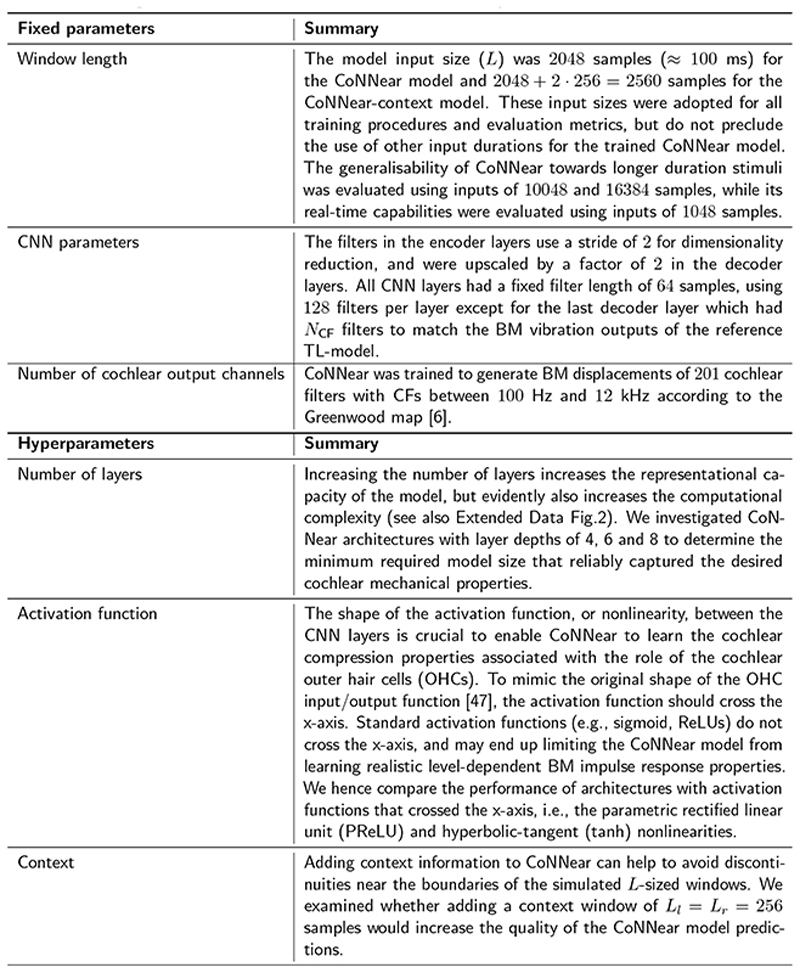
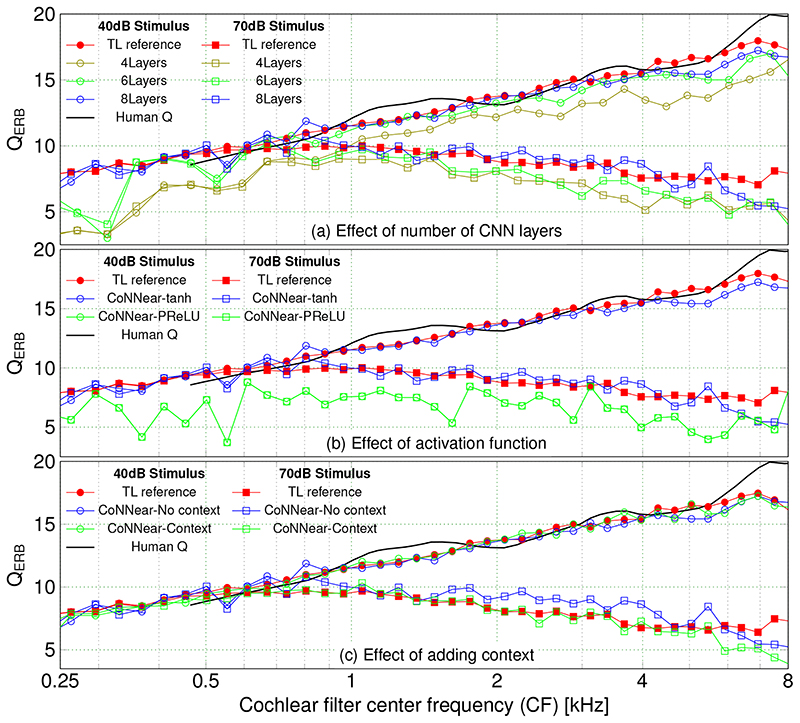
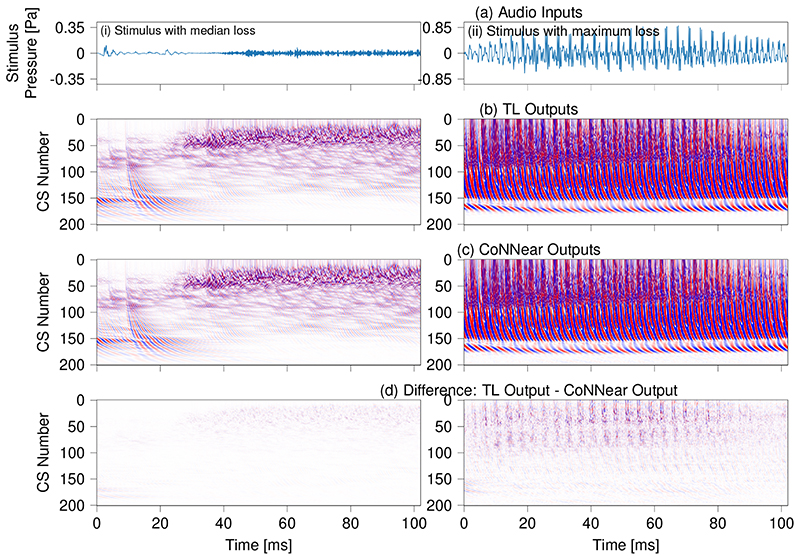
Baby Deepak, Van Den Broucke Arthur, Verhulst Sarah
Hearing Technology @ WAVES, Dept. of Information Technology, Ghent University, 9000 Ghent, Belgium.
Nat Mach Intell. 2021 Feb;3(2):134-143. doi: 10.1038/s42256-020-00286-8. Epub 2021 Feb 8.
Auditory models are commonly used as feature extractors for automatic speech-recognition systems or as front-ends for robotics, machine-hearing and hearing-aid applications. Although auditory models can capture the biophysical and nonlinear properties of human hearing in great detail, these biophysical models are computationally expensive and cannot be used in real-time applications. We present a hybrid approach where convolutional neural networks are combined with computational neuroscience to yield a real-time end-to-end model for human cochlear mechanics, including level-dependent filter tuning (CoNNear). The CoNNear model was trained on acoustic speech material and its performance and applicability were evaluated using (unseen) sound stimuli commonly employed in cochlear mechanics research. The CoNNear model accurately simulates human cochlear frequency selectivity and its dependence on sound intensity, an essential quality for robust speech intelligibility at negative speech-to-background-noise ratios. The CoNNear architecture is based on parallel and differentiable computations and has the power to achieve real-time human performance. These unique CoNNear features will enable the next generation of human-like machine-hearing applications.
听觉模型通常用作自动语音识别系统的特征提取器,或用作机器人技术、机器听觉和助听器应用的前端。尽管听觉模型可以非常详细地捕捉人类听觉的生物物理和非线性特性,但这些生物物理模型计算成本高昂,无法用于实时应用。我们提出了一种混合方法,将卷积神经网络与计算神经科学相结合,以产生一种用于人类耳蜗力学的实时端到端模型,包括与电平相关的滤波器调谐(CoNNear)。CoNNear模型在声学语音材料上进行训练,并使用耳蜗力学研究中常用的(未见)声音刺激来评估其性能和适用性。CoNNear模型准确地模拟了人类耳蜗频率选择性及其对声音强度的依赖性,这是在负语音与背景噪声比下实现稳健语音可懂度的一项基本特性。CoNNear架构基于并行和可微计算,有能力实现实时人类性能。这些独特的CoNNear特性将推动下一代类人机器听觉应用的发展。