Department of Biostatistics, The University of Texas, MD Anderson Cancer Center, Houston, United States.
BMC Med Res Methodol. 2021 Jun 1;21(1):111. doi: 10.1186/s12874-021-01308-8.
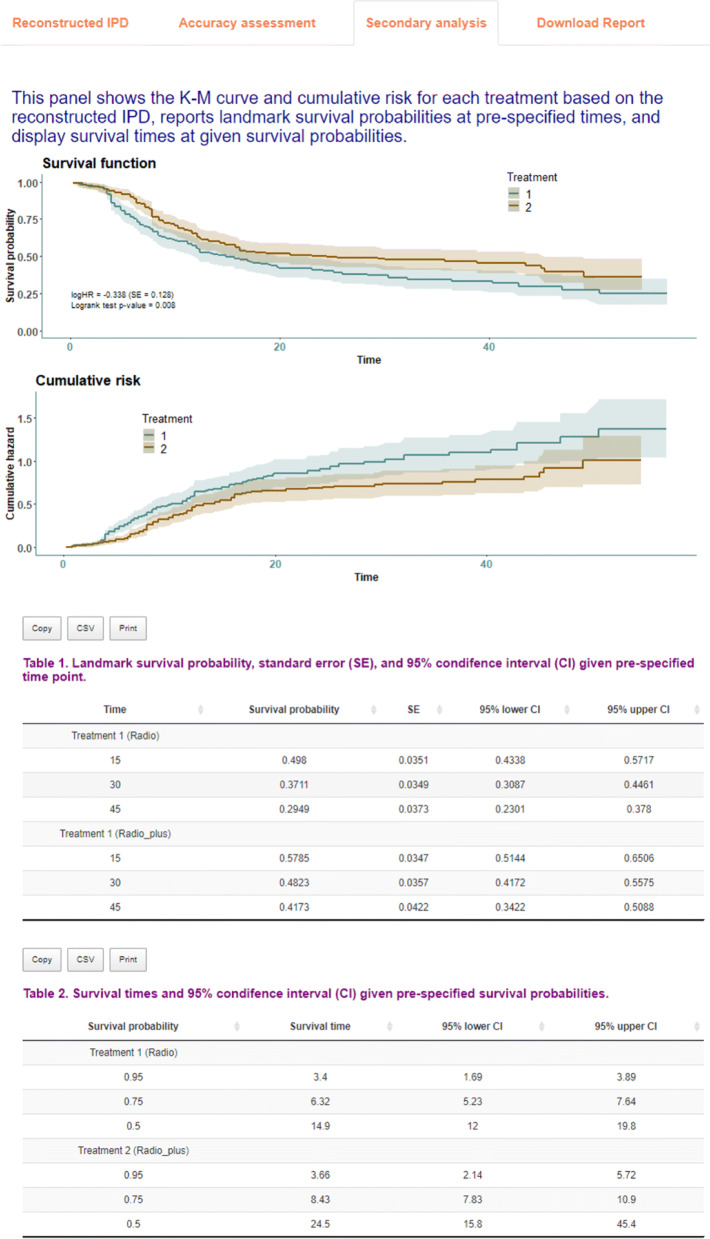
When applying secondary analysis on published survival data, it is critical to obtain each patient's raw data, because the individual patient data (IPD) approach has been considered as the gold standard of data analysis. However, researchers often lack access to IPD. We aim to propose a straightforward and robust approach to obtain IPD from published survival curves with a user-friendly software platform.
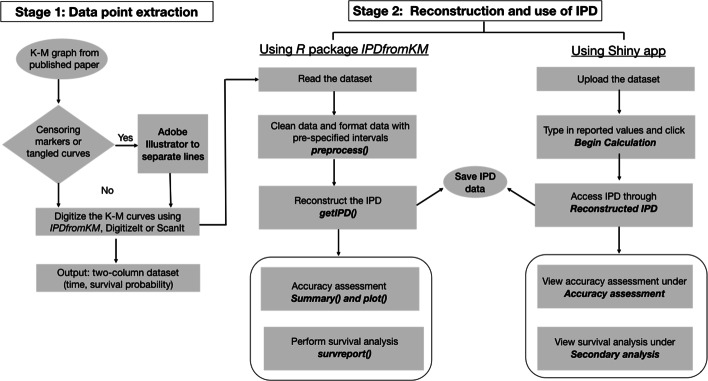
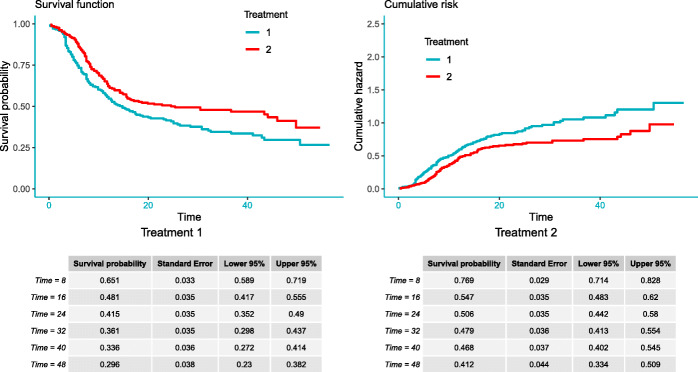
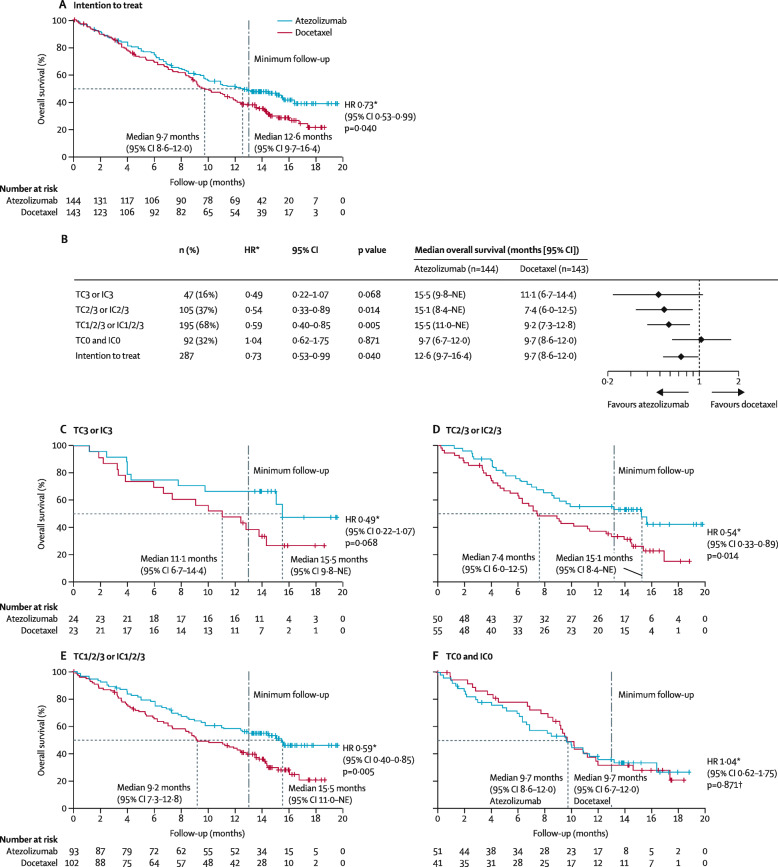
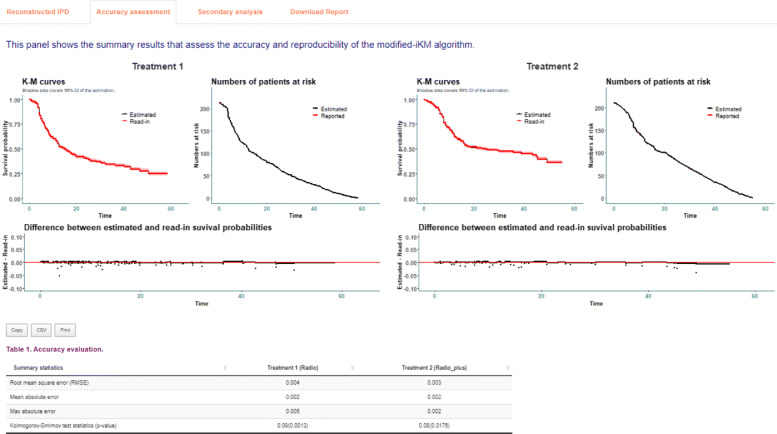
Improving upon existing methods, we propose an easy-to-use, two-stage approach to reconstruct IPD from published Kaplan-Meier (K-M) curves. Stage 1 extracts raw data coordinates and Stage 2 reconstructs IPD using the proposed method. To facilitate the use of the proposed method, we developed the R package IPDfromKM and an accompanying web-based Shiny application. Both the R package and Shiny application have an "all-in-one" feature such that users can use them to extract raw data coordinates from published K-M curves, reconstruct IPD from the extracted data coordinates, visualize the reconstructed IPD, assess the accuracy of the reconstruction, and perform secondary analysis on the basis of the reconstructed IPD. We illustrate the use of the R package and the Shiny application with K-M curves from published studies. Extensive simulations and real-world data applications demonstrate that the proposed method has high accuracy and great reliability in estimating the number of events, number of patients at risk, survival probabilities, median survival times, and hazard ratios.
IPDfromKM has great flexibility and accuracy to reconstruct IPD from published K-M curves with different shapes. We believe that the R package and the Shiny application will greatly facilitate the potential use of quality IPD and advance the use of secondary data to facilitate informed decision making in medical research.
在应用已发表的生存数据进行二次分析时,获取每个患者的原始数据至关重要,因为个体患者数据(IPD)方法被认为是数据分析的金标准。然而,研究人员通常无法获得 IPD。我们旨在提出一种简单而稳健的方法,使用用户友好的软件平台从已发表的生存曲线中获取 IPD。
在现有方法的基础上,我们提出了一种从已发表的 Kaplan-Meier(K-M)曲线中重建 IPD 的简单易用的两阶段方法。第 1 阶段提取原始数据坐标,第 2 阶段使用提出的方法重建 IPD。为了便于使用所提出的方法,我们开发了 R 包 IPDfromKM 和一个配套的基于 Shiny 的应用程序。R 包和 Shiny 应用程序都具有“一体化”功能,用户可以使用它们从已发表的 K-M 曲线中提取原始数据坐标,从提取的数据坐标中重建 IPD,可视化重建的 IPD,评估重建的准确性,并基于重建的 IPD 进行二次分析。我们用来自已发表研究的 K-M 曲线说明了 R 包和 Shiny 应用程序的使用。广泛的模拟和真实世界的数据应用表明,该方法在估计事件数量、风险患者数量、生存概率、中位生存时间和风险比方面具有很高的准确性和可靠性。
IPDfromKM 具有很大的灵活性和准确性,可以从具有不同形状的已发表 K-M 曲线中重建 IPD。我们相信,R 包和 Shiny 应用程序将极大地方便高质量 IPD 的潜在使用,并推进二次数据的使用,以促进医疗研究中的明智决策。