Miranda-Quintana Ramón Alain, Rácz Anita, Bajusz Dávid, Héberger Károly
Department of Chemistry, University of Florida, Gainesville, FL, 32603, USA.
Plasma Chemistry Research Group, Research Centre for Natural Sciences, Magyar tudósok krt. 2, 1117, Budapest, Hungary.
J Cheminform. 2021 Apr 23;13(1):33. doi: 10.1186/s13321-021-00504-4.
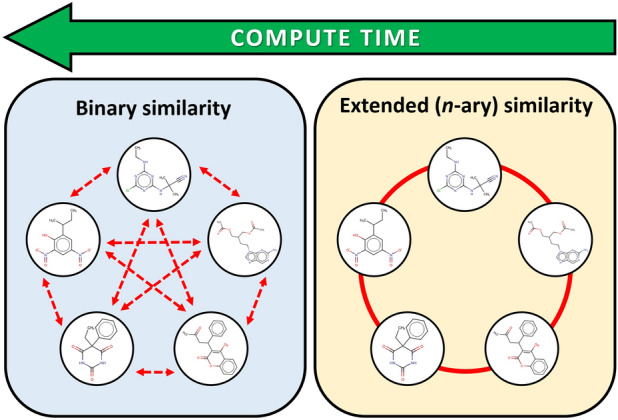
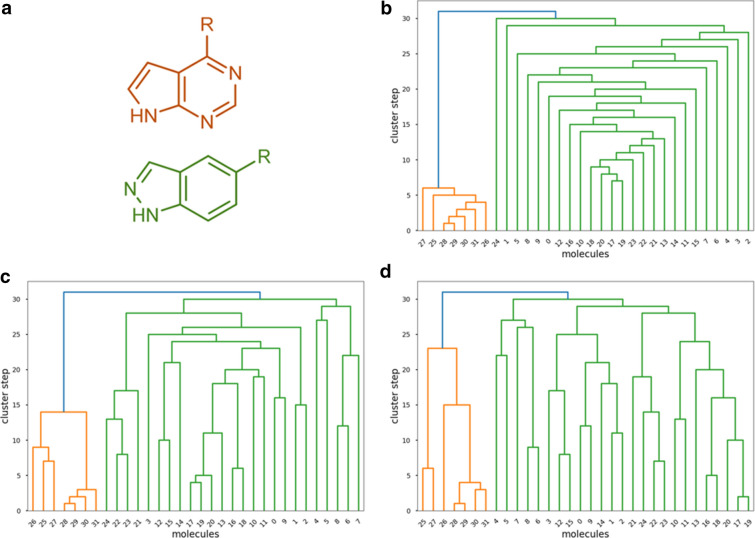
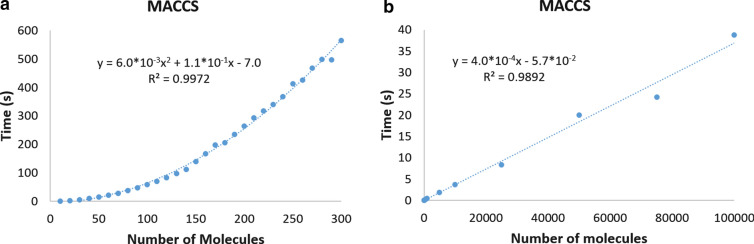
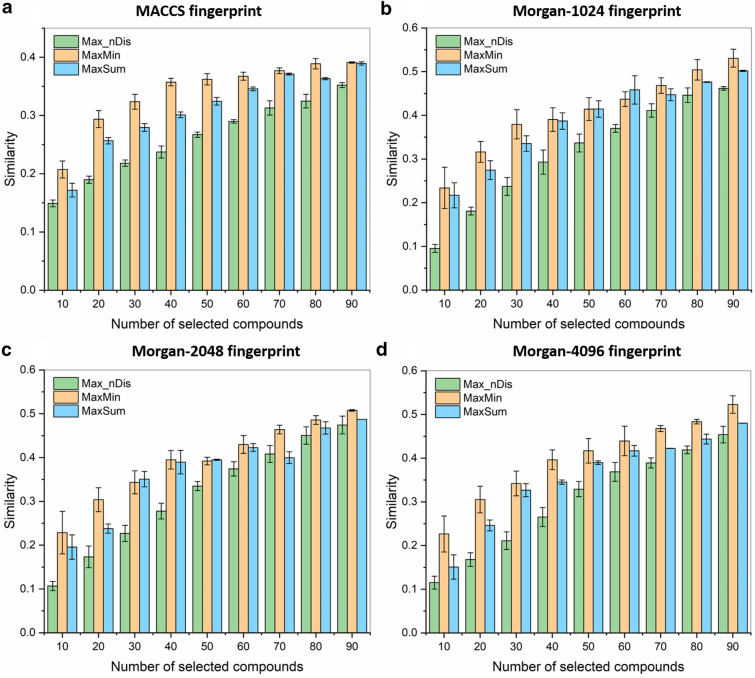
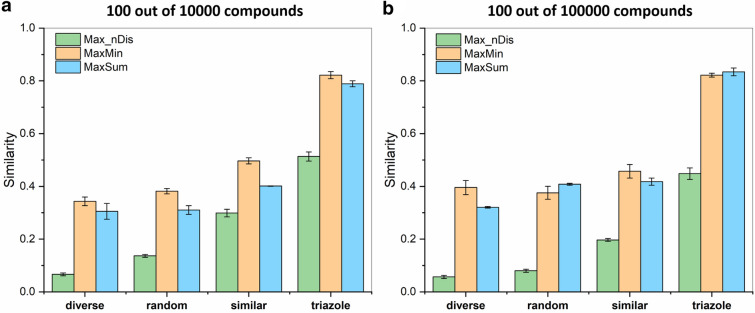
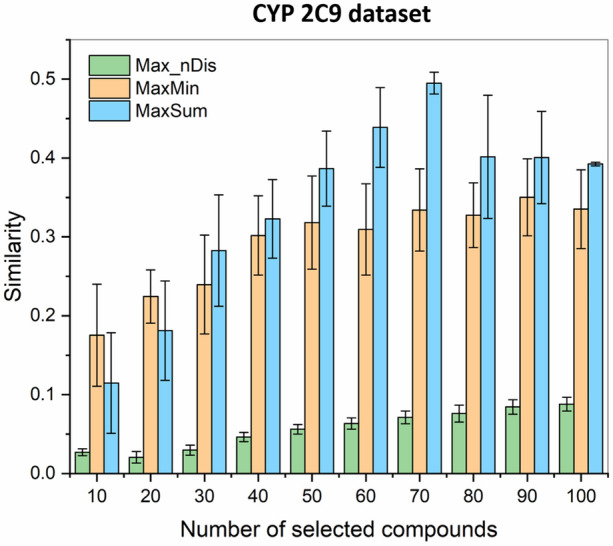
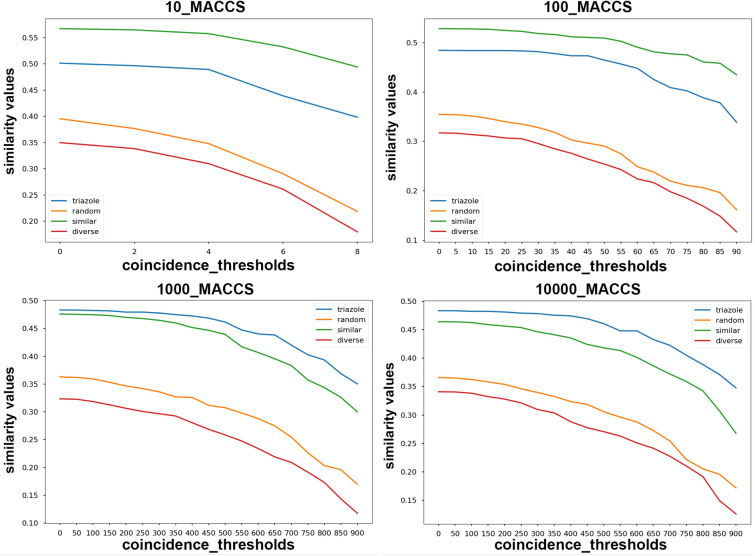
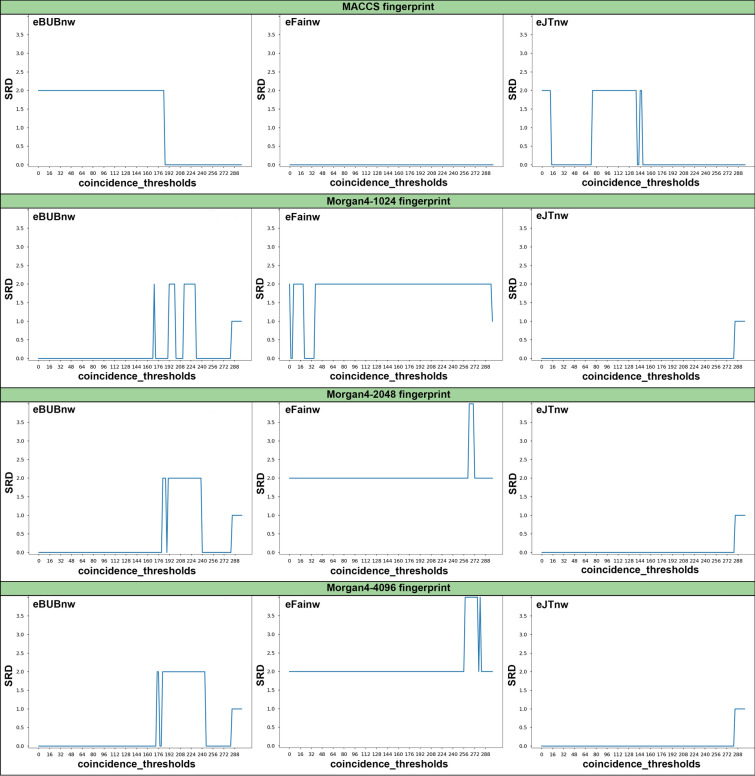
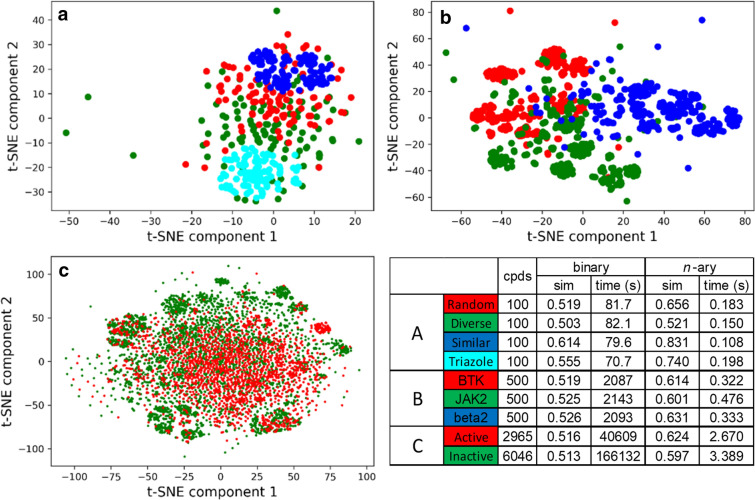
Despite being a central concept in cheminformatics, molecular similarity has so far been limited to the simultaneous comparison of only two molecules at a time and using one index, generally the Tanimoto coefficent. In a recent contribution we have not only introduced a complete mathematical framework for extended similarity calculations, (i.e. comparisons of more than two molecules at a time) but defined a series of novel idices. Part 1 is a detailed analysis of the effects of various parameters on the similarity values calculated by the extended formulas. Their features were revealed by sum of ranking differences and ANOVA. Here, in addition to characterizing several important aspects of the newly introduced similarity metrics, we will highlight their applicability and utility in real-life scenarios using datasets with popular molecular fingerprints. Remarkably, for large datasets, the use of extended similarity measures provides an unprecedented speed-up over "traditional" pairwise similarity matrix calculations. We also provide illustrative examples of a more direct algorithm based on the extended Tanimoto similarity to select diverse compound sets, resulting in much higher levels of diversity than traditional approaches. We discuss the inner and outer consistency of our indices, which are key in practical applications, showing whether the n-ary and binary indices rank the data in the same way. We demonstrate the use of the new n-ary similarity metrics on t-distributed stochastic neighbor embedding (t-SNE) plots of datasets of varying diversity, or corresponding to ligands of different pharmaceutical targets, which show that our indices provide a better measure of set compactness than standard binary measures. We also present a conceptual example of the applicability of our indices in agglomerative hierarchical algorithms. The Python code for calculating the extended similarity metrics is freely available at: https://github.com/ramirandaq/MultipleComparisons.
尽管分子相似性是化学信息学中的核心概念,但迄今为止,它仅限于一次仅对两个分子进行同时比较,并使用一个指标,通常是塔尼莫托系数。在最近的一篇论文中,我们不仅引入了用于扩展相似性计算(即一次比较两个以上分子)的完整数学框架,还定义了一系列新指标。第1部分详细分析了各种参数对扩展公式计算出的相似性值的影响。通过排名差异总和和方差分析揭示了它们的特征。在这里,除了描述新引入的相似性度量的几个重要方面外,我们还将使用具有流行分子指纹的数据集,突出它们在实际场景中的适用性和实用性。值得注意的是,对于大型数据集,使用扩展相似性度量比“传统”成对相似性矩阵计算提供了前所未有的加速。我们还提供了一个基于扩展塔尼莫托相似性的更直接算法的示例,用于选择不同的化合物集,从而产生比传统方法更高的多样性水平。我们讨论了我们的指标的内部和外部一致性,这在实际应用中至关重要,展示了n元指标和二元指标对数据的排名方式是否相同。我们展示了新的n元相似性度量在不同多样性数据集或对应于不同药物靶点配体的t分布随机邻域嵌入(t-SNE)图上的使用,这表明我们的指标比标准二元度量提供了更好的集合紧凑性度量。我们还给出了我们的指标在凝聚层次算法中的适用性的概念示例。用于计算扩展相似性度量的Python代码可在以下网址免费获取:https://github.com/ramirandaq/MultipleComparisons 。