Bioinformatics and Computational Biology Program, Iowa State University, Ames, IA 50011, USA.
Center for Metabolic Biology, Iowa State University, Ames, IA 50011, USA.
Bioinformatics. 2021 Sep 29;37(18):3019-3020. doi: 10.1093/bioinformatics/btab090.
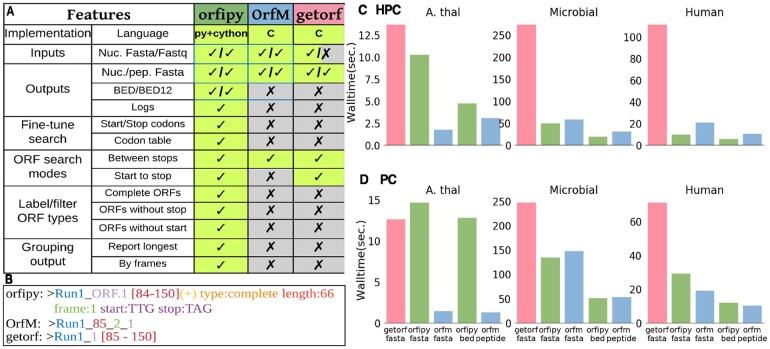
Searching for open reading frames is a routine task and a critical step prior to annotating protein coding regions in newly sequenced genomes or de novo transcriptome assemblies. With the tremendous increase in genomic and transcriptomic data, faster tools are needed to handle large input datasets. These tools should be versatile enough to fine-tune search criteria and allow efficient downstream analysis. Here we present a new python based tool, orfipy, which allows the user to flexibly search for open reading frames in genomic and transcriptomic sequences. The search is rapid and is fully customizable, with a choice of FASTA and BED output formats.
orfipy is implemented in python and is compatible with python v3.6 and higher. Source code: https://github.com/urmi-21/orfipy. Installation: from the source, or via PyPi (https://pypi.org/project/orfipy) or bioconda (https://anaconda.org/bioconda/orfipy).
Supplementary data are available at Bioinformatics online.
搜索开放阅读框是一项常规任务,也是注释新测序基因组或从头转录组组装中蛋白质编码区域的关键步骤。随着基因组和转录组数据的大量增加,需要更快的工具来处理大型输入数据集。这些工具应该足够灵活,能够调整搜索标准,并允许进行有效的下游分析。在这里,我们介绍了一个新的基于 Python 的工具 orfipy,它允许用户灵活地在基因组和转录组序列中搜索开放阅读框。搜索速度很快,并且完全可定制,支持 FASTA 和 BED 输出格式。
orfipy 是用 Python 实现的,与 Python v3.6 及更高版本兼容。源代码:https://github.com/urmi-21/orfipy。安装:从源代码,或通过 PyPi(https://pypi.org/project/orfipy)或 bioconda(https://anaconda.org/bioconda/orfipy)。
补充数据可在生物信息学在线获得。