Division of Developmental and Personality Psychology, Department of Psychology, University of Basel, Missionsstrasse 62, 4055, Basel, Switzerland.
Center for Cognitive and Decision Sciences, Department of Psychology, University of Basel, Basel, Switzerland.
Behav Res Methods. 2022 Feb;54(1):54-74. doi: 10.3758/s13428-021-01581-x. Epub 2021 Jun 7.
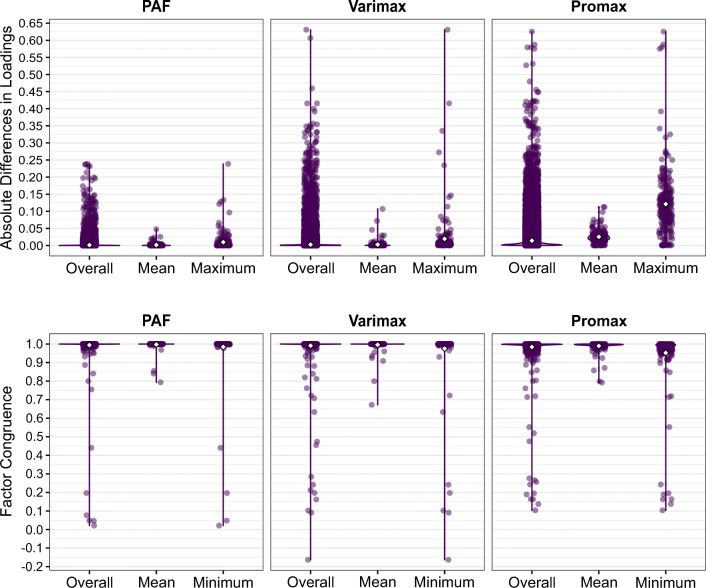
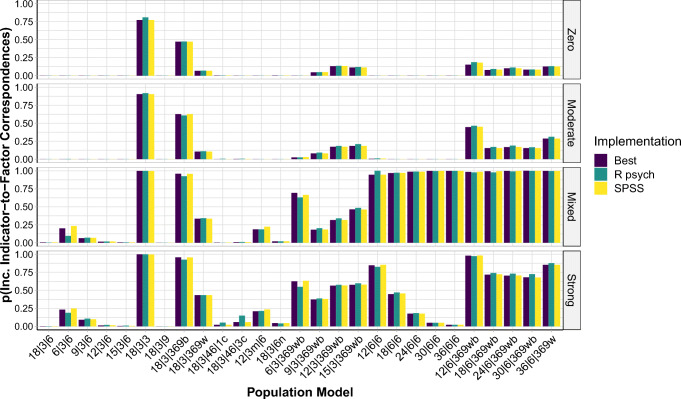
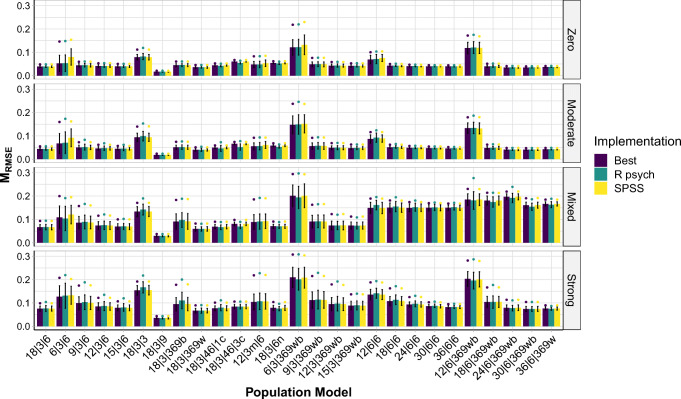
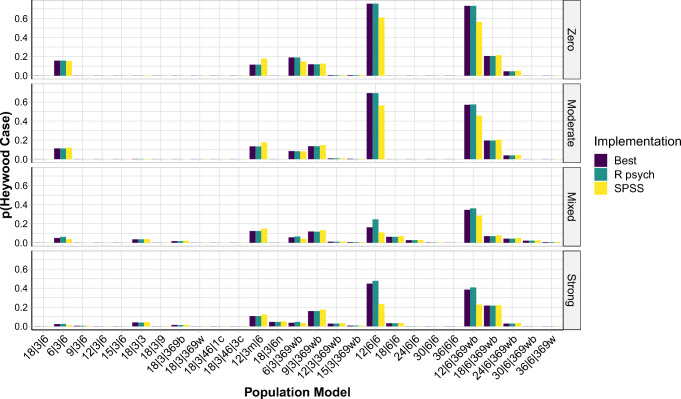
A statistical procedure is assumed to produce comparable results across programs. Using the case of an exploratory factor analysis procedure-principal axis factoring (PAF) and promax rotation-we show that this assumption is not always justified. Procedures with equal names are sometimes implemented differently across programs: a jingle fallacy. Focusing on two popular statistical analysis programs, we indeed discovered a jingle jungle for the above procedure: Both PAF and promax rotation are implemented differently in the psych R package and in SPSS. Based on analyses with 247 real and 216,000 simulated data sets implementing 108 different data structures, we show that these differences in implementations can result in fairly different factor solutions for a variety of different data structures. Differences in the solutions for real data sets ranged from negligible to very large, with 42% displaying at least one different indicator-to-factor correspondence. A simulation study revealed systematic differences in accuracies between different implementations, and large variation between data structures, with small numbers of indicators per factor, high factor intercorrelations, and weak factors resulting in the lowest accuracies. Moreover, although there was no single combination of settings that was superior for all data structures, we identified implementations of PAF and promax that maximize performance on average. We recommend researchers to use these implementations as best way through the jungle, discuss model averaging as a potential alternative, and highlight the importance of adhering to best practices of scale construction.
统计程序假定在不同程序中产生可比的结果。通过探索性因素分析程序——主成分因子分析(PAF)和 promax 旋转的案例,我们表明这种假设并不总是合理的。名称相同的程序在不同程序中的实现有时是不同的:一种叮当谬误。我们专注于两个流行的统计分析程序,确实为上述程序发现了一个叮当丛林:PAF 和 promax 旋转在 psych R 包和 SPSS 中的实现方式不同。基于对 247 个真实和 216000 个模拟数据集的分析,这些数据集实现了 108 种不同的数据结构,我们表明,这些实现中的差异可能导致各种不同的数据结构产生相当不同的因素解决方案。真实数据集解决方案之间的差异从微不足道到非常大,有 42%显示至少有一个不同的指标到因子对应关系。一项模拟研究揭示了不同实现之间的准确性存在系统差异,并且数据结构之间存在很大差异,每个因子的指标数量较少、因子之间的相关性较高以及因子较弱会导致准确性较低。此外,尽管没有一种组合设置可以适用于所有数据结构,但我们确定了 PAF 和 promax 的实现,这些实现平均而言可以最大限度地提高性能。我们建议研究人员使用这些实现作为穿越丛林的最佳方式,讨论模型平均作为潜在的替代方法,并强调遵守量表构建最佳实践的重要性。