Loza Carlos A
Department of Mathematics, Universidad San Francisco de Quito, Quito, Ecuador.
PeerJ Comput Sci. 2019 May 13;5:e192. doi: 10.7717/peerj-cs.192. eCollection 2019.
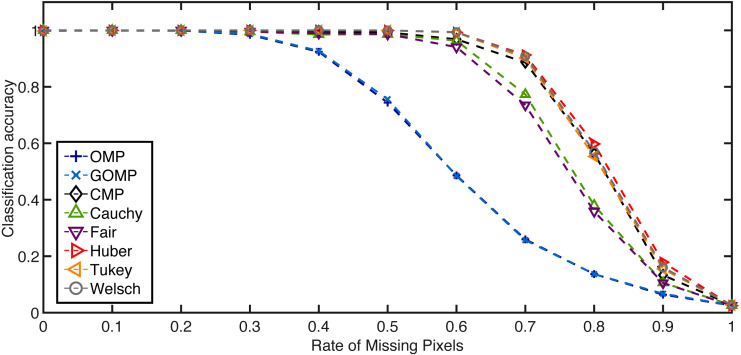
Sparse coding aims to find a parsimonious representation of an example given an observation matrix or dictionary. In this regard, Orthogonal Matching Pursuit (OMP) provides an intuitive, simple and fast approximation of the optimal solution. However, its main building block is anchored on the minimization of the Mean Squared Error cost function (MSE). This approach is only optimal if the errors are distributed according to a Gaussian distribution without samples that strongly deviate from the main mode, i.e. outliers. If such assumption is violated, the sparse code will likely be biased and performance will degrade accordingly. In this paper, we introduce five robust variants of OMP (RobOMP) fully based on the theory of M-Estimators under a linear model. The proposed framework exploits efficient Iteratively Reweighted Least Squares (IRLS) techniques to mitigate the effect of outliers and emphasize the samples corresponding to the main mode of the data. This is done adaptively via a learned weight vector that models the distribution of the data in a robust manner. Experiments on synthetic data under several noise distributions and image recognition under different combinations of occlusion and missing pixels thoroughly detail the superiority of RobOMP over MSE-based approaches and similar robust alternatives. We also introduce a denoising framework based on robust, sparse and redundant representations that open the door to potential further applications of the proposed techniques. The five different variants of RobOMP do not require parameter tuning from the user and, hence, constitute principled alternatives to OMP.
稀疏编码旨在在给定观测矩阵或字典的情况下找到示例的简洁表示。在这方面,正交匹配追踪(OMP)提供了最优解的直观、简单且快速的近似。然而,其主要构建块基于均方误差成本函数(MSE)的最小化。只有当误差根据高斯分布且没有强烈偏离主要模式的样本(即离群值)分布时,这种方法才是最优的。如果违反了这样的假设,稀疏编码可能会有偏差,性能也会相应下降。在本文中,我们完全基于线性模型下的M估计器理论引入了五种鲁棒的OMP变体(RobOMP)。所提出的框架利用高效的迭代加权最小二乘法(IRLS)技术来减轻离群值的影响,并强调与数据主要模式相对应的样本。这是通过一个学习到的权重向量以自适应方式完成的,该权重向量以鲁棒的方式对数据分布进行建模。在几种噪声分布下的合成数据以及不同遮挡和缺失像素组合下的图像识别实验充分详细地展示了RobOMP相对于基于MSE的方法和类似鲁棒替代方法的优越性。我们还引入了一个基于鲁棒、稀疏和冗余表示的去噪框架,为所提出技术的潜在进一步应用打开了大门。RobOMP的五种不同变体不需要用户进行参数调整,因此构成了OMP的有原则的替代方案。