Cusack Siobhan A, Wang Peipei, Lotreck Serena G, Moore Bethany M, Meng Fanrui, Conner Jeffrey K, Krysan Patrick J, Lehti-Shiu Melissa D, Shiu Shin-Han
Cell and Molecular Biology Program, Michigan State University, East Lansing, MI, USA.
Department of Plant Biology, Michigan State University, East Lansing, MI, USA.
Mol Biol Evol. 2021 Jul 29;38(8):3397-3414. doi: 10.1093/molbev/msab111.
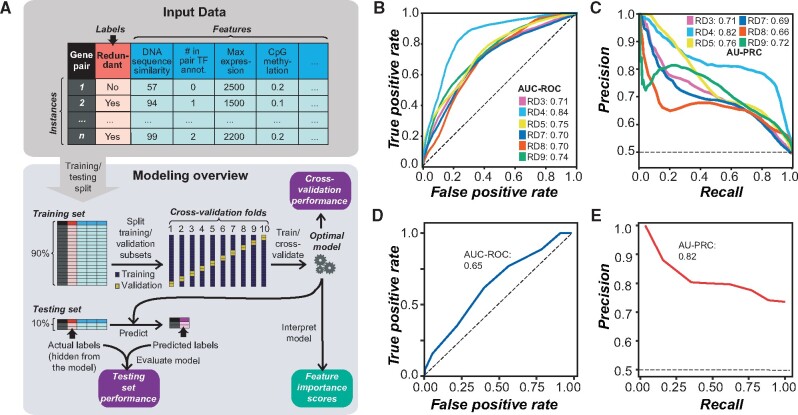
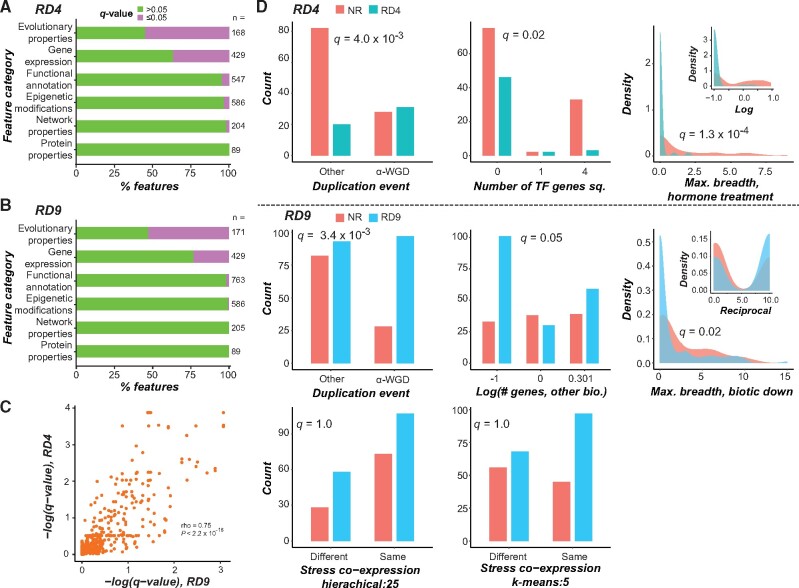
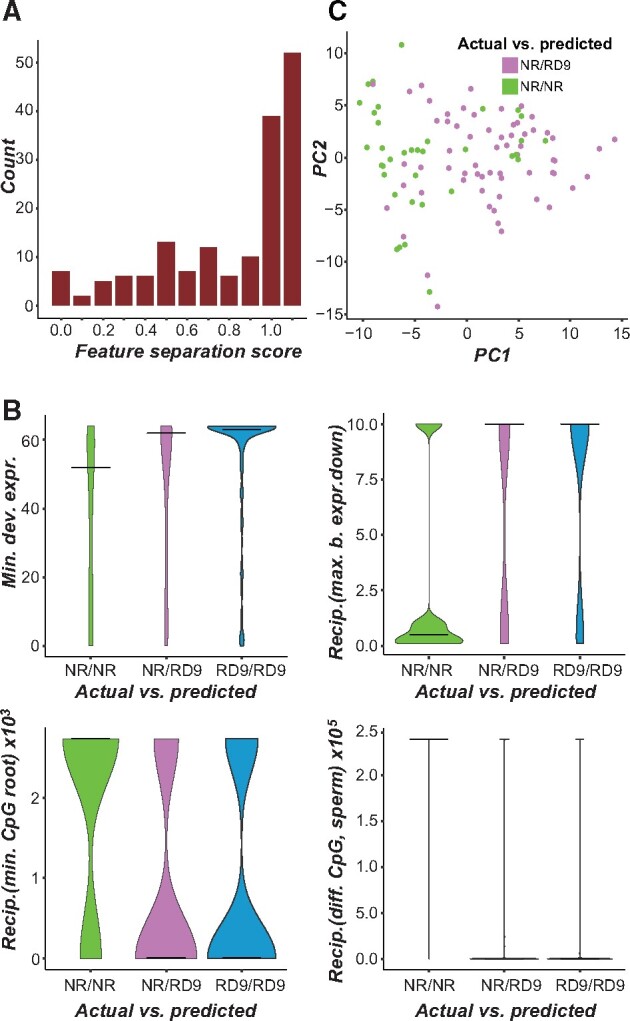
Genetic redundancy refers to a situation where an individual with a loss-of-function mutation in one gene (single mutant) does not show an apparent phenotype until one or more paralogs are also knocked out (double/higher-order mutant). Previous studies have identified some characteristics common among redundant gene pairs, but a predictive model of genetic redundancy incorporating a wide variety of features derived from accumulating omics and mutant phenotype data is yet to be established. In addition, the relative importance of these features for genetic redundancy remains largely unclear. Here, we establish machine learning models for predicting whether a gene pair is likely redundant or not in the model plant Arabidopsis thaliana based on six feature categories: functional annotations, evolutionary conservation including duplication patterns and mechanisms, epigenetic marks, protein properties including posttranslational modifications, gene expression, and gene network properties. The definition of redundancy, data transformations, feature subsets, and machine learning algorithms used significantly affected model performance based on holdout, testing phenotype data. Among the most important features in predicting gene pairs as redundant were having a paralog(s) from recent duplication events, annotation as a transcription factor, downregulation during stress conditions, and having similar expression patterns under stress conditions. We also explored the potential reasons underlying mispredictions and limitations of our studies. This genetic redundancy model sheds light on characteristics that may contribute to long-term maintenance of paralogs, and will ultimately allow for more targeted generation of functionally informative double mutants, advancing functional genomic studies.
基因冗余是指在一个基因中具有功能丧失突变的个体(单突变体)在一个或多个旁系同源基因也被敲除(双突变体/高阶突变体)之前不表现出明显表型的情况。先前的研究已经确定了冗余基因对之间的一些共同特征,但尚未建立一个整合从积累的组学和突变体表型数据中获得的各种特征的基因冗余预测模型。此外,这些特征对基因冗余的相对重要性在很大程度上仍不清楚。在此,我们基于六个特征类别建立了机器学习模型,用于预测模式植物拟南芥中的基因对是否可能冗余:功能注释、包括复制模式和机制的进化保守性、表观遗传标记、包括翻译后修饰的蛋白质特性、基因表达和基因网络特性。基于留出法测试表型数据,冗余的定义、数据转换、特征子集和使用的机器学习算法对模型性能有显著影响。预测基因对为冗余的最重要特征包括有来自近期复制事件的旁系同源基因、注释为转录因子、在胁迫条件下下调以及在胁迫条件下具有相似的表达模式。我们还探讨了错误预测的潜在原因和我们研究的局限性。这个基因冗余模型揭示了可能有助于旁系同源基因长期维持的特征,并最终将使功能信息丰富的双突变体的产生更具针对性,推动功能基因组学研究。