Garcia-Peraza-Herrera Luis C, Fidon Lucas, D'Ettorre Claudia, Stoyanov Danail, Vercauteren Tom, Ourselin Sebastien
IEEE Trans Med Imaging. 2021 May;40(5):1450-1460. doi: 10.1109/TMI.2021.3057884. Epub 2021 Apr 30.
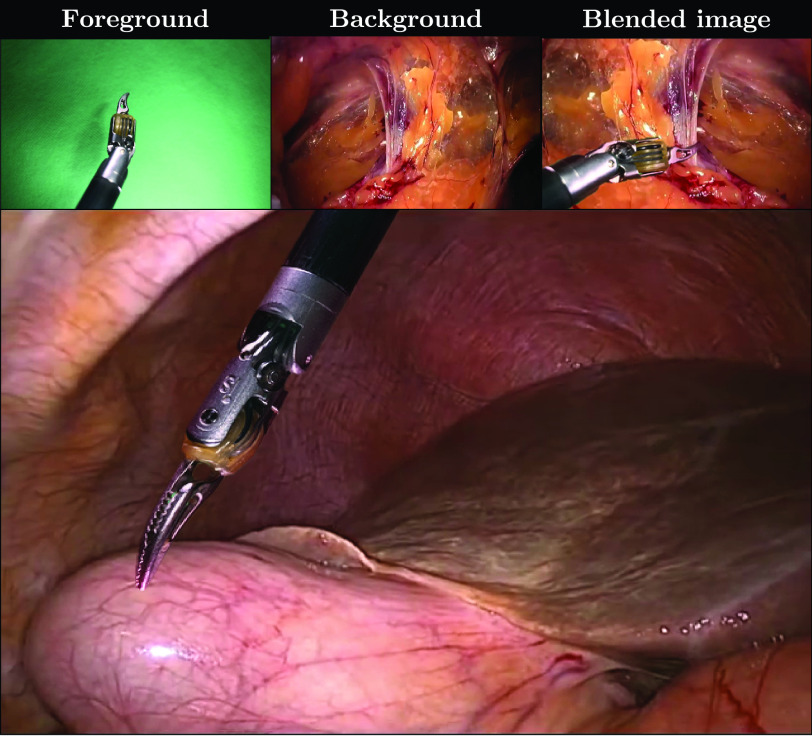
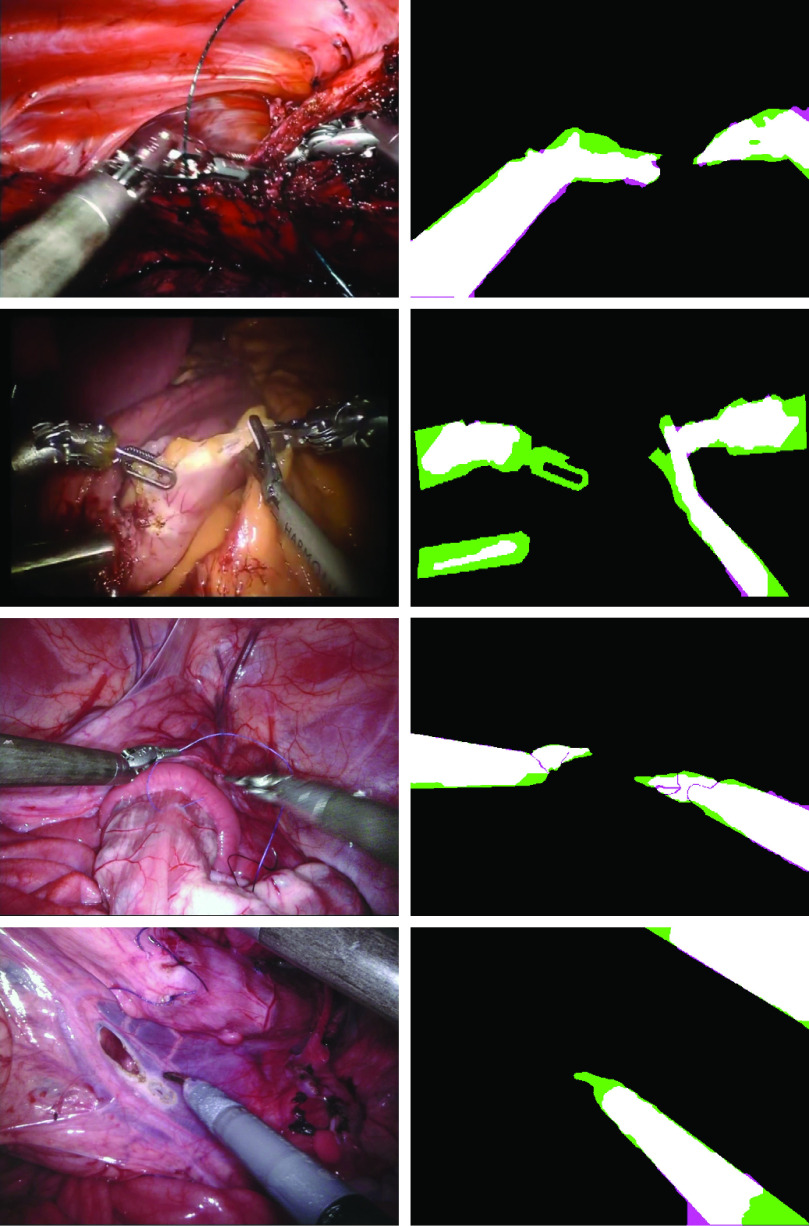
Producing manual, pixel-accurate, image segmentation labels is tedious and time-consuming. This is often a rate-limiting factor when large amounts of labeled images are required, such as for training deep convolutional networks for instrument-background segmentation in surgical scenes. No large datasets comparable to industry standards in the computer vision community are available for this task. To circumvent this problem, we propose to automate the creation of a realistic training dataset by exploiting techniques stemming from special effects and harnessing them to target training performance rather than visual appeal. Foreground data is captured by placing sample surgical instruments over a chroma key (a.k.a. green screen) in a controlled environment, thereby making extraction of the relevant image segment straightforward. Multiple lighting conditions and viewpoints can be captured and introduced in the simulation by moving the instruments and camera and modulating the light source. Background data is captured by collecting videos that do not contain instruments. In the absence of pre-existing instrument-free background videos, minimal labeling effort is required, just to select frames that do not contain surgical instruments from videos of surgical interventions freely available online. We compare different methods to blend instruments over tissue and propose a novel data augmentation approach that takes advantage of the plurality of options. We show that by training a vanilla U-Net on semi-synthetic data only and applying a simple post-processing, we are able to match the results of the same network trained on a publicly available manually labeled real dataset.
生成手动的、像素精确的图像分割标签既繁琐又耗时。当需要大量带标签的图像时,比如用于训练手术场景中仪器 - 背景分割的深度卷积网络时,这往往是一个限速因素。目前没有与计算机视觉社区行业标准相当的大型数据集可用于此任务。为了规避这个问题,我们建议通过利用源自特效的技术并将其用于提升训练性能而非视觉效果,来自动创建一个逼真的训练数据集。前景数据是在受控环境中通过将样本手术器械放置在色度键(又称绿幕)上进行采集的,从而使相关图像片段的提取变得简单直接。通过移动器械和相机以及调节光源,可以在模拟中捕捉和引入多种光照条件和视角。背景数据是通过收集不含器械的视频来获取的。在没有预先存在的无器械背景视频的情况下,只需要进行最少的标注工作,即从网上免费获取的手术干预视频中选择不包含手术器械的帧即可。我们比较了将器械融合到组织上的不同方法,并提出了一种利用多种选项的新型数据增强方法。我们表明,仅在半合成数据上训练一个普通的U-Net并应用简单的后处理,我们就能与在公开可用的手动标注真实数据集上训练的同一网络的结果相匹配。