Lewis M, Bromley K, Sutton C J, McCray G, Myers H L, Lancaster G A
Biostatistics Group, School of Medicine, Keele University, Room 1.111, David Weatherall Building, Keele, Staffordshire, ST5 5BG, UK.
Keele Clinical Trials Unit, Keele University, Keele, Staffordshire, UK.
Pilot Feasibility Stud. 2021 Feb 3;7(1):40. doi: 10.1186/s40814-021-00770-x.
The current CONSORT guidelines for reporting pilot trials do not recommend hypothesis testing of clinical outcomes on the basis that a pilot trial is under-powered to detect such differences and this is the aim of the main trial. It states that primary evaluation should focus on descriptive analysis of feasibility/process outcomes (e.g. recruitment, adherence, treatment fidelity). Whilst the argument for not testing clinical outcomes is justifiable, the same does not necessarily apply to feasibility/process outcomes, where differences may be large and detectable with small samples. Moreover, there remains much ambiguity around sample size for pilot trials.
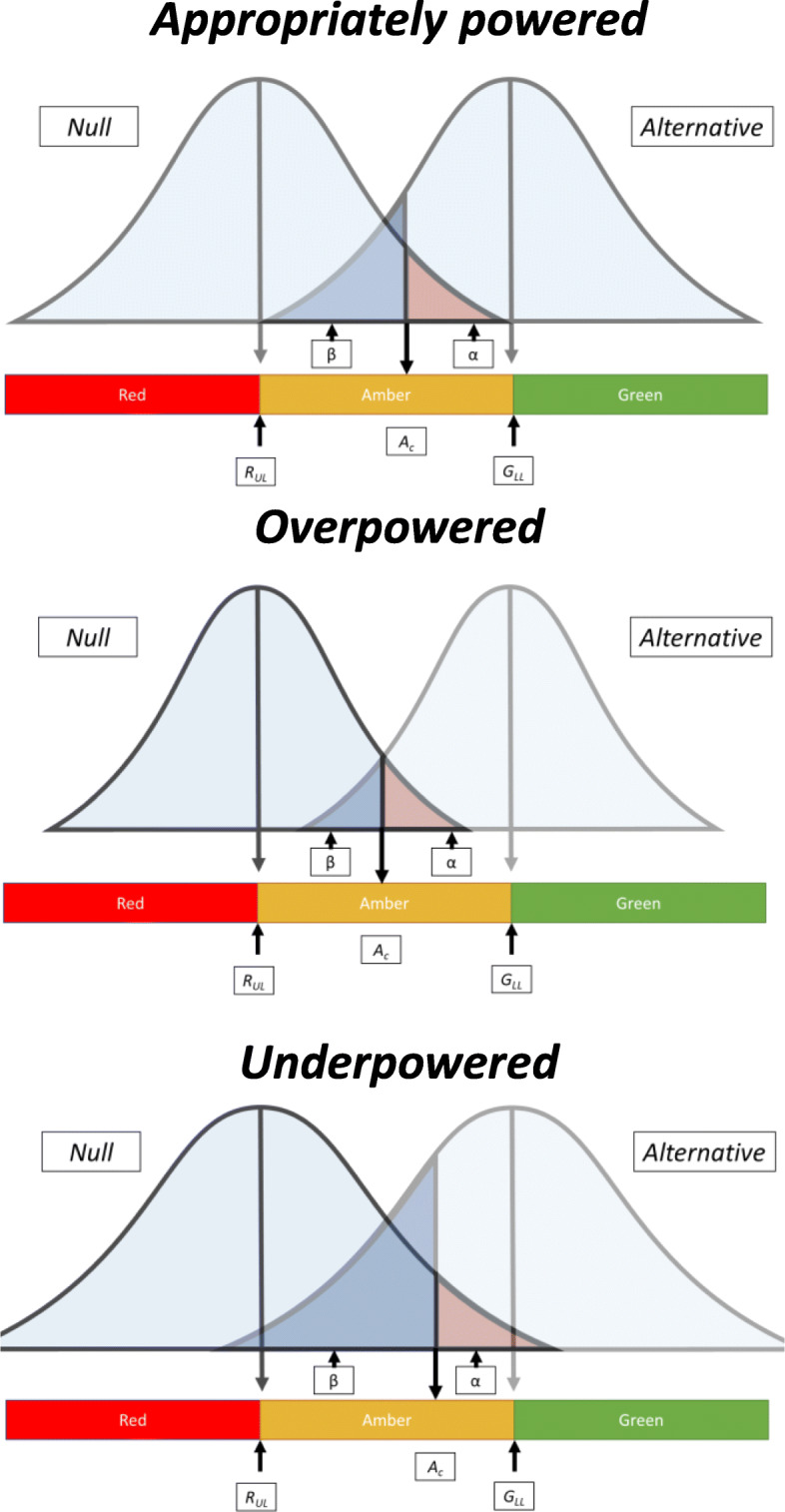
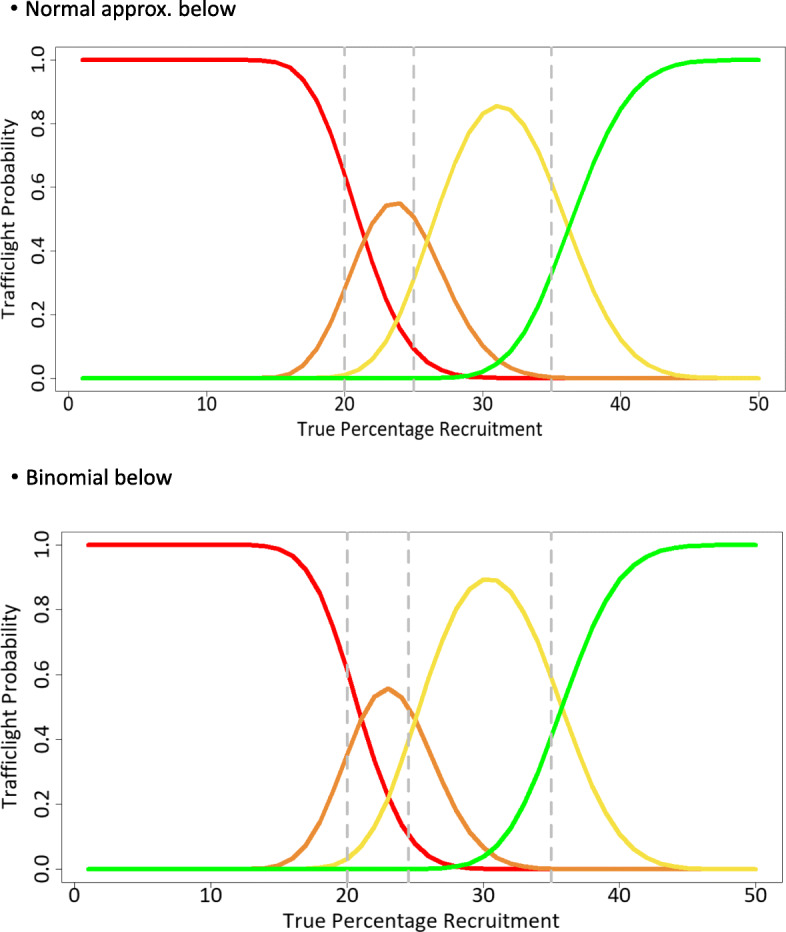
Many pilot trials adopt a 'traffic light' system for evaluating progression to the main trial determined by a set of criteria set up a priori. We construct a hypothesis testing approach for binary feasibility outcomes focused around this system that tests against being in the RED zone (unacceptable outcome) based on an expectation of being in the GREEN zone (acceptable outcome) and choose the sample size to give high power to reject being in the RED zone if the GREEN zone holds true. Pilot point estimates falling in the RED zone will be statistically non-significant and in the GREEN zone will be significant; the AMBER zone designates potentially acceptable outcome and statistical tests may be significant or non-significant.
For example, in relation to treatment fidelity, if we assume the upper boundary of the RED zone is 50% and the lower boundary of the GREEN zone is 75% (designating unacceptable and acceptable treatment fidelity, respectively), the sample size required for analysis given 90% power and one-sided 5% alpha would be around n = 34 (intervention group alone). Observed treatment fidelity in the range of 0-17 participants (0-50%) will fall into the RED zone and be statistically non-significant, 18-25 (51-74%) fall into AMBER and may or may not be significant and 26-34 (75-100%) fall into GREEN and will be significant indicating acceptable fidelity.
In general, several key process outcomes are assessed for progression to a main trial; a composite approach would require appraising the rules of progression across all these outcomes. This methodology provides a formal framework for hypothesis testing and sample size indication around process outcome evaluation for pilot RCTs.
当前用于报告预试验的CONSORT指南不建议对临床结局进行假设检验,理由是预试验的效能不足以检测出此类差异,而这是主要试验的目标。该指南指出,主要评估应侧重于可行性/过程结局(如招募、依从性、治疗保真度)的描述性分析。虽然不检验临床结局的观点是合理的,但这不一定适用于可行性/过程结局,因为这些结局的差异可能很大,且小样本即可检测到。此外,预试验的样本量仍存在很多不明确之处。
许多预试验采用“交通灯”系统,根据一组预先设定的标准来评估是否推进到主要试验。我们构建了一种针对二元可行性结局的假设检验方法,该方法围绕此系统展开,基于处于绿色区域(可接受结局)的预期,针对处于红色区域(不可接受结局)进行检验,并选择样本量,以便在绿色区域成立时,有较高的把握度拒绝处于红色区域。落在红色区域的预试验点估计在统计学上无显著性,落在绿色区域则有显著性;琥珀色区域表示潜在可接受结局,统计检验可能有显著性或无显著性。
例如,对于治疗保真度,如果我们假设红色区域的上限为50%,绿色区域的下限为75%(分别表示不可接受和可接受的治疗保真度),在检验效能为90%且单侧α为5%的情况下,分析所需的样本量约为n = 34(仅干预组)。观察到的治疗保真度在0至17名参与者(0至50%)范围内将落入红色区域,在统计学上无显著性,18至25名(51至74%)落入琥珀色区域,可能有显著性也可能无显著性,26至34名(75至100%)落入绿色区域,将有显著性,表明保真度可接受。
一般来说,会评估几个关键的过程结局以确定是否推进到主要试验;采用综合方法需要评估所有这些结局的推进规则。该方法为预试验随机对照试验过程结局评估的假设检验和样本量确定提供了一个正式框架。