Biostatistics Branch, Division of Cancer Epidemiology and Genetics, National Cancer Institute, Rockville, Maryland, USA.
Department of Mathematics and Statistics, University of Maryland, Baltimore County, Baltimore, Maryland, USA.
Stat Med. 2021 Jul 30;40(17):3865-3880. doi: 10.1002/sim.9003. Epub 2021 Apr 28.
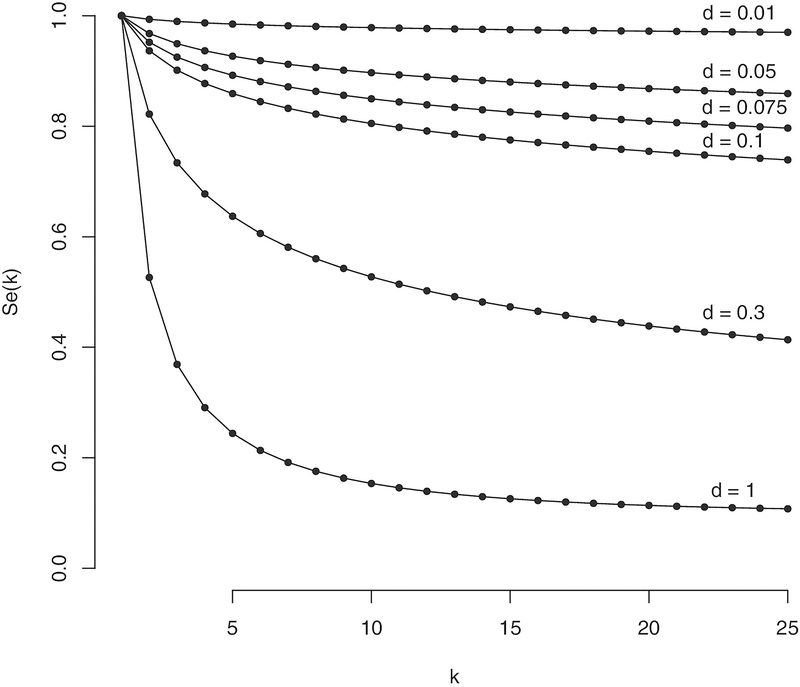
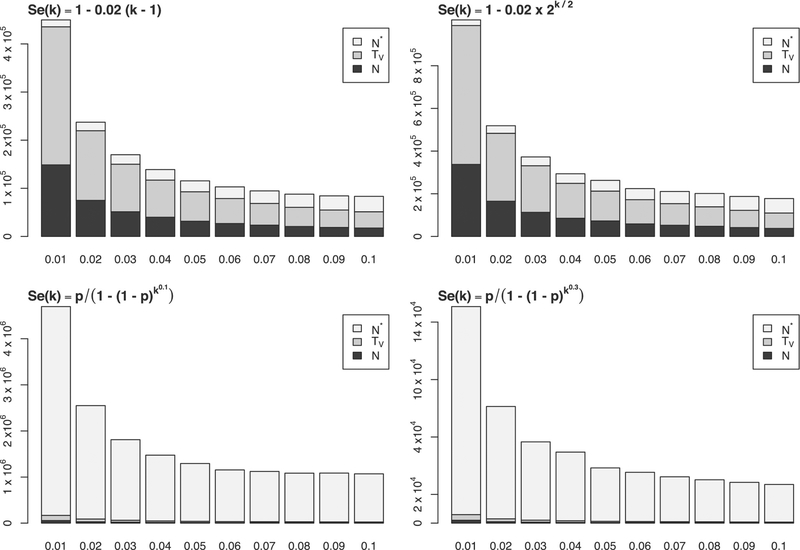
Large-scale disease screening is a complicated process in which high costs must be balanced against pressing public health needs. When the goal is screening for infectious disease, one approach is group testing in which samples are initially tested in pools and individual samples are retested only if the initial pooled test was positive. Intuitively, if the prevalence of infection is small, this could result in a large reduction of the total number of tests required. Despite this, the use of group testing in medical studies has been limited, largely due to skepticism about the impact of pooling on the accuracy of a given assay. While there is a large body of research addressing the issue of testing errors in group testing studies, it is customary to assume that the misclassification parameters are known from an external population and/or that the values do not change with the group size. Both of these assumptions are highly questionable for many medical practitioners considering group testing in their study design. In this article, we explore how the failure of these assumptions might impact the efficacy of a group testing design and, consequently, whether group testing is currently feasible for medical screening. Specifically, we look at how incorrect assumptions about the sensitivity function at the design stage can lead to poor estimation of a procedure's overall sensitivity and expected number of tests. Furthermore, if a validation study is used to estimate the pooled misclassification parameters of a given assay, we show that the sample sizes required are so large as to be prohibitive in all but the largest screening programs.
大规模疾病筛查是一个复杂的过程,必须在高昂的成本和紧迫的公共卫生需求之间进行平衡。当目标是筛查传染病时,一种方法是群体检测,即最初将样本在池子里进行检测,如果初始的 pooled 检测呈阳性,则只对个体样本进行复测。直观地说,如果感染的流行率很小,这可能会导致所需的总测试数量大幅减少。尽管如此,群体检测在医学研究中的应用仍然有限,主要是由于对 pooling 对特定检测准确性的影响存在怀疑。虽然有大量研究解决了群体检测研究中的检测错误问题,但通常假设误分类参数是从外部群体中已知的,或者这些值不会随群体大小而改变。对于许多考虑在其研究设计中进行群体检测的医学从业者来说,这两个假设都是非常值得怀疑的。在本文中,我们探讨了这些假设的失败可能如何影响群体检测设计的效果,以及群体检测是否目前可用于医学筛查。具体来说,我们研究了设计阶段对灵敏度函数的错误假设如何导致对程序总体灵敏度和预期测试次数的估计不佳。此外,如果使用验证研究来估计给定检测的 pooled 误分类参数,我们将表明,所需的样本量非常大,以至于除了最大的筛查计划之外,所有计划都无法实施。