Palacios Carlos A, Reyes-Suárez José A, Bearzotti Lorena A, Leiva Víctor, Marchant Carolina
Departamento de Obras Civiles, Universidad Católica del Maule, Talca 3480112, Chile.
Programa de Magíster en Gestión de Operaciones, Facultad de Ingeniería, Universidad de Talca, Curicó 3344158, Chile.
Entropy (Basel). 2021 Apr 20;23(4):485. doi: 10.3390/e23040485.
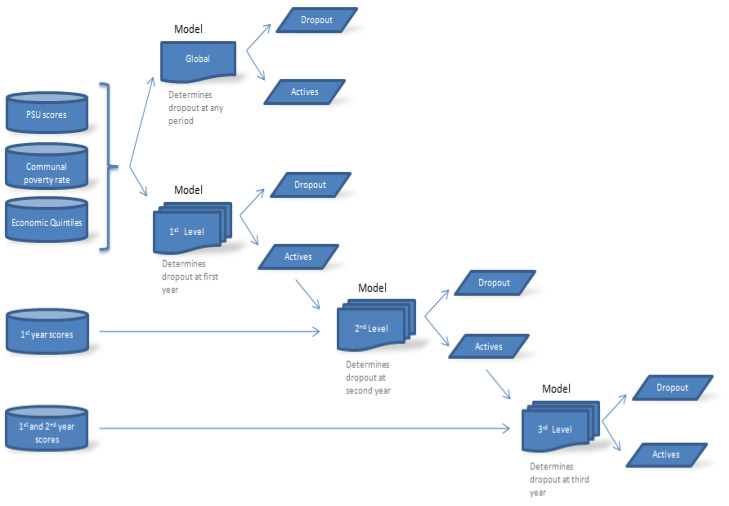
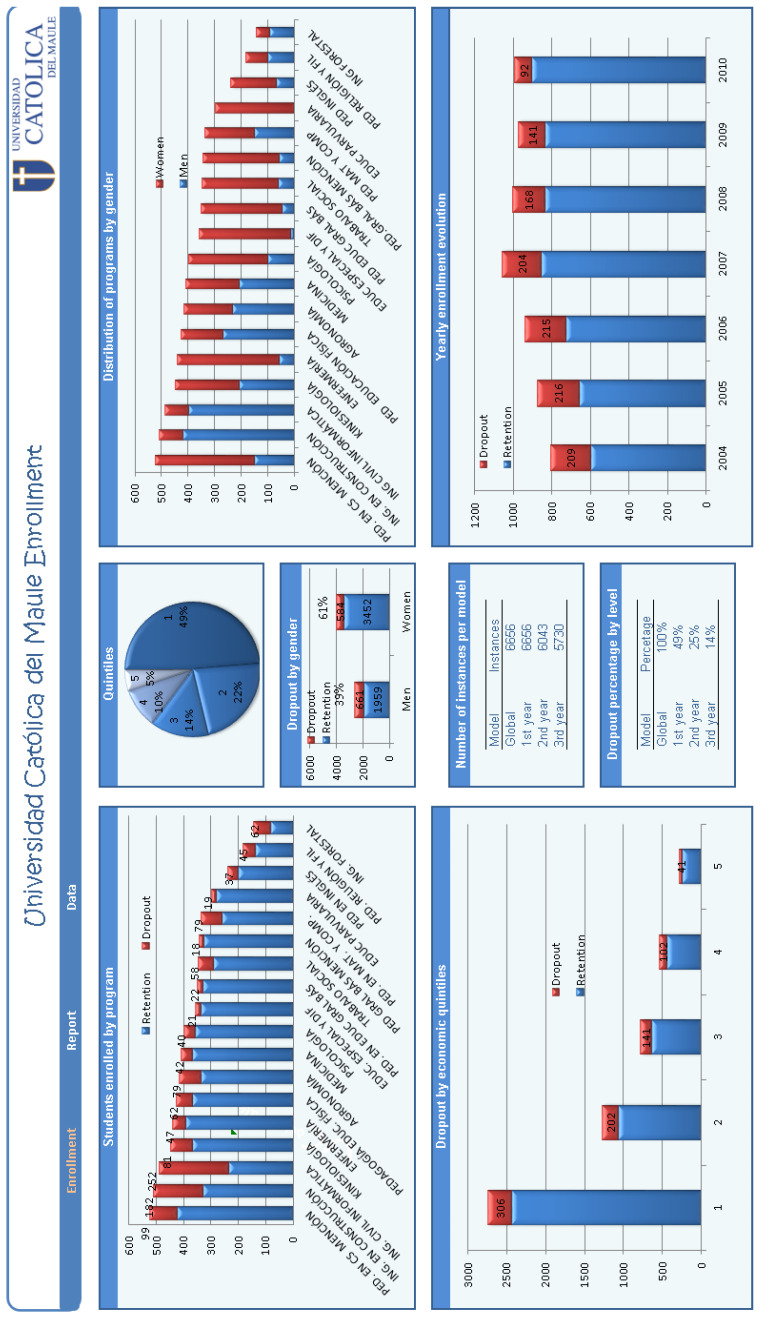
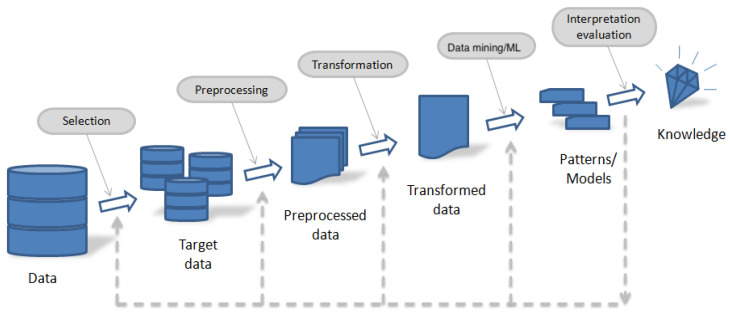
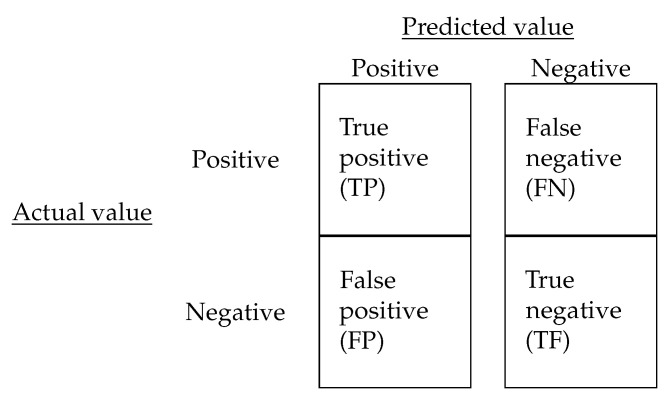
Data mining is employed to extract useful information and to detect patterns from often large data sets, closely related to knowledge discovery in databases and data science. In this investigation, we formulate models based on machine learning algorithms to extract relevant information predicting student retention at various levels, using higher education data and specifying the relevant variables involved in the modeling. Then, we utilize this information to help the process of knowledge discovery. We predict student retention at each of three levels during their first, second, and third years of study, obtaining models with an accuracy that exceeds 80% in all scenarios. These models allow us to adequately predict the level when dropout occurs. Among the machine learning algorithms used in this work are: decision trees, -nearest neighbors, logistic regression, naive Bayes, random forest, and support vector machines, of which the random forest technique performs the best. We detect that secondary educational score and the community poverty index are important predictive variables, which have not been previously reported in educational studies of this type. The dropout assessment at various levels reported here is valid for higher education institutions around the world with similar conditions to the Chilean case, where dropout rates affect the efficiency of such institutions. Having the ability to predict dropout based on student's data enables these institutions to take preventative measures, avoiding the dropouts. In the case study, balancing the majority and minority classes improves the performance of the algorithms.
数据挖掘用于从通常庞大的数据集中提取有用信息并检测模式,这与数据库中的知识发现和数据科学密切相关。在本研究中,我们基于机器学习算法构建模型,利用高等教育数据并指定建模中涉及的相关变量,以提取预测不同层次学生留校情况的相关信息。然后,我们利用这些信息来助力知识发现过程。我们预测学生在学习的第一年、第二年和第三年三个层次中的每个层次的留校情况,在所有情况下都获得了准确率超过80%的模型。这些模型使我们能够充分预测辍学发生时的层次。本研究使用的机器学习算法包括:决策树、k近邻、逻辑回归、朴素贝叶斯、随机森林和支持向量机,其中随机森林技术表现最佳。我们发现中学教育成绩和社区贫困指数是重要的预测变量,此前在这类教育研究中尚未有过报道。这里报告的不同层次的辍学评估对于世界各地与智利情况类似的高等教育机构是有效的,在智利,辍学率会影响这些机构的效率。能够根据学生数据预测辍学情况使这些机构能够采取预防措施,避免学生辍学。在案例研究中,平衡多数类和少数类可提高算法的性能。