School of Medicine, University of California, San Francisco.
Clinical Innovation Center, Department of Medicine, University of California, San Francisco.
JAMA Netw Open. 2018 Aug 3;1(4):e181018. doi: 10.1001/jamanetworkopen.2018.1018.
Current methods for identifying hospitalized patients at increased risk of delirium require nurse-administered questionnaires with moderate accuracy.
To develop and validate a machine learning model that predicts incident delirium risk based on electronic health data available on admission.
DESIGN, SETTING, AND PARTICIPANTS: Retrospective cohort study evaluating 5 machine learning algorithms to predict delirium using 796 clinical variables identified by an expert panel as relevant to delirium prediction and consistently available in electronic health records within 24 hours of admission. The training set comprised 14 227 adult patients with non-intensive care unit hospital stays and no delirium on admission who were discharged between January 1, 2016, and August 31, 2017, from UCSF Health, a large academic health institution. The test set comprised 3996 patients with hospital stays who were discharged between August 1, 2017, and November 30, 2017.
Patient demographic characteristics, diagnoses, nursing records, laboratory results, and medications available in electronic health records during hospitalization.
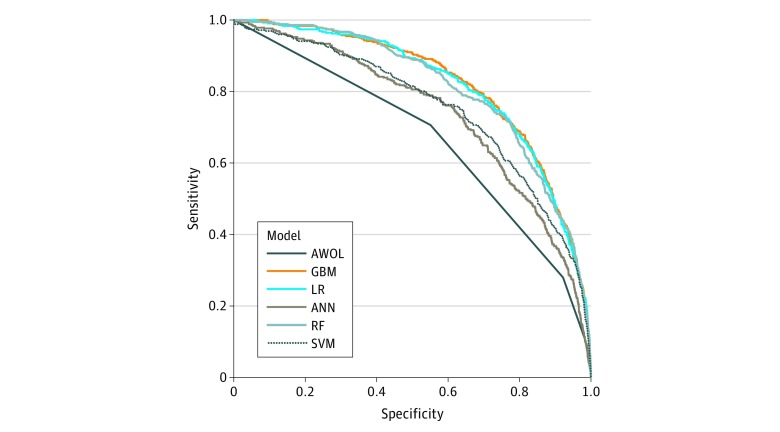
Delirium was defined as a positive Nursing Delirium Screening Scale or Confusion Assessment Method for the Intensive Care Unit score. Models were assessed using the area under the receiver operating characteristic curve (AUC) and compared against the 4-point scoring system AWOL (age >79 years, failure to spell world backward, disorientation to place, and higher nurse-rated illness severity), a validated delirium risk-assessment tool routinely administered in this cohort.
The training set included 14 227 patients (5113 [35.9%] aged >64 years; 7335 [51.6%] female; 687 [4.8%] with delirium), and the test set included 3996 patients (1491 [37.3%] aged >64 years; 1966 [49.2%] female; 191 [4.8%] with delirium). In total, the analysis included 18 223 hospital admissions (6604 [36.2%] aged >64 years; 9301 [51.0%] female; 878 [4.8%] with delirium). The AWOL system achieved a baseline AUC of 0.678. The gradient boosting machine model performed best, with an AUC of 0.855. Setting specificity at 90%, the model had a 59.7% (95% CI, 52.4%-66.7%) sensitivity, 23.1% (95% CI, 20.5%-25.9%) positive predictive value, 97.8% (95% CI, 97.4%-98.1%) negative predictive value, and a number needed to screen of 4.8. Penalized logistic regression and random forest models also performed well, with AUCs of 0.854 and 0.848, respectively.
Machine learning can be used to estimate hospital-acquired delirium risk using electronic health record data available within 24 hours of hospital admission. Such a model may allow more precise targeting of delirium prevention resources without increasing the burden on health care professionals.

目前用于识别住院患者发生谵妄风险的方法需要护士进行中等准确性的问卷调查。
开发和验证一种基于入院时可获得的电子健康数据预测谵妄风险的机器学习模型。
设计、设置和参与者:这是一项回顾性队列研究,使用专家小组确定的 796 个临床变量,通过 5 种机器学习算法来预测谵妄,这些变量被认为与谵妄预测相关且在入院后 24 小时内电子健康记录中始终可用。训练集包括 14227 名非重症监护病房住院且入院时无谵妄的成年患者,他们于 2016 年 1 月 1 日至 2017 年 8 月 31 日从 UCSF Health 出院,这是一家大型学术医疗机构。测试集包括 3996 名 2017 年 8 月 1 日至 11 月 30 日出院的住院患者。
患者的人口统计学特征、诊断、护理记录、实验室结果和住院期间电子健康记录中的药物。
谵妄的定义是护理谵妄筛查量表或重症监护病房意识评估方法阳性。使用接收者操作特征曲线(AUC)下的面积评估模型,并与 AWOL(年龄>79 岁、无法向后拼写单词、定向障碍、更高的护士评定疾病严重程度)评分系统进行比较,这是该队列中常规使用的一种经过验证的谵妄风险评估工具。
训练集包括 14227 名患者(5113 [35.9%]年龄>64 岁;7335 [51.6%]女性;687 [4.8%]发生谵妄),测试集包括 3996 名患者(1491 [37.3%]年龄>64 岁;1966 [49.2%]女性;191 [4.8%]发生谵妄)。总共分析了 18223 例住院治疗(6604 [36.2%]年龄>64 岁;9301 [51.0%]女性;878 [4.8%]发生谵妄)。AWOL 系统的基线 AUC 为 0.678。梯度提升机模型表现最佳,AUC 为 0.855。特异性设定为 90%时,该模型的灵敏度为 59.7%(95%CI,52.4%-66.7%)、23.1%(95%CI,20.5%-25.9%)、97.8%(95%CI,97.4%-98.1%)、阴性预测值和需要筛查的人数为 4.8。惩罚逻辑回归和随机森林模型也表现良好,AUC 分别为 0.854 和 0.848。
机器学习可用于使用入院后 24 小时内可获得的电子健康记录数据来估计医院获得性谵妄风险。这样的模型可能允许更精确地定位谵妄预防资源,而不会增加医疗保健专业人员的负担。