Department of Statistics and Data Science, Carnegie Mellon University, Pittsburgh, PA 15213.
Neurogenetics Program, University of California, Los Angeles, CA 90095.
Proc Natl Acad Sci U S A. 2021 Mar 9;118(10). doi: 10.1073/pnas.2024383118.
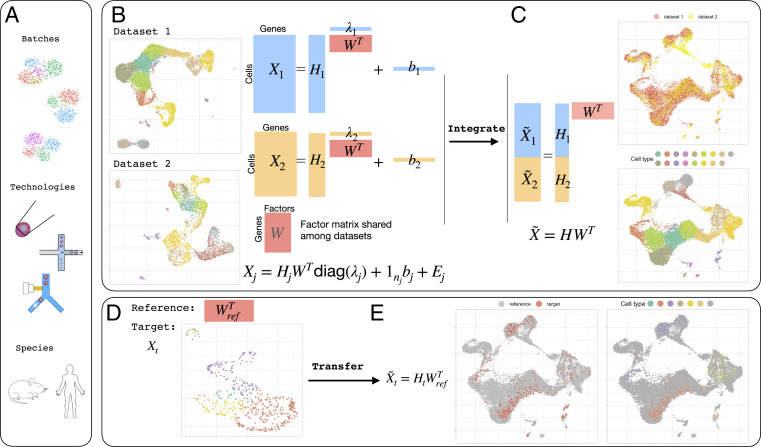
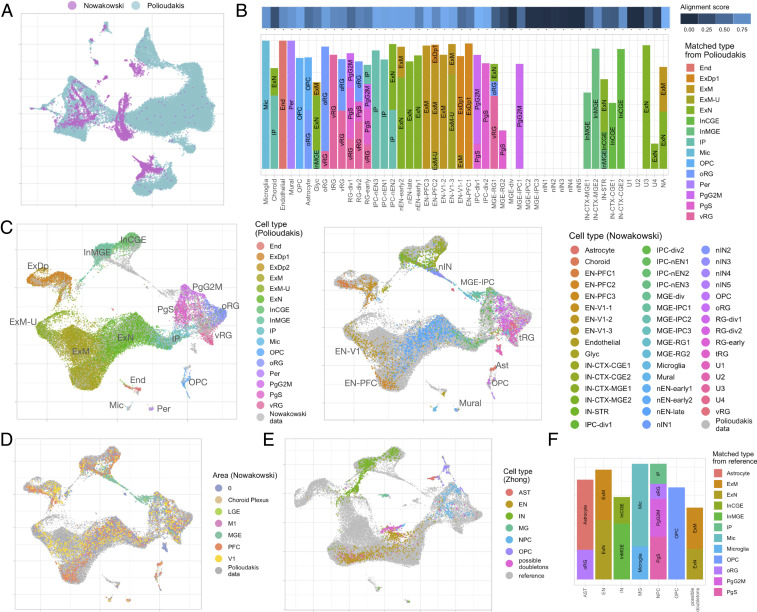
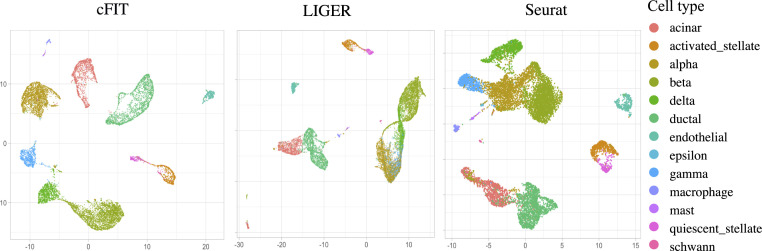
Large, comprehensive collections of single-cell RNA sequencing (scRNA-seq) datasets have been generated that allow for the full transcriptional characterization of cell types across a wide variety of biological and clinical conditions. As new methods arise to measure distinct cellular modalities, a key analytical challenge is to integrate these datasets or transfer knowledge from one to the other to better understand cellular identity and functions. Here, we present a simple yet surprisingly effective method named common factor integration and transfer learning (cFIT) for capturing various batch effects across experiments, technologies, subjects, and even species. The proposed method models the shared information between various datasets by a common factor space while allowing for unique distortions and shifts in genewise expression in each batch. The model parameters are learned under an iterative nonnegative matrix factorization (NMF) framework and then used for synchronized integration from across-domain assays. In addition, the model enables transferring via low-rank matrix from more informative data to allow for precise identification in data of lower quality. Compared with existing approaches, our method imposes weaker assumptions on the cell composition of each individual dataset; however, it is shown to be more reliable in preserving biological variations. We apply cFIT to multiple scRNA-seq datasets of developing brain from human and mouse, varying by technologies and developmental stages. The successful integration and transfer uncover the transcriptional resemblance across systems. The study helps establish a comprehensive landscape of brain cell-type diversity and provides insights into brain development.
大量全面的单细胞 RNA 测序 (scRNA-seq) 数据集已经生成,这些数据集允许对各种生物学和临床条件下的细胞类型进行全面的转录特征描述。随着新的方法出现来测量不同的细胞模态,一个关键的分析挑战是整合这些数据集或将知识从一个数据集转移到另一个数据集,以更好地理解细胞的身份和功能。在这里,我们提出了一种简单但非常有效的方法,称为通用因子集成和迁移学习 (cFIT),用于捕获实验、技术、对象甚至物种之间的各种批次效应。该方法通过共同因子空间来模拟各个数据集之间的共享信息,同时允许每个批次中基因表达的独特扭曲和偏移。模型参数在迭代非负矩阵分解 (NMF) 框架下进行学习,然后用于跨域分析进行同步集成。此外,该模型还可以通过从信息量更大的数据进行低秩矩阵传递,以允许在质量较低的数据中进行精确识别。与现有方法相比,我们的方法对每个单独数据集的细胞组成的假设较弱;然而,它在保留生物变化方面被证明更可靠。我们将 cFIT 应用于来自人类和小鼠的不同技术和发育阶段的发育中大脑的多个 scRNA-seq 数据集。成功的整合和转移揭示了系统之间的转录相似性。该研究有助于建立大脑细胞类型多样性的综合图景,并为大脑发育提供了新的见解。