Database and Bioinformatics Laboratory, College of Electrical and Computer Engineering, Chungbuk National University, Cheongju 28644, Korea.
School of Medicine, Nankai University, Tianjin 300071, China.
Int J Environ Res Public Health. 2021 Feb 23;18(4):2197. doi: 10.3390/ijerph18042197.
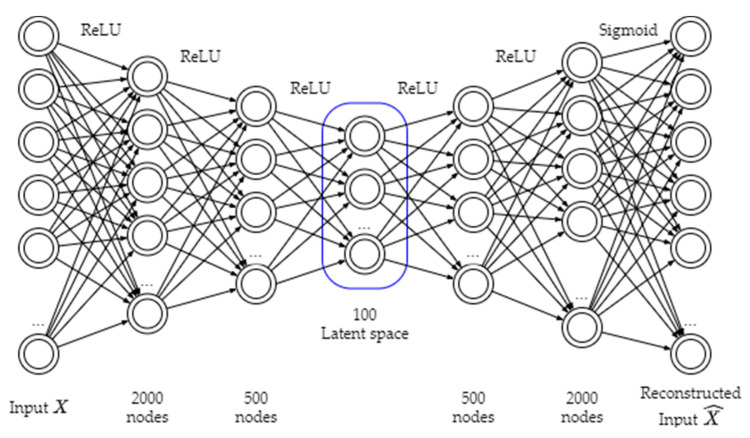
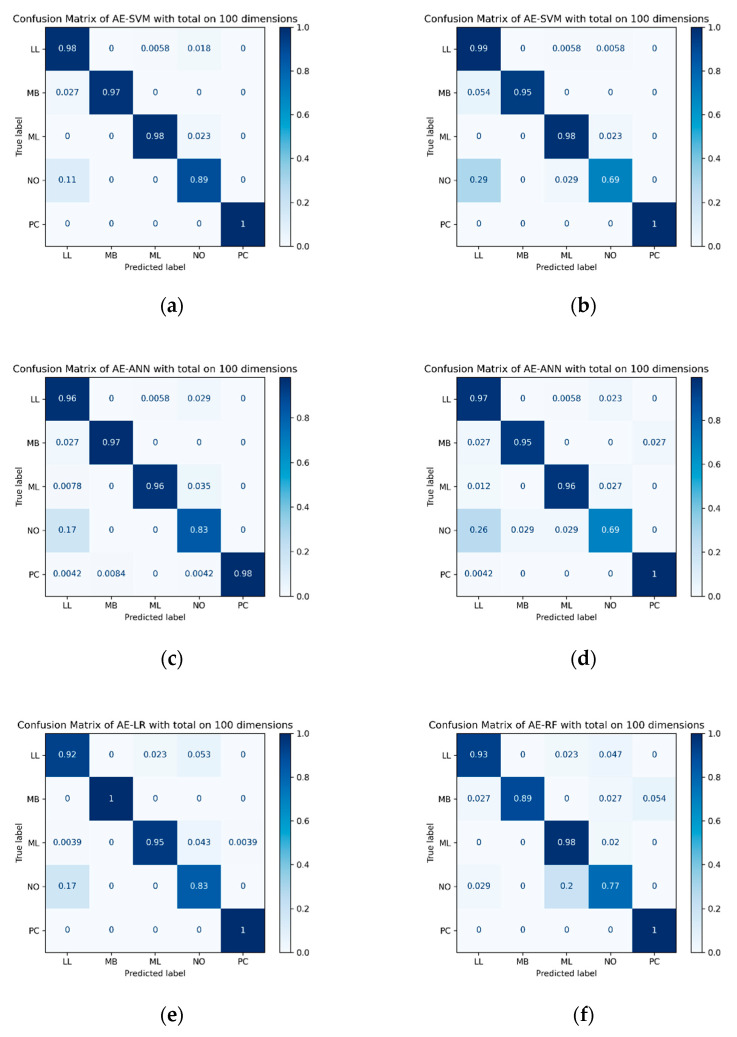
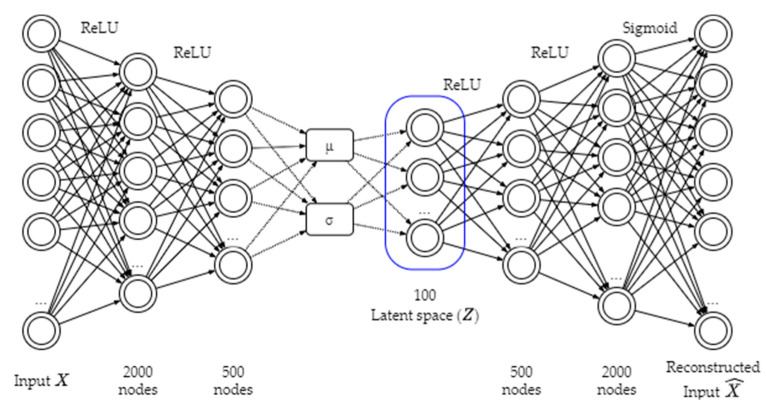
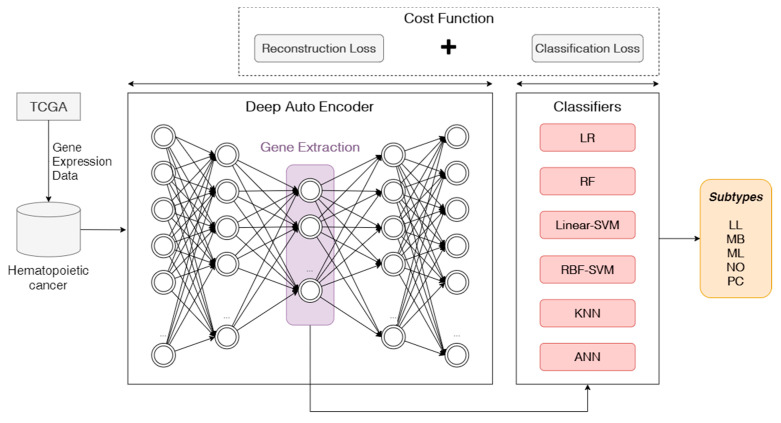
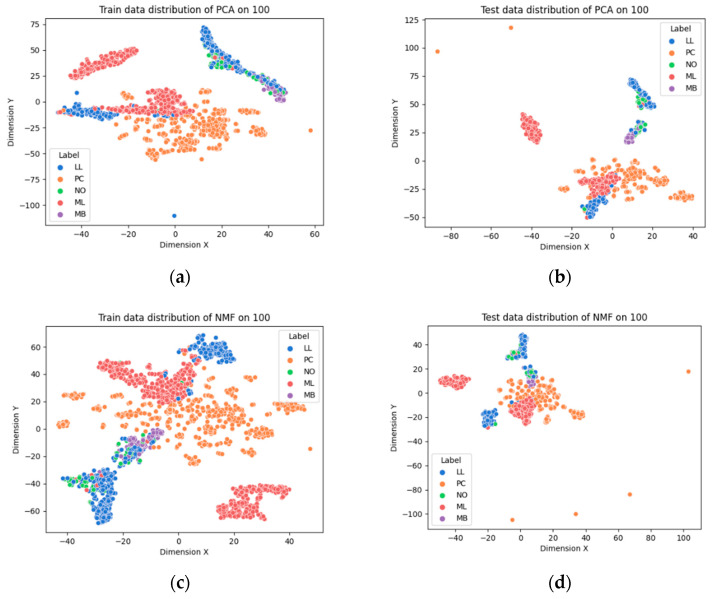
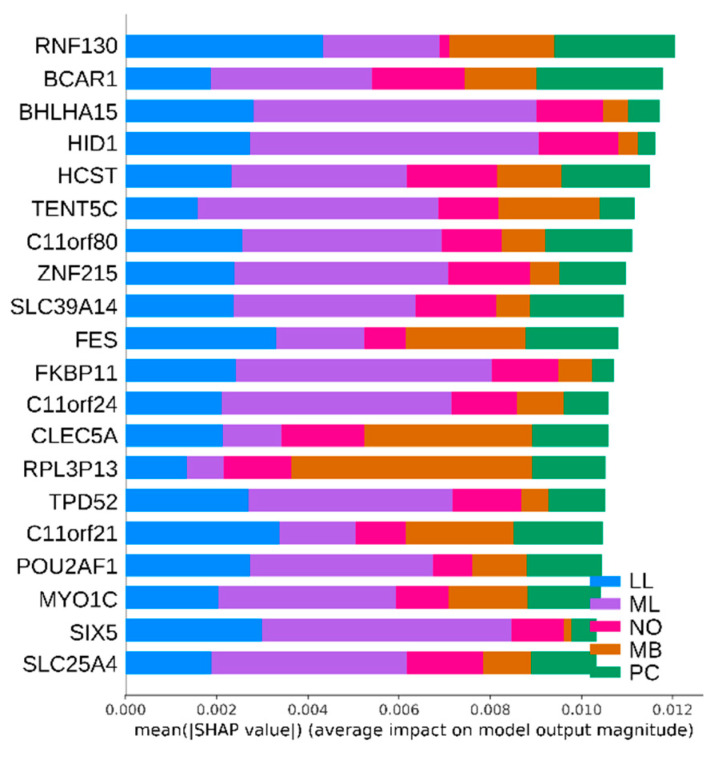
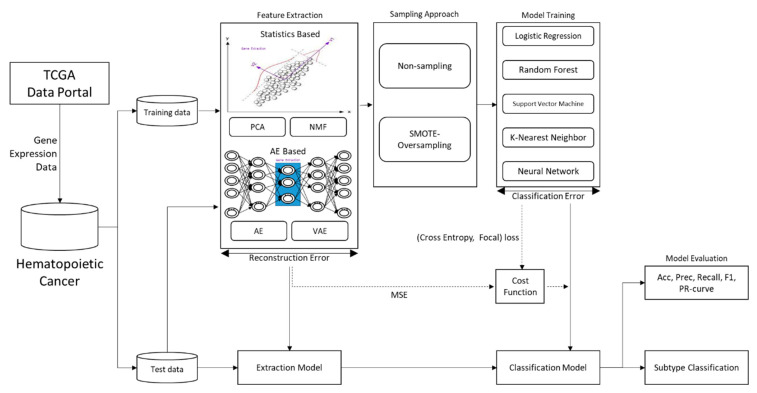
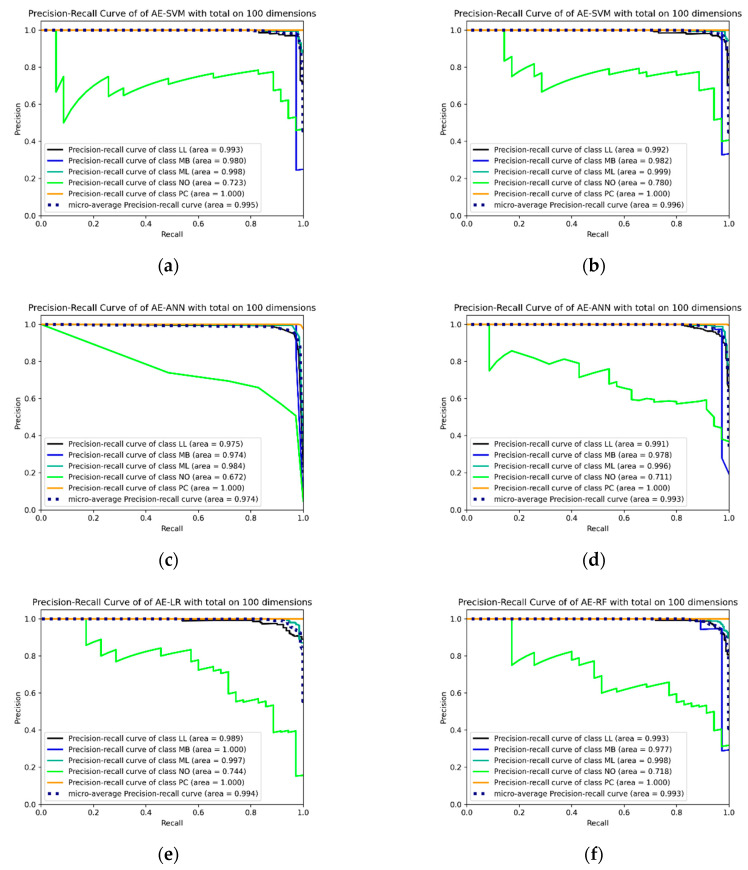
Hematopoietic cancer is a malignant transformation in immune system cells. Hematopoietic cancer is characterized by the cells that are expressed, so it is usually difficult to distinguish its heterogeneities in the hematopoiesis process. Traditional approaches for cancer subtyping use statistical techniques. Furthermore, due to the overfitting problem of small samples, in case of a minor cancer, it does not have enough sample material for building a classification model. Therefore, we propose not only to build a classification model for five major subtypes using two kinds of losses, namely reconstruction loss and classification loss, but also to extract suitable features using a deep autoencoder. Furthermore, for considering the data imbalance problem, we apply an oversampling algorithm, the synthetic minority oversampling technique (SMOTE). For validation of our proposed autoencoder-based feature extraction approach for hematopoietic cancer subtype classification, we compared other traditional feature selection algorithms (principal component analysis, non-negative matrix factorization) and classification algorithms with the SMOTE oversampling approach. Additionally, we used the Shapley Additive exPlanations (SHAP) interpretation technique in our model to explain the important gene/protein for hematopoietic cancer subtype classification. Furthermore, we compared five widely used classification algorithms, including logistic regression, random forest, k-nearest neighbor, artificial neural network and support vector machine. The results of autoencoder-based feature extraction approaches showed good performance, and the best result was the SMOTE oversampling-applied support vector machine algorithm consider both focal loss and reconstruction loss as the loss function for autoencoder (AE) feature selection approach, which produced 97.01% accuracy, 92.60% recall, 99.52% specificity, 93.54% F1-measure, 97.87% G-mean and 95.46% index of balanced accuracy as subtype classification performance measures.
造血系统癌症是免疫系统细胞的恶性转化。造血系统癌症的特征在于所表达的细胞,因此通常难以在造血过程中区分其异质性。传统的癌症亚型分类方法使用统计技术。此外,由于小样本的过拟合问题,在癌症较小的情况下,它没有足够的样本材料来构建分类模型。因此,我们不仅提出使用两种损失(即重构损失和分类损失)为五种主要亚型构建分类模型,而且还使用深度自动编码器提取合适的特征。此外,为了考虑数据不平衡问题,我们应用了过采样算法,即合成少数过采样技术(SMOTE)。为了验证我们提出的基于自动编码器的造血系统癌症亚型分类特征提取方法,我们将其他传统特征选择算法(主成分分析、非负矩阵分解)和分类算法与 SMOTE 过采样方法进行了比较。此外,我们在模型中使用 Shapley Additive exPlanations (SHAP) 解释技术来解释造血系统癌症亚型分类的重要基因/蛋白质。此外,我们比较了五种广泛使用的分类算法,包括逻辑回归、随机森林、k-最近邻、人工神经网络和支持向量机。基于自动编码器的特征提取方法的结果表现良好,最佳结果是 SMOTE 过采样应用于支持向量机算法,该算法将焦点损失和重构损失都作为自动编码器(AE)特征选择方法的损失函数,其分类性能指标为 97.01%的准确率、92.60%的召回率、99.52%的特异性、93.54%的 F1 度量、97.87%的 G-均值和 95.46%的平衡准确性指数。