化所获得的益处。具体而言,我们表明,即使在基本(但极端)环境中,没有泛化的学习可能是不可能的,并展示了所提出的泛化机制如何使投影模拟智能体能够学习。