Tarbeeva Svetlana, Lyamtseva Ekaterina, Lisitsa Andrey, Kozlova Anna, Ponomarenko Elena, Ilgisonis Ekaterina
International School "Medicine of the Future", Sechenov University, 119991 Moscow, Russia.
Institute of Biomedical Chemistry, 119121 Moscow, Russia.
J Pers Med. 2021 Mar 29;11(4):246. doi: 10.3390/jpm11040246.
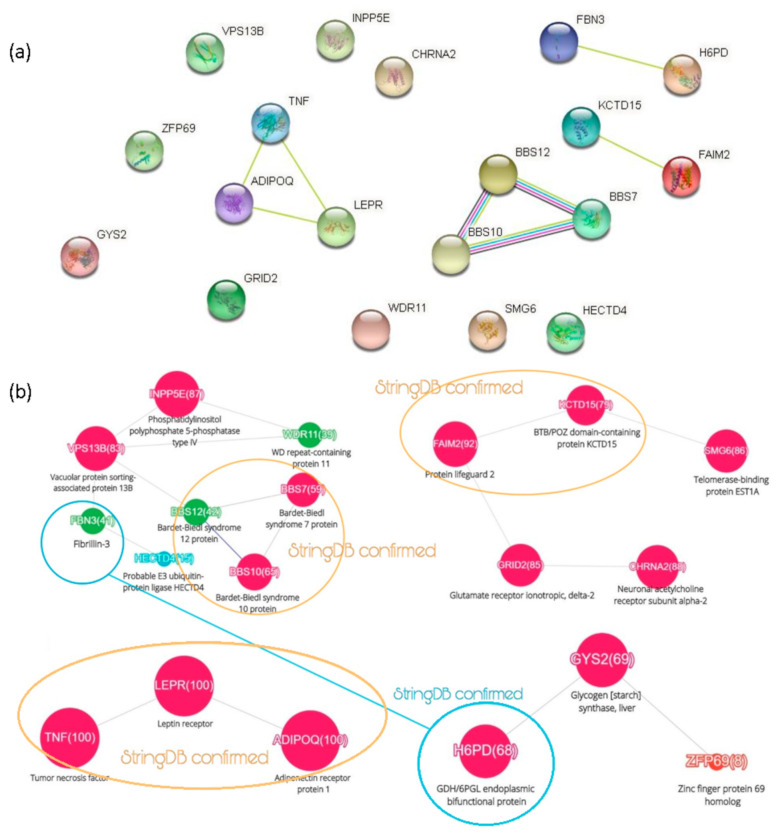
We used automatic text-mining of PubMed abstracts of papers related to obesity, with the aim of revealing that the information used in abstracts reflects the current understanding and key concepts of this widely explored problem. We compared expert data from DisGeNET to the results of an automated MeSH (Medical Subject Heading) search, which was performed by the ScanBious web tool. The analysis provided an overview of the obesity field, highlighting major trends such as physiological conditions, age, and diet, as well as key well-studied genes, such as adiponectin and its receptor. By intersecting the DisGeNET knowledge with the ScanBious results, we deciphered four clusters of obesity-related genes. An initial set of 100+ thousand abstracts and 622 genes was reduced to 19 genes, distributed among just a few groups: heredity, inflammation, intercellular signaling, and cancer. Rapid profiling of articles could drive personalized medicine: if the disease signs of a particular person were superimposed on a general network, then it would be possible to understand which are non-specific (observed in cohorts and, therefore, most likely have known treatment solutions) and which are less investigated, and probably represent a personalized case.
我们对与肥胖相关的论文的PubMed摘要进行了自动文本挖掘,目的是揭示摘要中使用的信息反映了这个广泛研究的问题的当前理解和关键概念。我们将来自DisGeNET的专家数据与由ScanBious网络工具执行的自动医学主题词(MeSH)搜索结果进行了比较。该分析提供了肥胖领域的概述,突出了生理状况、年龄和饮食等主要趋势,以及脂联素及其受体等经过充分研究的关键基因。通过将DisGeNET知识与ScanBious结果相交,我们破译了四组与肥胖相关的基因。最初的10万多篇摘要和622个基因被缩减至19个基因,分布在几个组中:遗传、炎症、细胞间信号传导和癌症。文章的快速分析可以推动个性化医疗:如果将特定个体的疾病体征叠加在一个通用网络上,那么就有可能了解哪些是非特异性的(在队列中观察到,因此很可能有已知的治疗方案),哪些是研究较少的,可能代表个性化病例。