Wattanapornprom Warin, Thammarongtham Chinae, Hongsthong Apiradee, Lertampaiporn Supatcha
Applied Computer Science Program, Department of Mathematics, Faculty of Science, King Mongkut's University of Technology Thonburi, Bangkok 10140, Thailand.
Biochemical Engineering and Systems Biology Research Group, National Center for Genetic Engineering and Biotechnology, National Science and Technology Development Agency at King Mongkut's University of Technology Thonburi, Tha Kham, Bang Khun Thian, Bangkok 10150, Thailand.
Life (Basel). 2021 Mar 30;11(4):293. doi: 10.3390/life11040293.
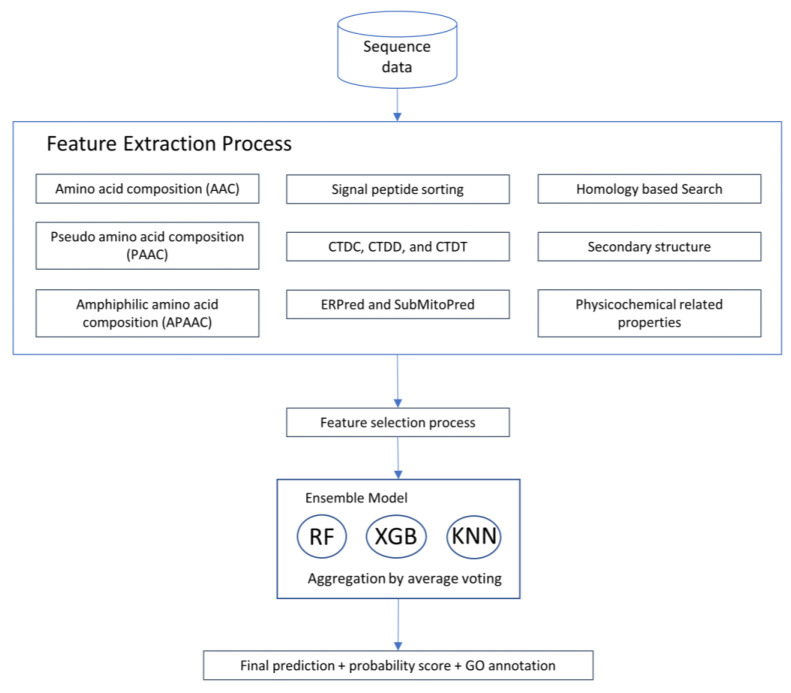
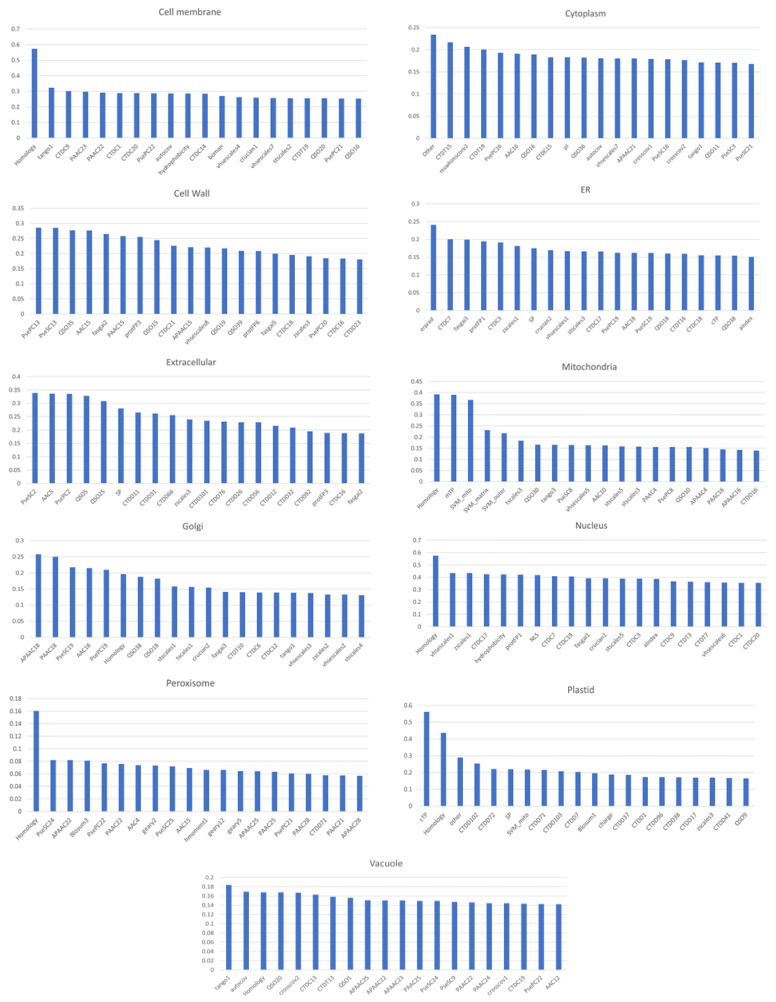
The accurate prediction of protein localization is a critical step in any functional genome annotation process. This paper proposes an improved strategy for protein subcellular localization prediction in plants based on multiple classifiers, to improve prediction results in terms of both accuracy and reliability. The prediction of plant protein subcellular localization is challenging because the underlying problem is not only a multiclass, but also a multilabel problem. Generally, plant proteins can be found in 10-14 locations/compartments. The number of proteins in some compartments (nucleus, cytoplasm, and mitochondria) is generally much greater than that in other compartments (vacuole, peroxisome, Golgi, and cell wall). Therefore, the problem of imbalanced data usually arises. Therefore, we propose an ensemble machine learning method based on average voting among heterogeneous classifiers. We first extracted various types of features suitable for each type of protein localization to form a total of 479 feature spaces. Then, feature selection methods were used to reduce the dimensions of the features into smaller informative feature subsets. This reduced feature subset was then used to train/build three different individual models. In the process of combining the three distinct classifier models, we used an average voting approach to combine the results of these three different classifiers that we constructed to return the final probability prediction. The method could predict subcellular localizations in both single- and multilabel locations, based on the voting probability. Experimental results indicated that the proposed ensemble method could achieve correct classification with an overall accuracy of 84.58% for 11 compartments, on the basis of the testing dataset.
准确预测蛋白质定位是任何功能基因组注释过程中的关键步骤。本文提出了一种基于多个分类器的改进策略,用于预测植物蛋白质的亚细胞定位,以提高预测结果的准确性和可靠性。植物蛋白质亚细胞定位的预测具有挑战性,因为潜在问题不仅是一个多类问题,也是一个多标签问题。一般来说,植物蛋白质可以在10 - 14个位置/区室中找到。某些区室(细胞核、细胞质和线粒体)中的蛋白质数量通常比其他区室(液泡、过氧化物酶体、高尔基体和细胞壁)中的多得多。因此,通常会出现数据不平衡的问题。因此,我们提出了一种基于异构分类器之间平均投票的集成机器学习方法。我们首先提取了适合每种蛋白质定位类型的各种特征,形成了总共479个特征空间。然后,使用特征选择方法将特征维度缩减为更小的信息丰富的特征子集。然后,使用这个缩减后的特征子集来训练/构建三个不同的个体模型。在组合这三个不同的分类器模型的过程中,我们使用平均投票方法来组合我们构建的这三个不同分类器的结果,以返回最终的概率预测。该方法可以基于投票概率预测单标签和多标签位置的亚细胞定位。实验结果表明,所提出的集成方法在测试数据集的基础上,对于11个区室能够以84.58%的总体准确率实现正确分类。