Department of Chemistry, Computational Life Science Cluster (CLiC), Umeå University, Umeå, Sweden.
Industrial Doctoral School (IDS), Umeå, Sweden.
BMC Bioinformatics. 2021 Apr 3;22(1):176. doi: 10.1186/s12859-021-04015-9.
For multivariate data analysis involving only two input matrices (e.g., X and Y), the previously published methods for variable influence on projection (e.g., VIP or VIP) are widely used for variable selection purposes, including (i) variable importance assessment, (ii) dimensionality reduction of big data and (iii) interpretation enhancement of PLS, OPLS and O2PLS models. For multiblock analysis, the OnPLS models find relationships among multiple data matrices (more than two blocks) by calculating latent variables; however, a method for improving the interpretation of these latent variables (model components) by assessing the importance of the input variables was not available up to now.
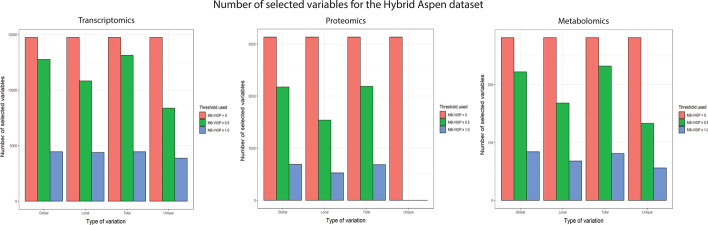
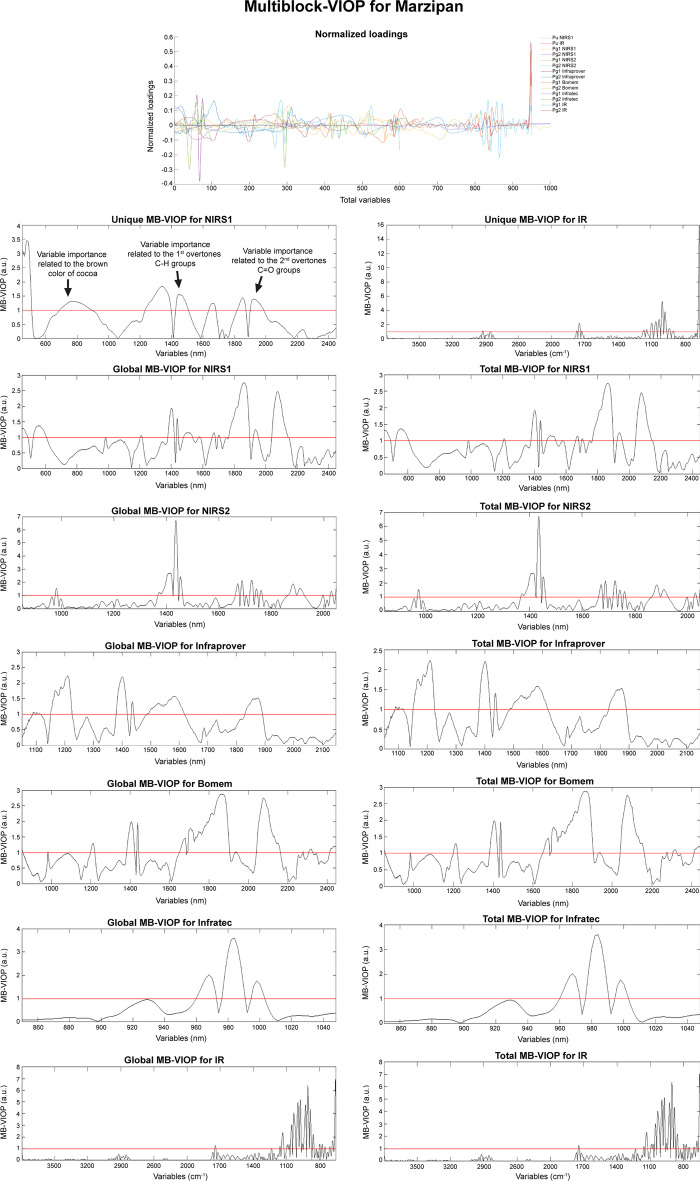
A method for variable selection in multiblock analysis, called multiblock variable influence on orthogonal projections (MB-VIOP) is explained in this paper. MB-VIOP is a model based variable selection method that uses the data matrices, the scores and the normalized loadings of an OnPLS model in order to sort the input variables of more than two data matrices according to their importance for both simplification and interpretation of the total multiblock model, and also of the unique, local and global model components separately. MB-VIOP has been tested using three datasets: a synthetic four-block dataset, a real three-block omics dataset related to plant sciences, and a real six-block dataset related to the food industry.
We provide evidence for the usefulness and reliability of MB-VIOP by means of three examples (one synthetic and two real-world cases). MB-VIOP assesses in a trustable and efficient way the importance of both isolated and ranges of variables in any type of data. MB-VIOP connects the input variables of different data matrices according to their relevance for the interpretation of each latent variable, yielding enhanced interpretability for each OnPLS model component. Besides, MB-VIOP can deal with strong overlapping of types of variation, as well as with many data blocks with very different dimensionality. The ability of MB-VIOP for generating dimensionality reduced models with high interpretability makes this method ideal for big data mining, multi-omics data integration and any study that requires exploration and interpretation of large streams of data.
对于仅涉及两个输入矩阵(例如 X 和 Y)的多元数据分析,先前发表的用于投影变量影响(例如 VIP 或 VIP)的方法广泛用于变量选择目的,包括(i)变量重要性评估,(ii)大数据降维和(iii)PLS、OPLS 和 O2PLS 模型的解释增强。对于多块分析,OnPLS 模型通过计算潜在变量来找到多个数据矩阵(两个以上块)之间的关系;然而,到目前为止,还没有一种方法可以通过评估输入变量的重要性来改进对这些潜在变量(模型组件)的解释。
本文解释了一种用于多块分析的变量选择方法,称为多块正交投影变量影响(MB-VIOP)。MB-VIOP 是一种基于模型的变量选择方法,它使用数据矩阵、得分和 OnPLS 模型的归一化载荷,以便根据其对总多块模型简化和解释的重要性,对两个以上数据矩阵的输入变量进行排序,还可以分别对独特的、局部的和全局的模型组件进行排序。MB-VIOP 已经使用三个数据集进行了测试:一个合成的四组数据集、一个与植物科学相关的真实三组组学数据集和一个与食品工业相关的真实六组数据集。
我们通过三个例子(一个合成的和两个真实的例子)提供了 MB-VIOP 有用性和可靠性的证据。MB-VIOP 以可靠且有效的方式评估了任何类型数据中孤立变量和变量范围的重要性。MB-VIOP 根据它们对每个潜在变量解释的相关性,将不同数据矩阵的输入变量连接起来,从而提高了每个 OnPLS 模型组件的可解释性。此外,MB-VIOP 可以处理类型变化的强烈重叠,以及具有非常不同维度的许多数据块。MB-VIOP 生成具有高可解释性的降维模型的能力使其成为大数据挖掘、多组学数据集成以及任何需要探索和解释大量数据流的研究的理想方法。