Faculty of Epidemiology and Population Health, Department of Non-Communicable Disease Epidemiology, Inequalities in Cancer Outcomes Network, London School of Hygiene & Tropical Medicine, London, United Kingdom.
Epidemiology of Childhood and Adolescent Cancers Team, CRESS, Université de Paris-INSERM, Villejuif, France.
PLoS One. 2021 Jun 2;16(6):e0251876. doi: 10.1371/journal.pone.0251876. eCollection 2021.
Pancreatic cancer (PC) represents a substantial public health burden. Pancreatic cancer patients have very low survival due to the difficulty of identifying cancers early when the tumour is localised to the site of origin and treatable. Recent progress has been made in identifying biomarkers for PC in the blood and urine, but these cannot be used for population-based screening as this would be prohibitively expensive and potentially harmful.
We conducted a case-control study using prospectively-collected electronic health records from primary care individually-linked to cancer registrations. Our cases were comprised of 1,139 patients, aged 15-99 years, diagnosed with pancreatic cancer between January 1, 2005 and June 30, 2009. Each case was age-, sex- and diagnosis time-matched to four non-pancreatic (cancer patient) controls. Disease and prescription codes for the 24 months prior to diagnosis were used to identify 57 individual symptoms. Using a machine learning approach, we trained a logistic regression model on 75% of the data to predict patients who later developed PC and tested the model's performance on the remaining 25%.
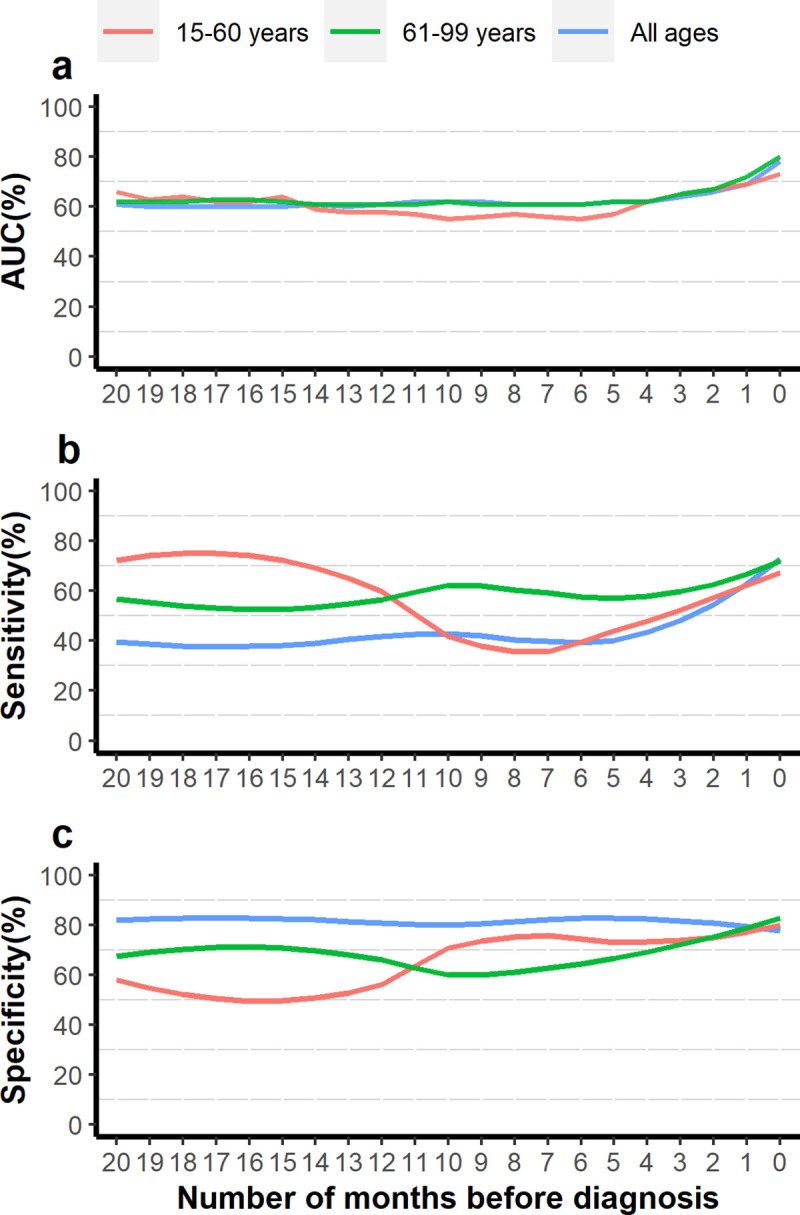
We were able to identify 41.3% of patients < = 60 years at 'high risk' of developing pancreatic cancer up to 20 months prior to diagnosis with 72.5% sensitivity, 59% specificity and, 66% AUC. 43.2% of patients >60 years were similarly identified at 17 months, with 65% sensitivity, 57% specificity and, 61% AUC. We estimate that combining our algorithm with currently available biomarker tests could result in 30 older and 400 younger patients per cancer being identified as 'potential patients', and the earlier diagnosis of around 60% of tumours.
After further work this approach could be applied in the primary care setting and has the potential to be used alongside a non-invasive biomarker test to increase earlier diagnosis. This would result in a greater number of patients surviving this devastating disease.
胰腺癌(PC)是一个重大的公共卫生负担。由于肿瘤局限于起源部位且可治疗时难以早期发现,胰腺癌患者的生存率非常低。最近在血液和尿液中发现了用于诊断 PC 的生物标志物,但由于这种方法费用过高且具有潜在危害,因此不能用于基于人群的筛查。
我们使用前瞻性收集的来自初级保健的电子健康记录进行了病例对照研究,这些记录通过个人链接到癌症登记处。我们的病例组由 1139 名年龄在 15-99 岁之间的患者组成,他们在 2005 年 1 月 1 日至 2009 年 6 月 30 日期间被诊断为胰腺癌。每个病例都与 4 名非胰腺癌(癌症患者)对照组按年龄、性别和诊断时间匹配。在诊断前的 24 个月中,使用疾病和处方代码来确定 57 种单独的症状。我们使用机器学习方法,在 75%的数据上训练了一个逻辑回归模型,以预测后来发展为 PC 的患者,并在剩余的 25%的数据上测试了该模型的性能。
我们能够识别出 41.3%的< = 60 岁的患者在诊断前 20 个月内处于发展为胰腺癌的“高风险”状态,其敏感性为 72.5%,特异性为 59%,AUC 为 66%。同样,43.2%的>60 岁患者在 17 个月时也能被识别出来,其敏感性为 65%,特异性为 57%,AUC 为 61%。我们估计,将我们的算法与目前可用的生物标志物测试相结合,可能会使每 100 例癌症中识别出 30 名老年患者和 400 名年轻患者为“潜在患者”,并使约 60%的肿瘤得到更早诊断。
进一步的研究后,这种方法可以在初级保健环境中应用,并有潜力与非侵入性生物标志物测试结合使用,以增加早期诊断。这将使更多的患者能够从这种毁灭性的疾病中存活下来。