Low Daniel M, Rao Vishwanatha, Randolph Gregory, Song Phillip C, Ghosh Satrajit S
Program in Speech and Hearing Bioscience and Technology, Harvard Medical School, Boston, MA, USA.
McGovern Institute for Brain Research, MIT, Cambridge, MA, USA.
medRxiv. 2024 Mar 20:2020.11.23.20235945. doi: 10.1101/2020.11.23.20235945.
Detecting voice disorders from voice recordings could allow for frequent, remote, and low-cost screening before costly clinical visits and a more invasive laryngoscopy examination. Our goals were to detect unilateral vocal fold paralysis (UVFP) from voice recordings using machine learning, to identify which acoustic variables were important for prediction to increase trust, and to determine model performance relative to clinician performance.
Patients with confirmed UVFP through endoscopic examination (N=77) and controls with normal voices matched for age and sex (N=77) were included. Voice samples were elicited by reading the Rainbow Passage and sustaining phonation of the vowel "a". Four machine learning models of differing complexity were used. SHapley Additive explanations (SHAP) was used to identify important features.
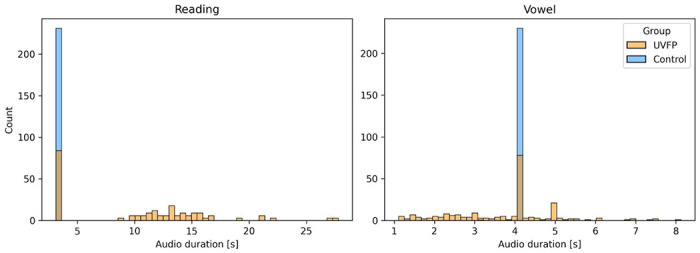
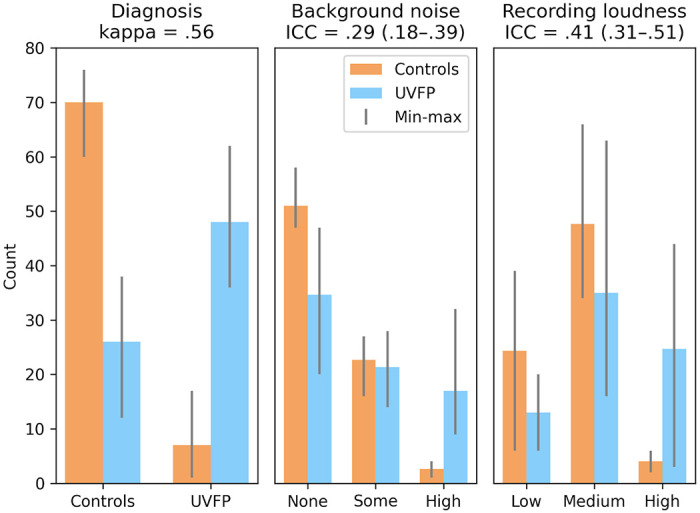
The highest median bootstrapped ROC AUC score was 0.87 and beat clinician's performance (range: 0.74 - 0.81) based on the recordings. Recording durations were different between UVFP recordings and controls due to how that data was originally processed when storing, which we can show can classify both groups. And counterintuitively, many UVFP recordings had higher intensity than controls, when UVFP patients tend to have weaker voices, revealing a dataset-specific bias which we mitigate in an additional analysis.
We demonstrate that recording biases in audio duration and intensity created dataset-specific differences between patients and controls, which models used to improve classification. Furthermore, clinician's ratings provide further evidence that patients were over-projecting their voices and being recorded at a higher amplitude signal than controls. Interestingly, after matching audio duration and removing variables associated with intensity in order to mitigate the biases, the models were able to achieve a similar high performance. We provide a set of recommendations to avoid bias when building and evaluating machine learning models for screening in laryngology.
通过语音记录检测语音障碍可以在进行昂贵的临床就诊和侵入性更强的喉镜检查之前,实现频繁、远程且低成本的筛查。我们的目标是使用机器学习从语音记录中检测单侧声带麻痹(UVFP),确定哪些声学变量对预测很重要以增强可信度,并确定模型相对于临床医生表现的性能。
纳入经内镜检查确诊为UVFP的患者(N = 77)以及年龄和性别匹配的嗓音正常的对照组(N = 77)。通过朗读《彩虹段落》和持续发元音“a”来获取语音样本。使用了四种不同复杂度的机器学习模型。采用SHapley加性解释(SHAP)来识别重要特征。
基于记录,最高的中位数自展ROC AUC分数为0.87,超过了临床医生的表现(范围:0.74 - 0.81)。由于存储时数据的原始处理方式,UVFP记录和对照组的录音时长不同,不过我们可以证明这能够对两组进行分类。而且与直觉相反的是,许多UVFP记录的强度高于对照组,而UVFP患者的嗓音往往较弱,这揭示了特定于数据集的偏差,我们在额外分析中对其进行了缓解。
我们证明了音频时长和强度方面的记录偏差在患者和对照组之间造成了特定于数据集的差异,模型利用这些差异来改善分类。此外,临床医生的评分进一步证明患者在过度发声,并且录音时的信号幅度高于对照组。有趣的是,在匹配音频时长并去除与强度相关的变量以减轻偏差后