University of Chinese Academy of Sciences, Beijing 101408, China.
Shenzhen Key Lab for High Performance Data Mining, Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences, Shenzhen 518055, China.
Int J Environ Res Public Health. 2022 Mar 9;19(6):3211. doi: 10.3390/ijerph19063211.
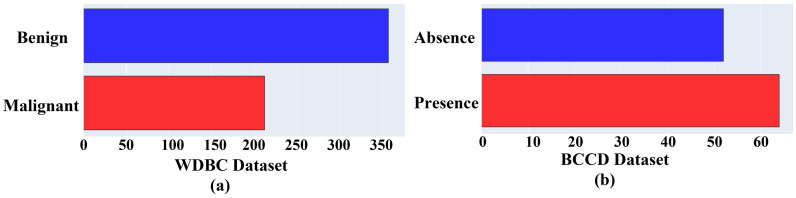
Breast cancer death rates are higher than any other cancer in American women. Machine learning-based predictive models promise earlier detection techniques for breast cancer diagnosis. However, making an evaluation for models that efficiently diagnose cancer is still challenging. In this work, we proposed data exploratory techniques (DET) and developed four different predictive models to improve breast cancer diagnostic accuracy. Prior to models, four-layered essential DET, e.g., feature distribution, correlation, elimination, and hyperparameter optimization, were deep-dived to identify the robust feature classification into malignant and benign classes. These proposed techniques and classifiers were implemented on the Wisconsin Diagnostic Breast Cancer (WDBC) and Breast Cancer Coimbra Dataset (BCCD) datasets. Standard performance metrics, including confusion matrices and K-fold cross-validation techniques, were applied to assess each classifier's efficiency and training time. The models' diagnostic capability improved with our DET, i.e., polynomial SVM gained 99.3%, LR with 98.06%, KNN acquired 97.35%, and EC achieved 97.61% accuracy with the WDBC dataset. We also compared our significant results with previous studies in terms of accuracy. The implementation procedure and findings can guide physicians to adopt an effective model for a practical understanding and prognosis of breast cancer tumors.
乳腺癌死亡率在美国女性中高于其他任何癌症。基于机器学习的预测模型有望为乳腺癌诊断提供更早的检测技术。然而,对于能够有效诊断癌症的模型进行评估仍然具有挑战性。在这项工作中,我们提出了数据探索技术(DET)并开发了四个不同的预测模型来提高乳腺癌诊断的准确性。在建立模型之前,我们深入研究了四层基本的 DET,例如特征分布、相关性、消除和超参数优化,以确定稳健的特征分类,将恶性和良性分类。这些提出的技术和分类器在威斯康星州诊断乳腺癌(WDBC)和科英布拉乳腺癌数据集(BCCD)上实现。应用标准性能指标,包括混淆矩阵和 K 折交叉验证技术,评估每个分类器的效率和训练时间。我们的 DET 提高了模型的诊断能力,例如多项式 SVM 获得了 99.3%,LR 获得了 98.06%,KNN 获得了 97.35%,EC 获得了 97.61%的准确率,WDBC 数据集。我们还根据准确性与之前的研究进行了比较。实施过程和结果可以指导医生采用有效的模型,以对乳腺癌肿瘤进行实际的了解和预后。