Yu Amy Y X, Liu Zhongyu A, Pou-Prom Chloe, Lopes Kaitlyn, Kapral Moira K, Aviv Richard I, Mamdani Muhammad
Department of Medicine (Neurology), University of Toronto - Sunnybrook Health Sciences Centre, Toronto, ON, Canada.
Unity Health Toronto, Toronto, ON, Canada.
JMIR Med Inform. 2021 May 4;9(5):e24381. doi: 10.2196/24381.
Diagnostic neurovascular imaging data are important in stroke research, but obtaining these data typically requires laborious manual chart reviews.
We aimed to determine the accuracy of a natural language processing (NLP) approach to extract information on the presence and location of vascular occlusions as well as other stroke-related attributes based on free-text reports.
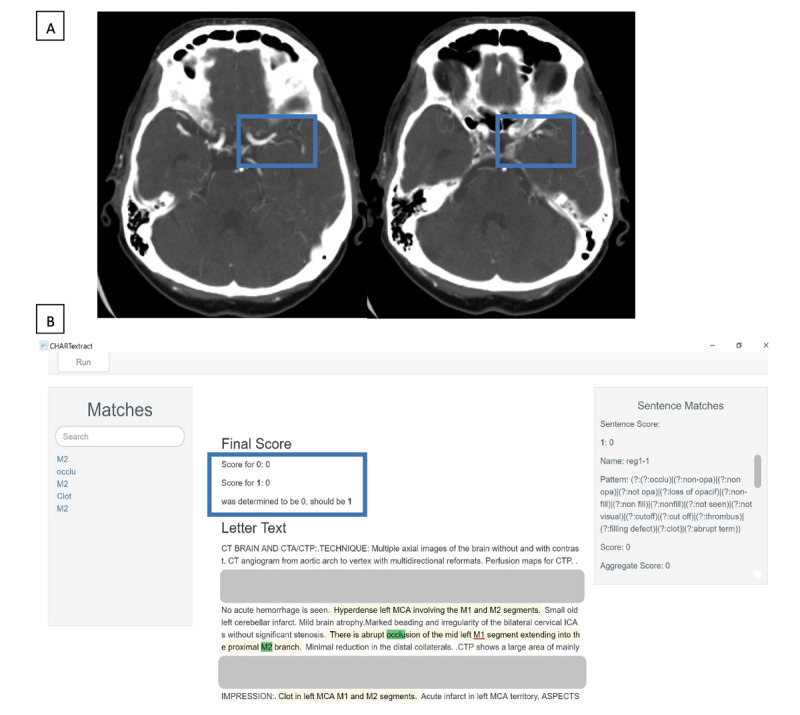
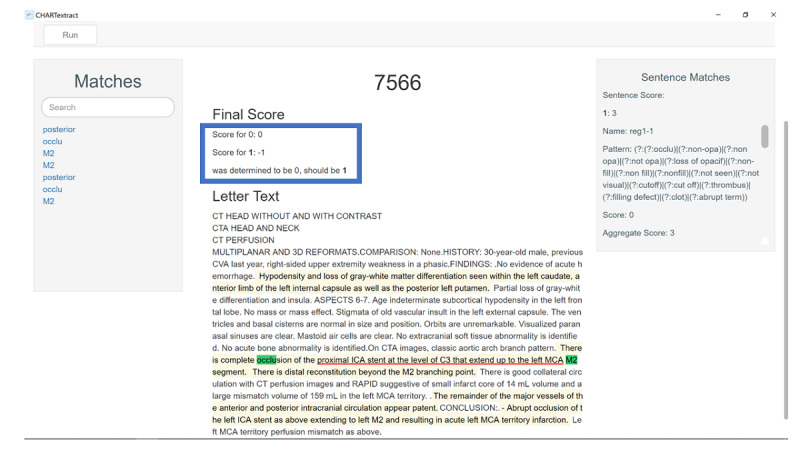
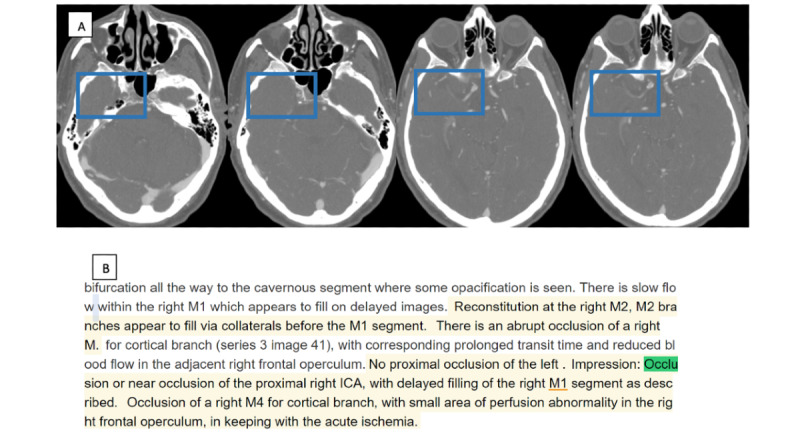
From the full reports of 1320 consecutive computed tomography (CT), CT angiography, and CT perfusion scans of the head and neck performed at a tertiary stroke center between October 2017 and January 2019, we manually extracted data on the presence of proximal large vessel occlusion (primary outcome), as well as distal vessel occlusion, ischemia, hemorrhage, Alberta stroke program early CT score (ASPECTS), and collateral status (secondary outcomes). Reports were randomly split into training (n=921) and validation (n=399) sets, and attributes were extracted using rule-based NLP. We reported the sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV), and the overall accuracy of the NLP approach relative to the manually extracted data.
The overall prevalence of large vessel occlusion was 12.2%. In the training sample, the NLP approach identified this attribute with an overall accuracy of 97.3% (95.5% sensitivity, 98.1% specificity, 84.1% PPV, and 99.4% NPV). In the validation set, the overall accuracy was 95.2% (90.0% sensitivity, 97.4% specificity, 76.3% PPV, and 98.5% NPV). The accuracy of identifying distal or basilar occlusion as well as hemorrhage was also high, but there were limitations in identifying cerebral ischemia, ASPECTS, and collateral status.
NLP may improve the efficiency of large-scale imaging data collection for stroke surveillance and research.
诊断性神经血管成像数据在中风研究中很重要,但获取这些数据通常需要费力的人工图表审查。
我们旨在确定一种自然语言处理(NLP)方法的准确性,该方法基于自由文本报告提取血管闭塞的存在和位置以及其他中风相关属性的信息。
从2017年10月至2019年1月在一家三级中风中心进行的1320例连续的头部和颈部计算机断层扫描(CT)、CT血管造影和CT灌注扫描的完整报告中,我们手动提取了近端大血管闭塞(主要结果)的存在数据,以及远端血管闭塞、缺血、出血、阿尔伯塔中风项目早期CT评分(ASPECTS)和侧支循环状态(次要结果)的数据。报告被随机分为训练集(n = 921)和验证集(n = 399),并使用基于规则的NLP提取属性。我们报告了NLP方法相对于手动提取数据的敏感性、特异性、阳性预测值(PPV)、阴性预测值(NPV)和总体准确性。
大血管闭塞的总体患病率为12.2%。在训练样本中,NLP方法识别该属性的总体准确率为97.3%(敏感性为95.5%,特异性为98.1%,PPV为84.1%,NPV为99.4%)。在验证集中,总体准确率为95.2%(敏感性为90.0%,特异性为97.4%,PPV为76.3%,NPV为98.5%)。识别远端或基底动脉闭塞以及出血的准确率也很高,但在识别脑缺血、ASPECTS和侧支循环状态方面存在局限性。
NLP可能会提高中风监测和研究的大规模成像数据收集效率。