School of Engineering (Electrical and Renewable Energy), Deakin University, Waurn Ponds, Australia.
Institute for Intelligent Systems Research and Innovation, Deakin University, Waurn Ponds, Australia.
PLoS One. 2021 Feb 10;16(2):e0245589. doi: 10.1371/journal.pone.0245589. eCollection 2021.
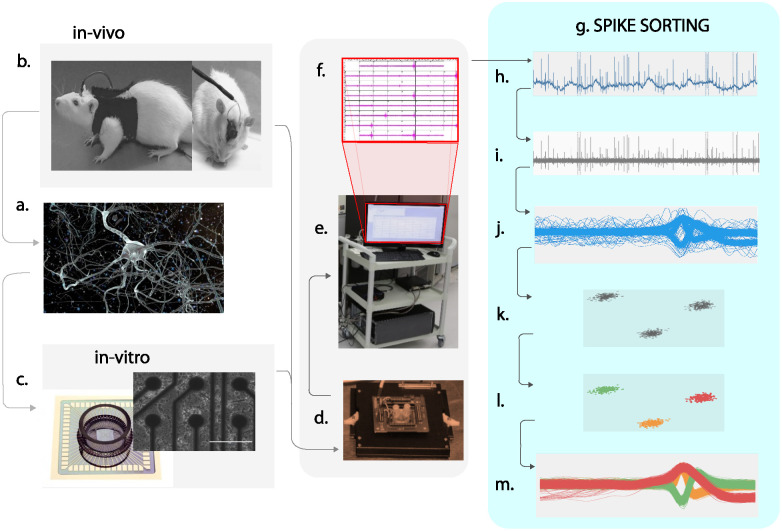
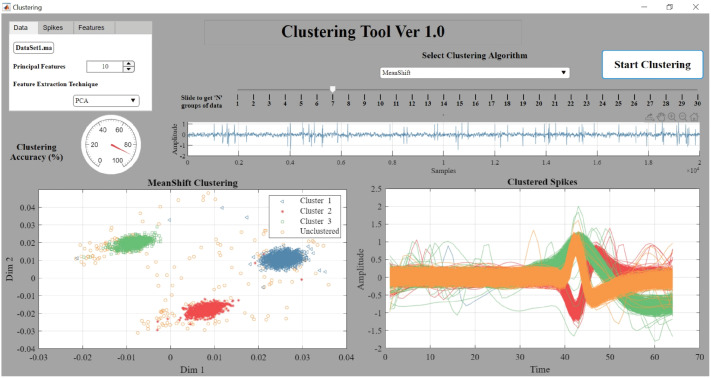
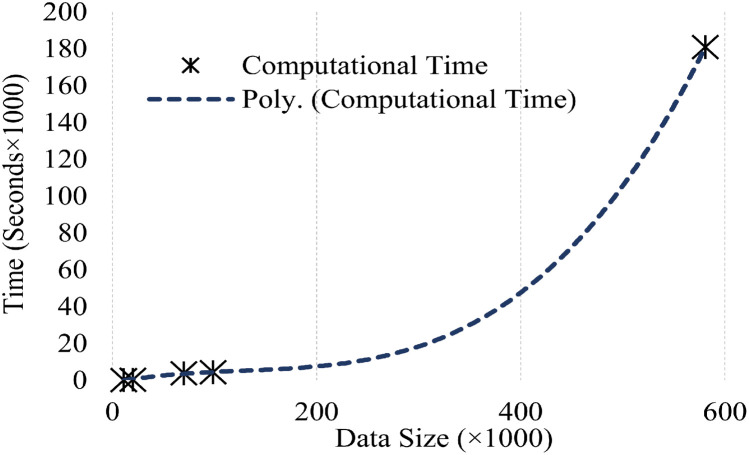
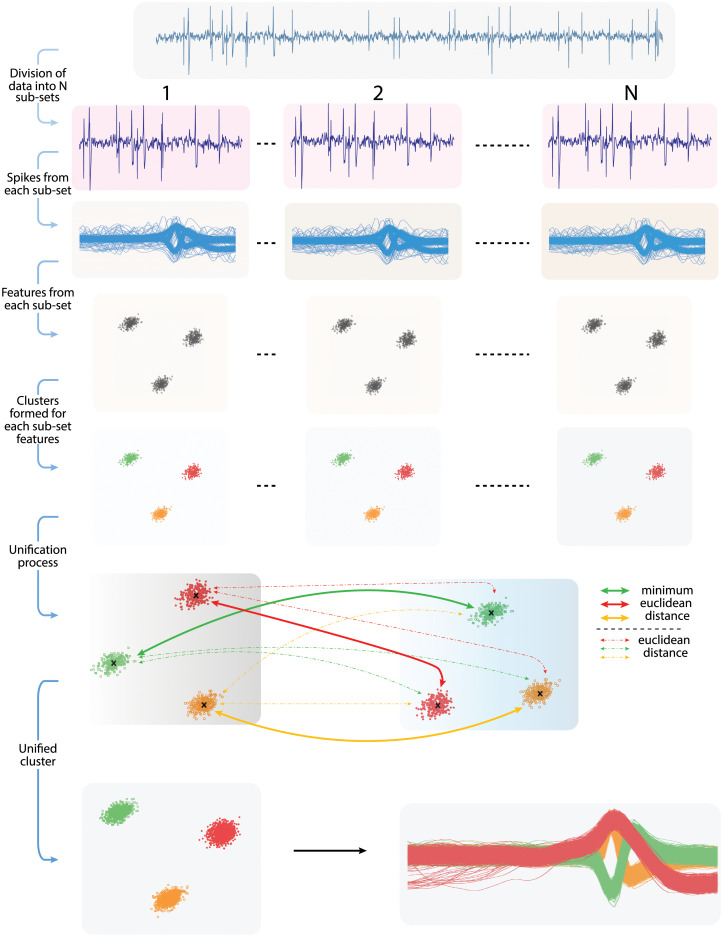
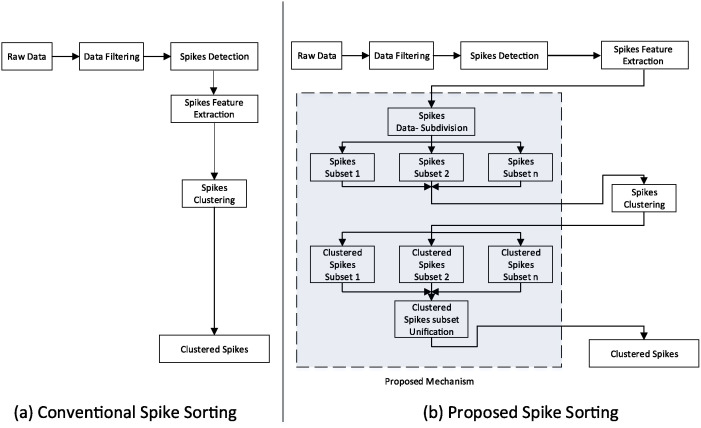
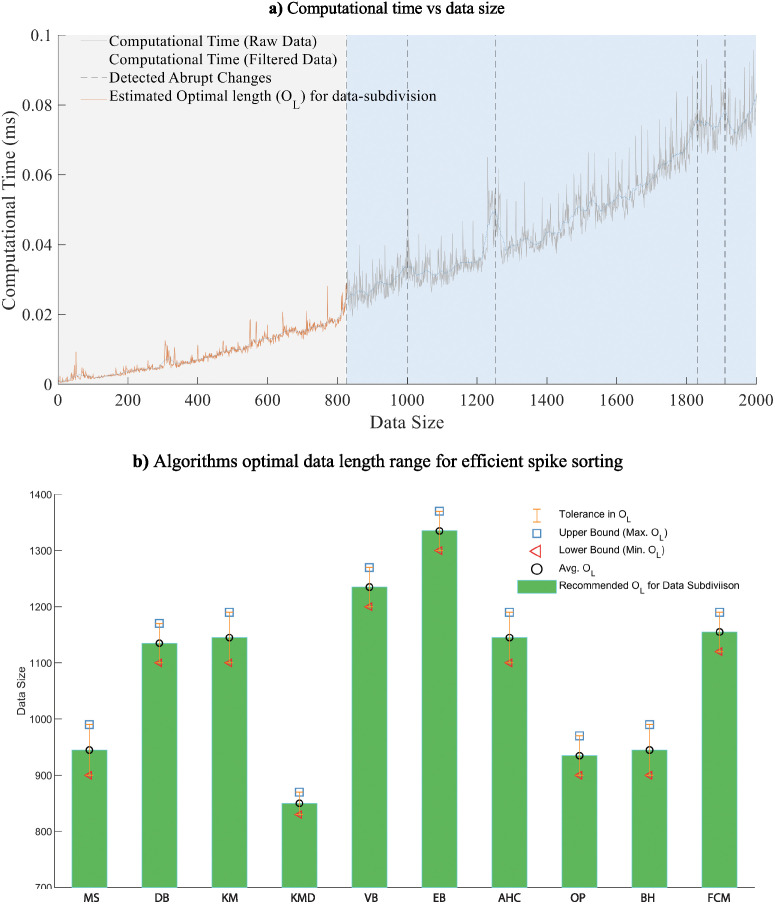
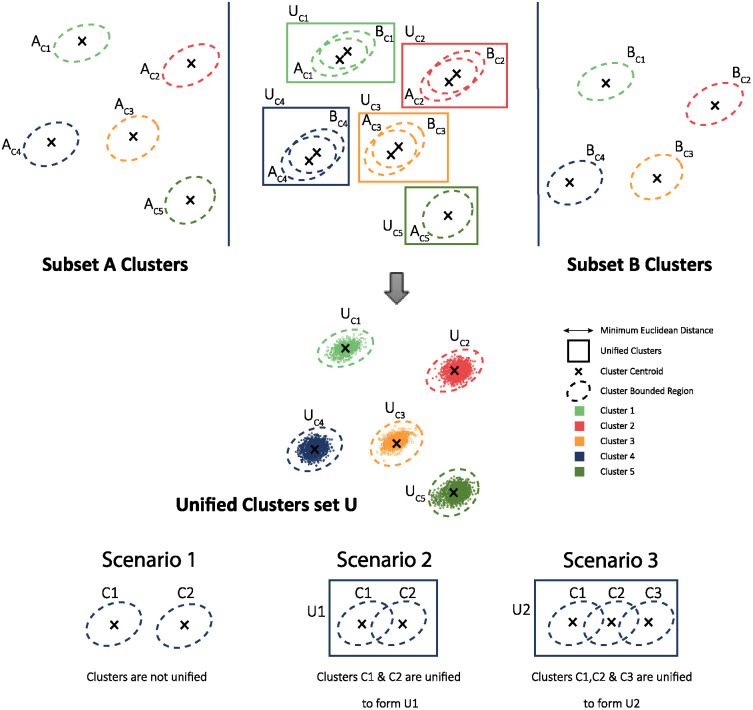
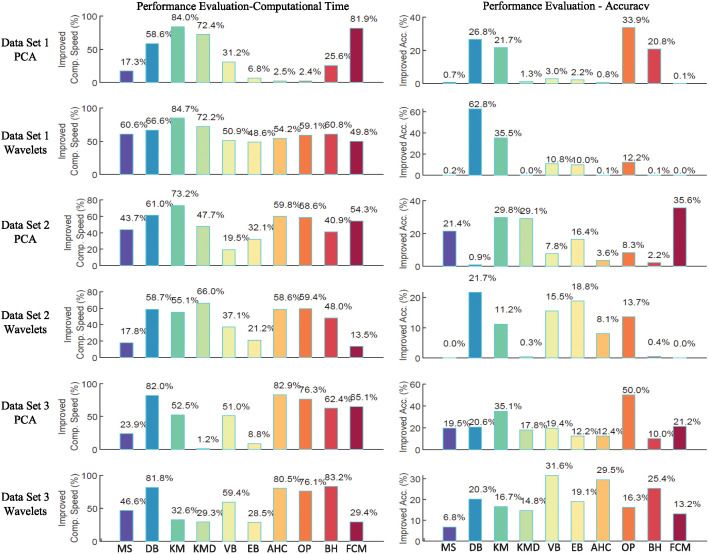
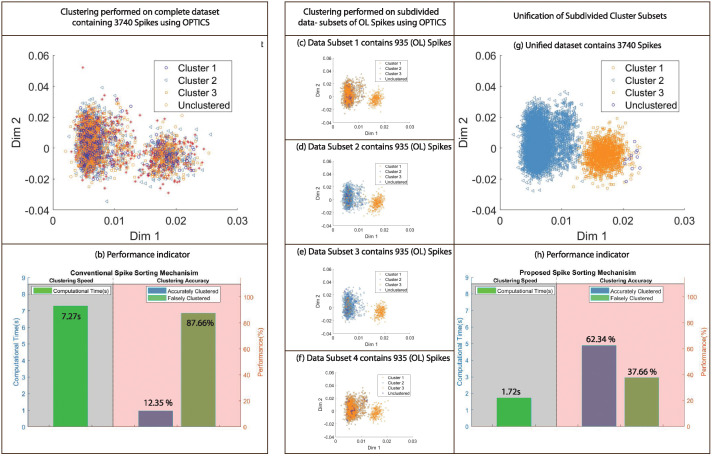
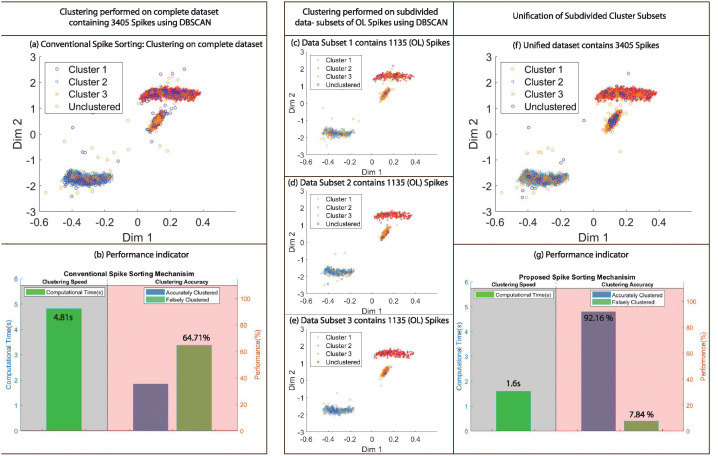
Neural spike sorting is prerequisite to deciphering useful information from electrophysiological data recorded from the brain, in vitro and/or in vivo. Significant advancements in nanotechnology and nanofabrication has enabled neuroscientists and engineers to capture the electrophysiological activities of the brain at very high resolution, data rate and fidelity. However, the evolution in spike sorting algorithms to deal with the aforementioned technological advancement and capability to quantify higher density data sets is somewhat limited. Both supervised and unsupervised clustering algorithms do perform well when the data to quantify is small, however, their efficiency degrades with the increase in the data size in terms of processing time and quality of spike clusters being formed. This makes neural spike sorting an inefficient process to deal with large and dense electrophysiological data recorded from brain. The presented work aims to address this challenge by providing a novel data pre-processing framework, which can enhance the efficiency of the conventional spike sorting algorithms significantly. The proposed framework is validated by applying on ten widely used algorithms and six large feature sets. Feature sets are calculated by employing PCA and Haar wavelet features on three widely adopted large electrophysiological datasets for consistency during the clustering process. A MATLAB software of the proposed mechanism is also developed and provided to assist the researchers, active in this domain.
神经尖峰分类是从脑内、体外和/或体内记录的电生理数据中解码有用信息的前提。纳米技术和纳米制造的重大进展使神经科学家和工程师能够以非常高的分辨率、数据率和保真度捕获大脑的电生理活动。然而,用于处理上述技术进步和量化更高密度数据集的能力的尖峰分类算法的发展有些有限。监督和无监督聚类算法在要量化的数据较小时表现良好,但是,随着数据大小的增加,它们的效率会降低,表现在处理时间和形成的尖峰簇的质量方面。这使得神经尖峰分类成为处理从大脑记录的大型和密集电生理数据的低效过程。本工作旨在通过提供一种新颖的数据预处理框架来解决这一挑战,该框架可以显著提高传统尖峰分类算法的效率。通过在十个广泛使用的算法和六个大型特征集上应用该框架,验证了所提出的框架。为了在聚类过程中保持一致性,使用 PCA 和 Haar 小波特征计算特征集。还开发并提供了一个用于协助该领域研究人员的 MATLAB 软件。