He Jiayuan, Nguyen Dat Quoc, Akhondi Saber A, Druckenbrodt Christian, Thorne Camilo, Hoessel Ralph, Afzal Zubair, Zhai Zenan, Fang Biaoyan, Yoshikawa Hiyori, Albahem Ameer, Cavedon Lawrence, Cohn Trevor, Baldwin Timothy, Verspoor Karin
The University of Melbourne, Parkville, VIC, Australia.
RMIT University, Melbourne, VIC, Australia.
Front Res Metr Anal. 2021 Mar 25;6:654438. doi: 10.3389/frma.2021.654438. eCollection 2021.
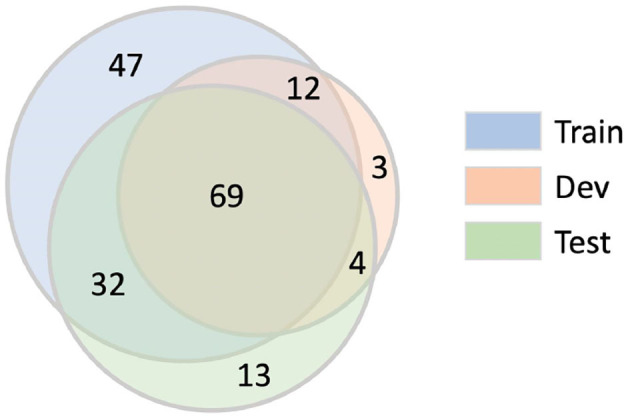
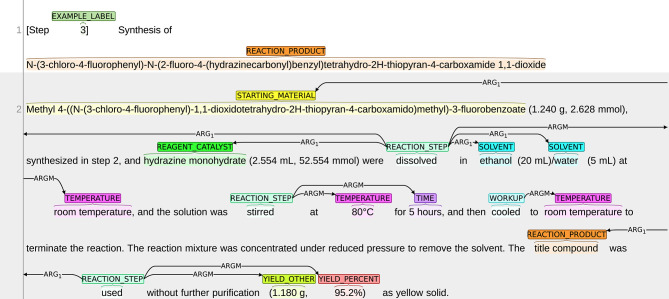
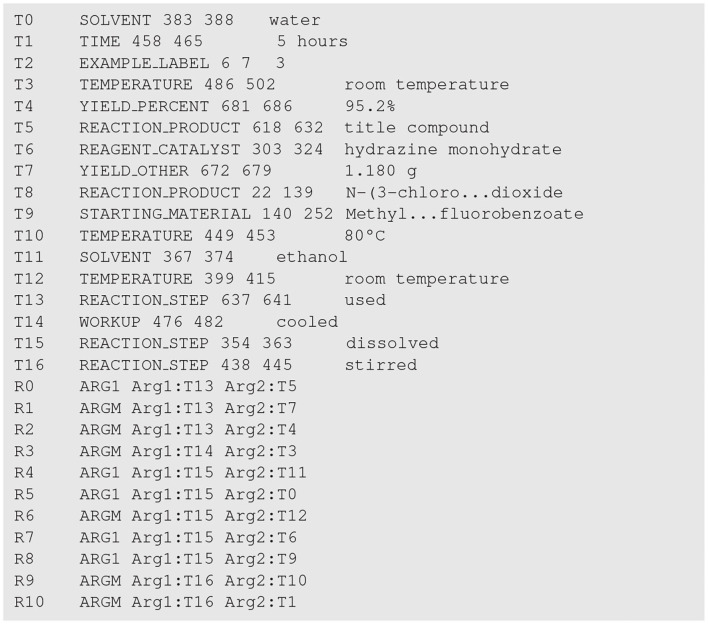
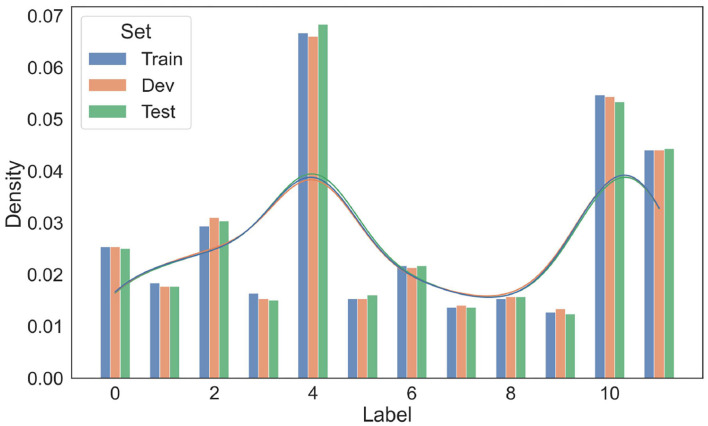
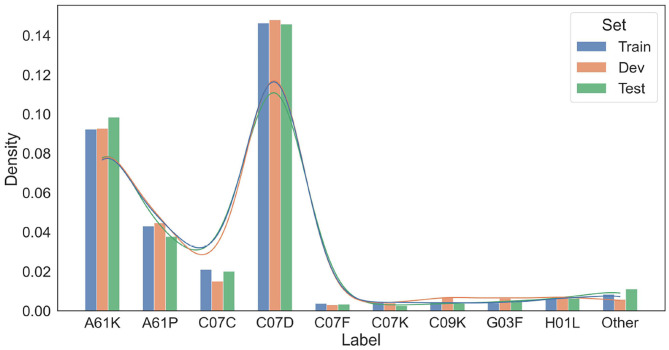
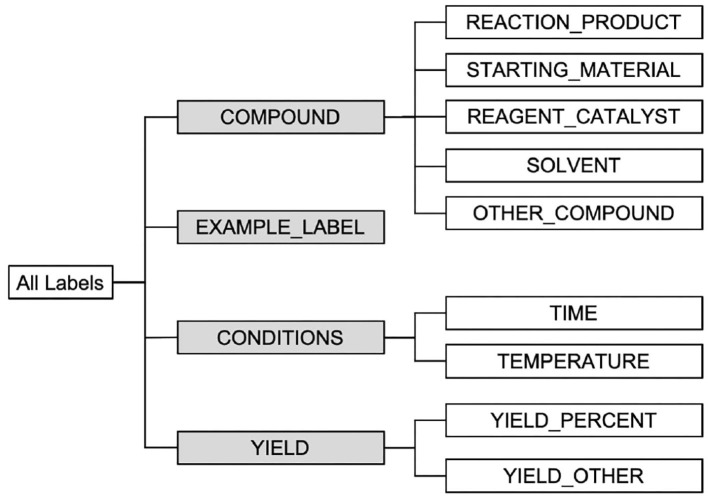
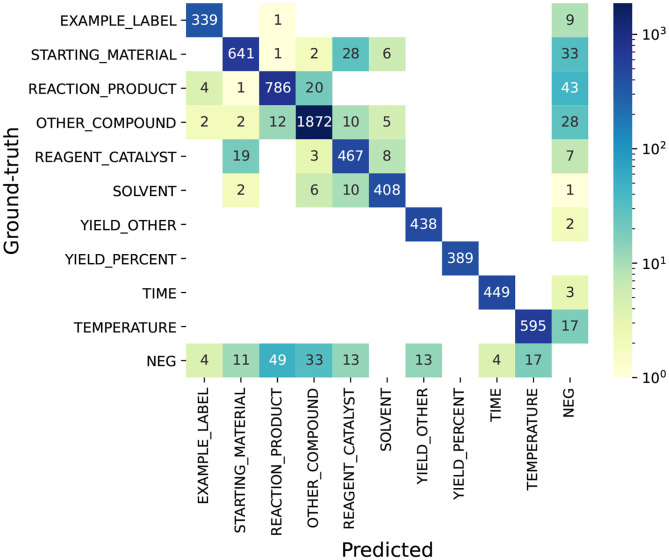
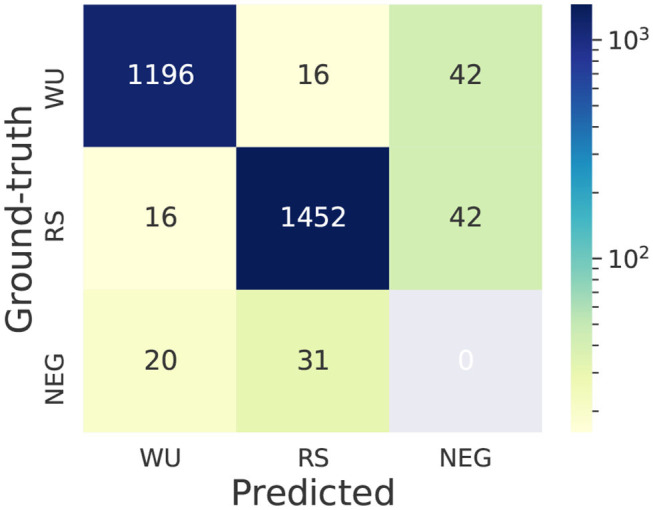
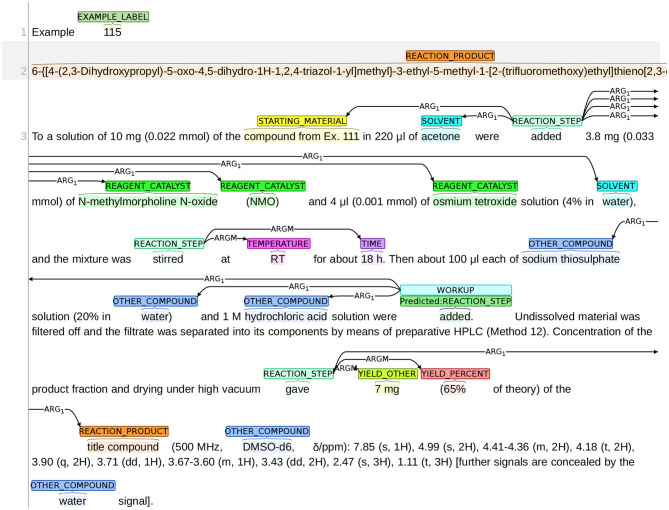
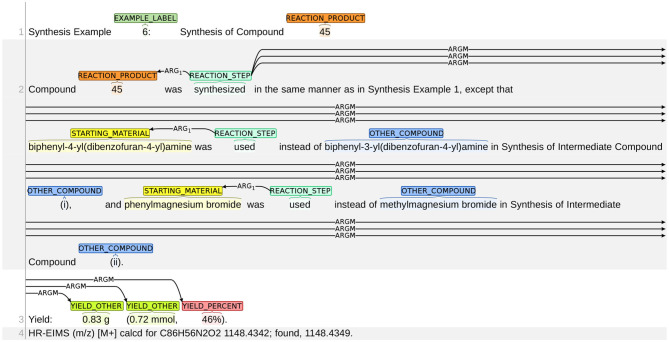
Chemical patents represent a valuable source of information about new chemical compounds, which is critical to the drug discovery process. Automated information extraction over chemical patents is, however, a challenging task due to the large volume of existing patents and the complex linguistic properties of chemical patents. The Cheminformatics Elsevier Melbourne University (ChEMU) evaluation lab 2020, part of the Conference and Labs of the Evaluation Forum 2020 (CLEF2020), was introduced to support the development of advanced text mining techniques for chemical patents. The ChEMU 2020 lab proposed two fundamental information extraction tasks focusing on chemical reaction processes described in chemical patents: (1) , requiring identification of essential chemical entities and their roles in chemical reactions, as well as reaction conditions; and (2) , which aims at identification of event steps relating the entities involved in chemical reactions. The ChEMU 2020 lab received 37 team registrations and 46 runs. Overall, the performance of submissions for these tasks exceeded our expectations, with the top systems outperforming strong baselines. We further show the methods to be robust to variations in sampling of the test data. We provide a detailed overview of the ChEMU 2020 corpus and its annotation, showing that inter-annotator agreement is very strong. We also present the methods adopted by participants, provide a detailed analysis of their performance, and carefully consider the potential impact of data leakage on interpretation of the results. The ChEMU 2020 Lab has shown the viability of automated methods to support information extraction of key information in chemical patents.
化学专利是有关新化学化合物的宝贵信息来源,这对药物研发过程至关重要。然而,由于现有专利数量庞大且化学专利具有复杂的语言特性,对化学专利进行自动信息提取是一项具有挑战性的任务。作为2020年评估论坛会议和实验室(CLEF2020)一部分的2020年化学信息学爱思唯尔墨尔本大学(ChEMU)评估实验室,旨在支持开发用于化学专利的先进文本挖掘技术。2020年ChEMU实验室提出了两项基本信息提取任务,重点关注化学专利中描述的化学反应过程:(1),要求识别基本化学实体及其在化学反应中的作用以及反应条件;(2),旨在识别与化学反应中涉及的实体相关的事件步骤。2020年ChEMU实验室收到了37个团队注册和46次运行结果。总体而言,这些任务的提交结果表现超出我们的预期,顶级系统的表现优于强大的基线。我们进一步表明这些方法对测试数据采样的变化具有鲁棒性。我们详细概述了2020年ChEMU语料库及其注释,表明注释者之间的一致性非常高。我们还介绍了参与者采用的方法,对他们的表现进行了详细分析,并仔细考虑了数据泄露对结果解释的潜在影响。2020年ChEMU实验室已证明自动化方法支持化学专利关键信息提取的可行性。