Department of Control Science and Engineering, Xi'an University of Architecture and Technology, Xi'an, Shaanxi 710055, China.
Department of Computer Science, Air University, Islamabad, Pakistan.
J Healthc Eng. 2021 Mar 22;2021:5577636. doi: 10.1155/2021/5577636. eCollection 2021.
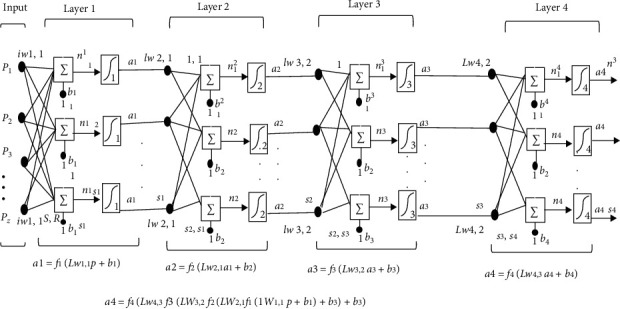
Multilabel recognition of morphological images and detection of cancerous areas are difficult to locate in the scenario of the image redundancy and less resolution. Cancerous tissues are incredibly tiny in various scenarios. Therefore, for automatic classification, the characteristics of cancer patches in the X-ray image are of critical importance. Due to the slight variation between the textures, using just one feature or using a few features contributes to inaccurate classification outcomes. The present study focuses on five different algorithms for extracting features that can extract further different features. The algorithms are GLCM, LBGLCM, LBP, GLRLM, and SFTA from 8 image groups, and then, the extracted feature spaces are combined. The dataset used for classification is most probably imbalanced. Additionally, another focal point is to eradicate the unbalanced data problem by creating more samples using the ADASYN algorithm so that the error rate is minimized and the accuracy is increased. By using the ReliefF algorithm, it skips less contributing features that relieve the burden on the process. Finally, the feedforward neural network is used for the classification of data. The proposed method showed 99.5% micro, 99.5% macro, 0.5% misclassification, 99.5% recall rats, specificity 99.4%, precision 99.5%, and accuracy 99.5%, showing its robustness in these results. To assess the feasibility of the new system, the INbreast database was used.
多标签识别形态图像和检测癌症区域在图像冗余和分辨率较低的情况下很难定位。在各种情况下,癌症组织都非常微小。因此,对于自动分类,X 射线图像中癌症斑块的特征至关重要。由于纹理之间的细微变化,仅使用一个特征或使用几个特征会导致分类结果不准确。本研究重点关注从 8 个图像组中提取特征的五种不同算法,然后组合提取的特征空间。用于分类的数据集很可能是不平衡的。此外,另一个重点是通过使用 ADASYN 算法创建更多样本来消除不平衡数据问题,从而最小化误差率并提高准确性。通过使用 ReliefF 算法,可以跳过减轻过程负担的贡献较小的特征。最后,使用前馈神经网络对数据进行分类。该方法在微分类中达到 99.5%、在宏分类中达到 99.5%、在错误分类中达到 0.5%、在召回率中达到 99.5%、在特异性中达到 99.4%、在精确率中达到 99.5%、在准确性中达到 99.5%,在这些结果中显示出其稳健性。为了评估新系统的可行性,使用了 INbreast 数据库。