Chen Weihao, Alexandre Pâmela A, Ribeiro Gabriela, Fukumasu Heidge, Sun Wei, Reverter Antonio, Li Yutao
College of Animal Science and Technology, Yangzhou University, Yangzhou, China.
CSIRO Agriculture and Food, St Lucia, QLD, Australia.
Front Genet. 2021 Feb 16;12:619857. doi: 10.3389/fgene.2021.619857. eCollection 2021.
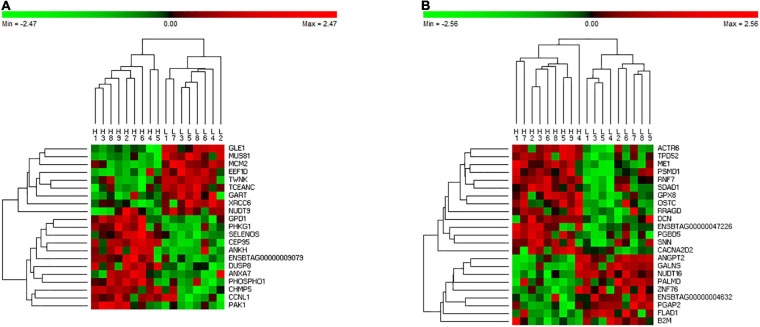
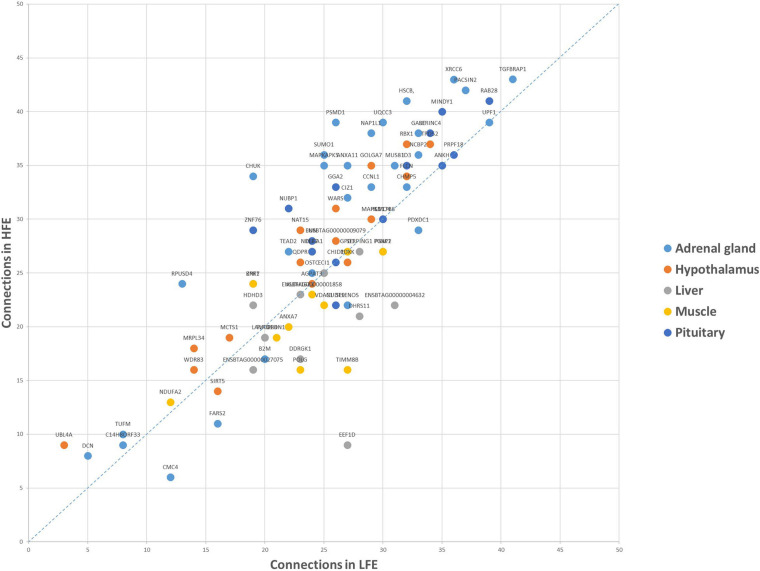
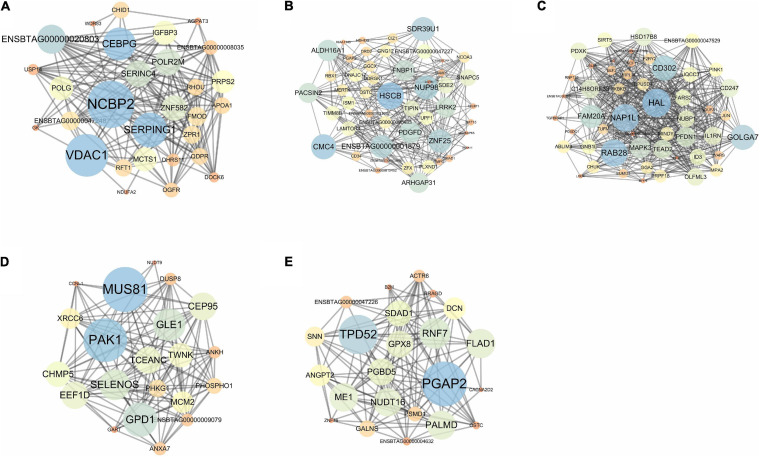
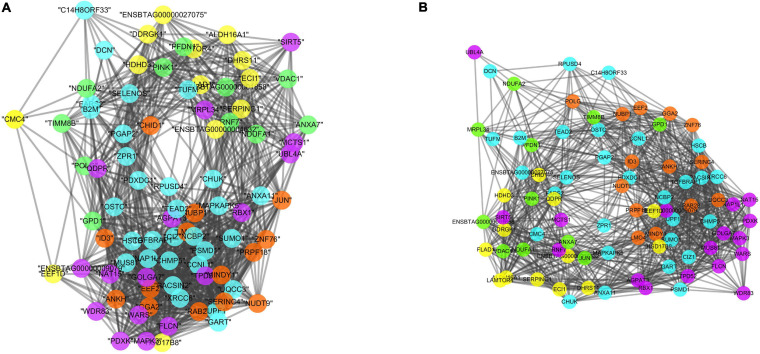
Machine learning (ML) methods have shown promising results in identifying genes when applied to large transcriptome datasets. However, no attempt has been made to compare the performance of combining different ML methods together in the prediction of high feed efficiency (HFE) and low feed efficiency (LFE) animals. In this study, using RNA sequencing data of five tissues (adrenal gland, hypothalamus, liver, skeletal muscle, and pituitary) from nine HFE and nine LFE Nellore bulls, we evaluated the prediction accuracies of five analytical methods in classifying FE animals. These included two conventional methods for differential gene expression (DGE) analysis (-test and edgeR) as benchmarks, and three ML methods: Random Forests (RFs), Extreme Gradient Boosting (XGBoost), and combination of both RF and XGBoost (RX). Utility of a subset of candidate genes selected from each method for classification of FE animals was assessed by support vector machine (SVM). Among all methods, the smallest subsets of genes (117) identified by RX outperformed those chosen by -test, edgeR, RF, or XGBoost in classification accuracy of animals. Gene co-expression network analysis confirmed the interactivity existing among these genes and their relevance within the network related to their prediction ranking based on ML. The results demonstrate a great potential for applying a combination of ML methods to large transcriptome datasets to identify biologically important genes for accurately classifying FE animals.
机器学习(ML)方法在应用于大型转录组数据集时,已在识别基因方面显示出有前景的结果。然而,尚未有人尝试比较不同ML方法组合在预测高饲料效率(HFE)和低饲料效率(LFE)动物方面的性能。在本研究中,我们使用了9头HFE和9头LFE内洛尔公牛的五个组织(肾上腺、下丘脑、肝脏、骨骼肌和垂体)的RNA测序数据,评估了五种分析方法在对FE动物进行分类时的预测准确性。其中包括两种用于差异基因表达(DGE)分析的传统方法(t检验和edgeR)作为基准,以及三种ML方法:随机森林(RF)、极端梯度提升(XGBoost)以及RF和XGBoost的组合(RX)。通过支持向量机(SVM)评估了从每种方法中选择的候选基因子集对FE动物分类的效用。在所有方法中,RX识别出的最小基因子集(117个)在动物分类准确性方面优于t检验、edgeR、RF或XGBoost选择的基因子集。基因共表达网络分析证实了这些基因之间存在的相互作用以及它们在网络中与其基于ML的预测排名相关的相关性。结果表明,将ML方法组合应用于大型转录组数据集以识别用于准确分类FE动物的生物学重要基因具有巨大潜力。