Linguistic Data Consortium, University of Pennsylvania, Philadelphia, PA, USA.
Department of Neurology and Penn Frontotemporal Degeneration Center, University of Pennsylvania, Philadelphia, PA, USA.
Cortex. 2021 Apr;137:215-231. doi: 10.1016/j.cortex.2021.01.012. Epub 2021 Feb 6.
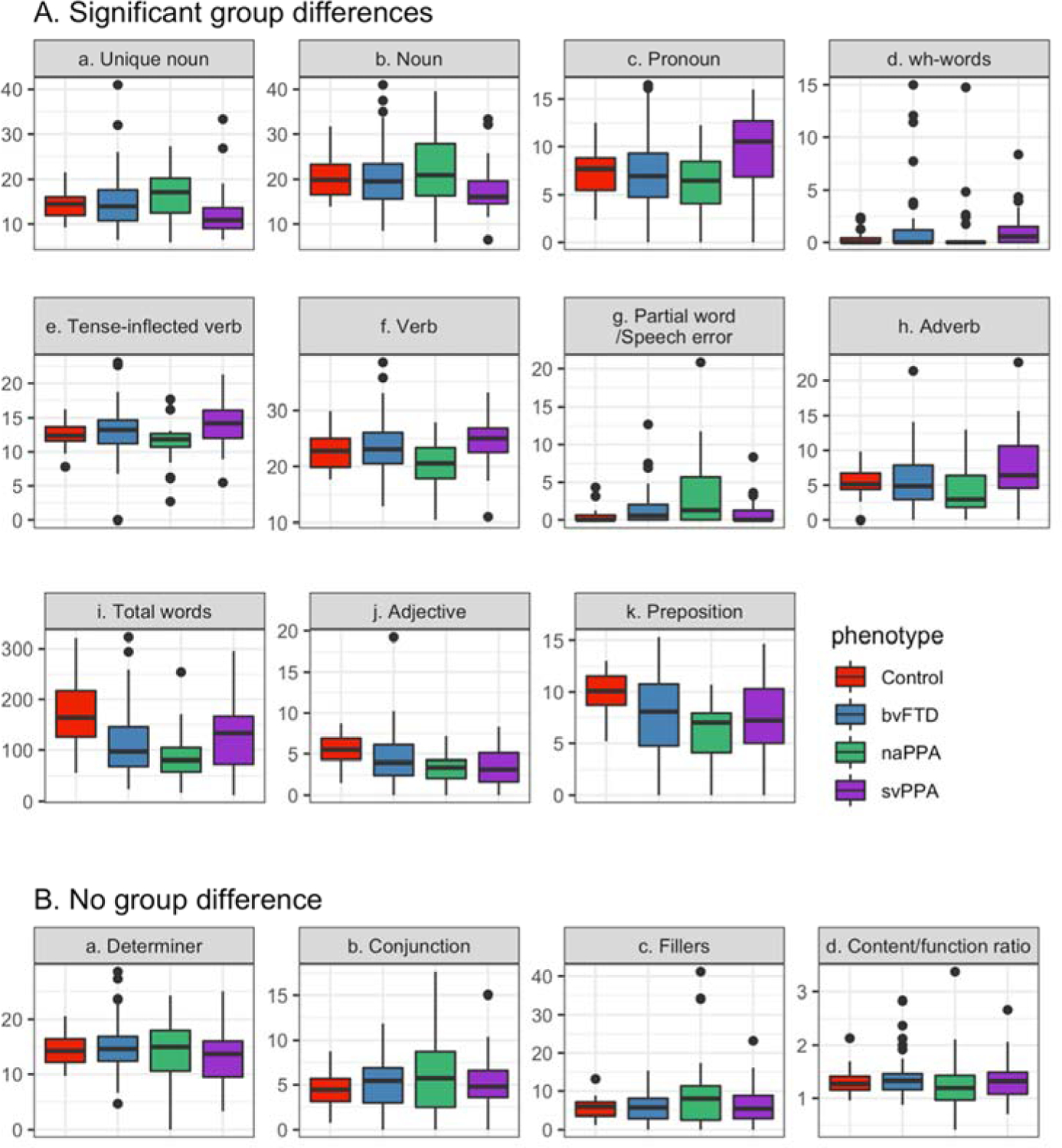
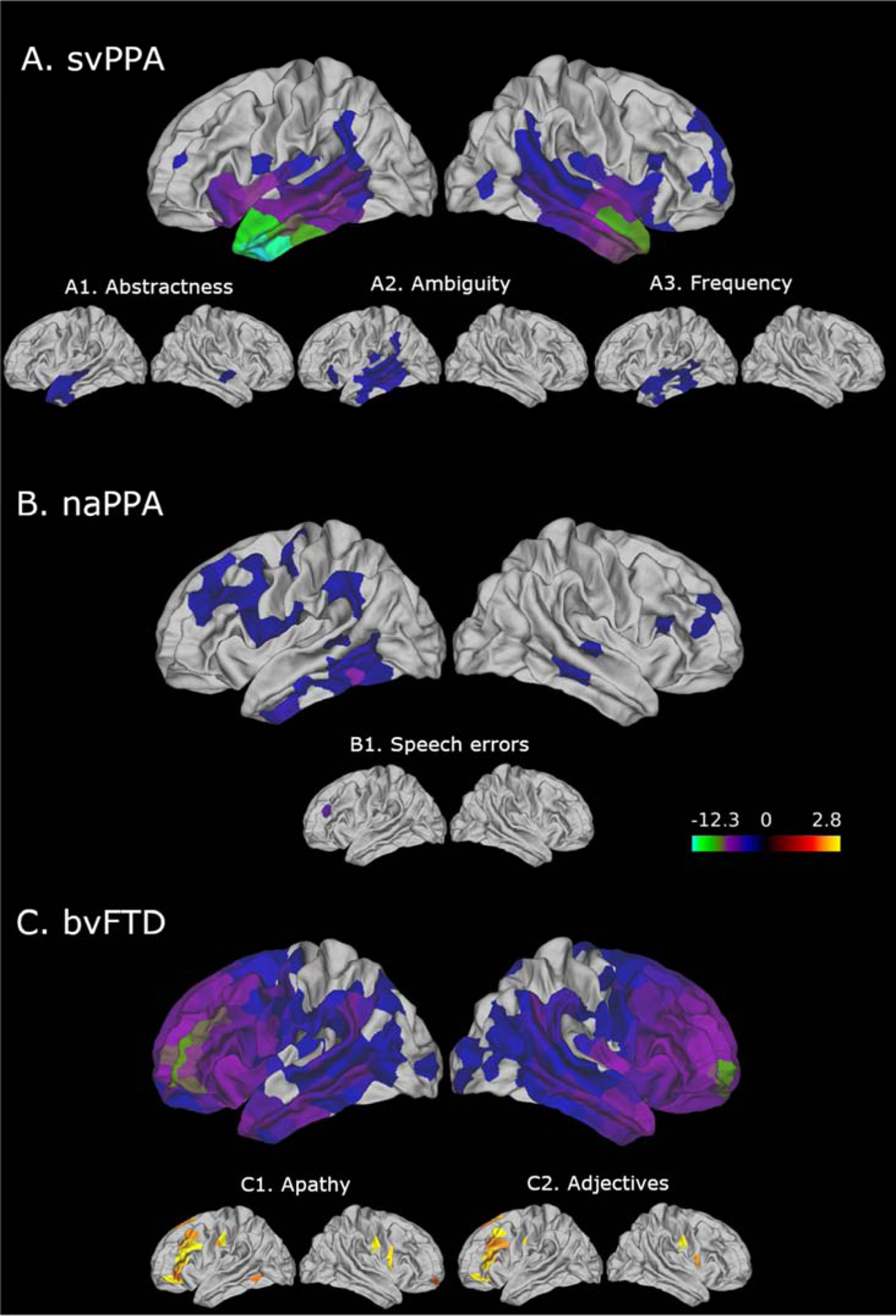
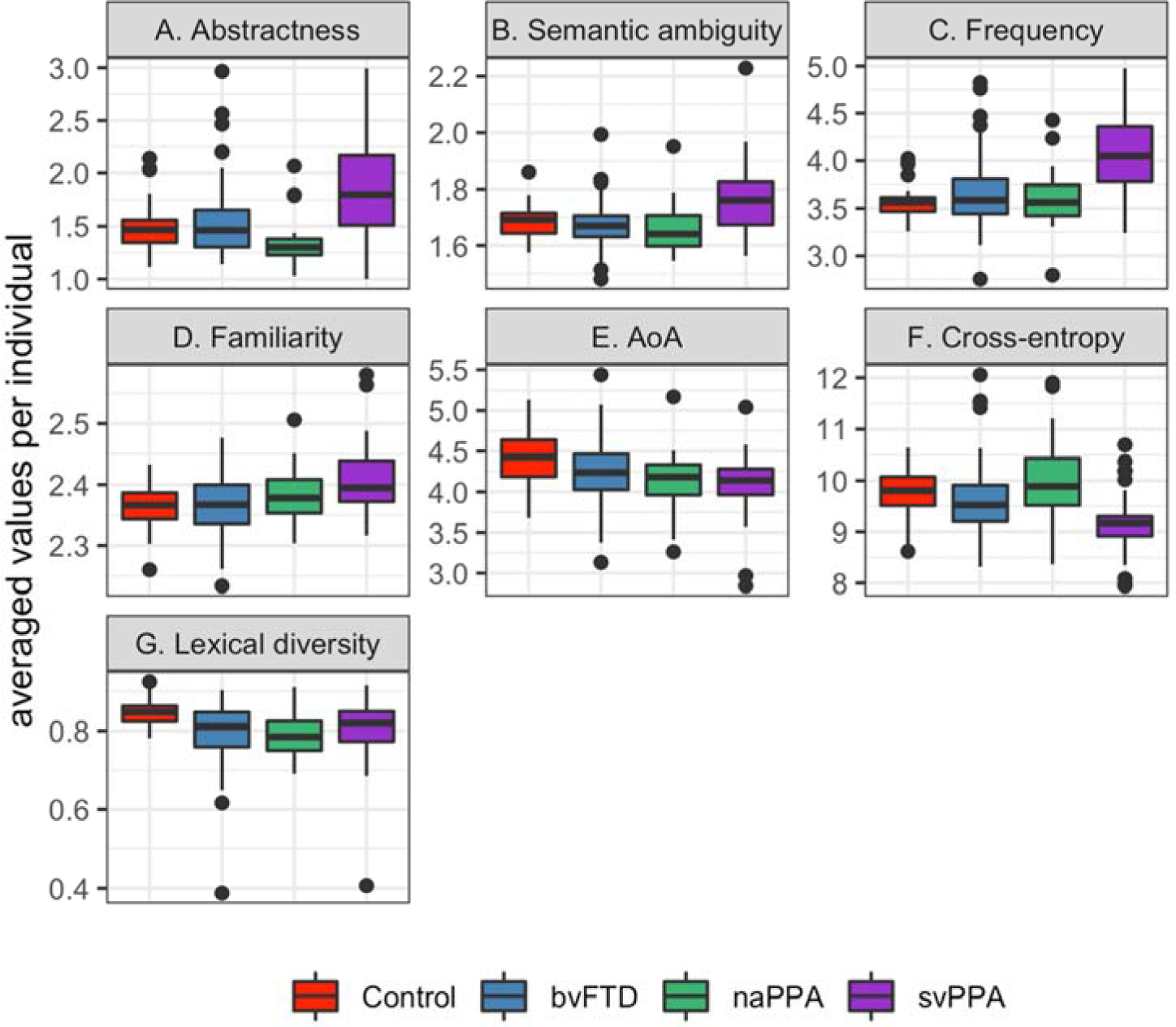
We implemented an automated analysis of lexical aspects of semi-structured speech produced by healthy elderly controls (n = 37) and three patient groups with frontotemporal degeneration (FTD): behavioral variant FTD (n = 74), semantic variant primary progressive aphasia (svPPA, n = 42), and nonfluent/agrammatic PPA (naPPA, n = 22). Based on previous findings, we hypothesized that the three patient groups and controls would differ in the counts of part-of-speech (POS) categories and several lexical measures. With a natural language processing program, we automatically tagged POS categories of all words produced during a picture description task. We further counted the number of wh-words, and we rated nouns for abstractness, ambiguity, frequency, familiarity, and age of acquisition. We also computed the cross-entropy estimation, where low cross-entropy indicates high predictability, and lexical diversity for each description. We validated a subset of the POS data that were automatically tagged with the Google Universal POS scheme using gold-standard POS data tagged by a linguist, and we found that the POS categories from our automated methods were more than 90% accurate. For svPPA patients, we found fewer unique nouns than in naPPA and more pronouns and wh-words than in the other groups. We also found high abstractness, ambiguity, frequency, and familiarity for nouns and the lowest cross-entropy estimation among all groups. These measures were associated with cortical thinning in the left temporal lobe. In naPPA patients, we found increased speech errors and partial words compared to controls, and these impairments were associated with cortical thinning in the left middle frontal gyrus. bvFTD patients' adjective production was decreased compared to controls and was correlated with their apathy scores. Their adjective production was associated with cortical thinning in the dorsolateral frontal and orbitofrontal gyri. Our results demonstrate distinct language profiles in subgroups of FTD patients and validate our automated method of analyzing FTD patients' speech.
我们对健康老年对照组(n=37)和三种额颞叶变性(FTD)患者组(行为变异型 FTD [bvFTD],n=74;语义变异型原发性进行性失语症 [svPPA],n=42;非流利/语法障碍型进行性失语症 [naPPA],n=22)产生的半结构化言语的词汇方面进行了自动化分析。基于之前的研究结果,我们假设这三组患者组和对照组在词类(POS)类别和几个词汇测量方面存在差异。我们使用自然语言处理程序自动标记了图片描述任务中所有单词的 POS 类别。我们进一步统计了 wh-词的数量,并对名词的抽象性、模糊性、频率、熟悉度和习得年龄进行了评分。我们还计算了交叉熵估计,其中低交叉熵表示可预测性高,并且为每个描述计算了词汇多样性。我们验证了使用语言学家标记的黄金标准 POS 数据自动标记的 POS 数据的子集,并且发现我们的自动方法的 POS 类别准确率超过 90%。对于 svPPA 患者,我们发现的独特名词比 naPPA 患者少,而代词和 wh-词比其他组多。我们还发现名词的抽象性、模糊性、频率和熟悉度都很高,而所有组中交叉熵估计最低。这些措施与左侧颞叶皮层变薄有关。在 naPPA 患者中,我们发现与对照组相比,言语错误和部分词语增加,这些损伤与左侧额中回皮层变薄有关。与对照组相比,bvFTD 患者的形容词生成减少,与他们的冷漠评分相关。他们的形容词生成与背外侧额回和眶额回皮层变薄有关。我们的研究结果表明,FTD 患者亚组存在不同的语言特征,并验证了我们分析 FTD 患者言语的自动化方法。