Faculty of Computer Science and Information Technology, Department of Information Systems, University of Malaya, Kuala Lumpur, Malaysia.
Faculty of Computing, Department of Computer Science, Federal University of Lafia, Lafia, Nasarawa State, Nigeria.
PLoS One. 2021 Jun 10;16(6):e0252918. doi: 10.1371/journal.pone.0252918. eCollection 2021.
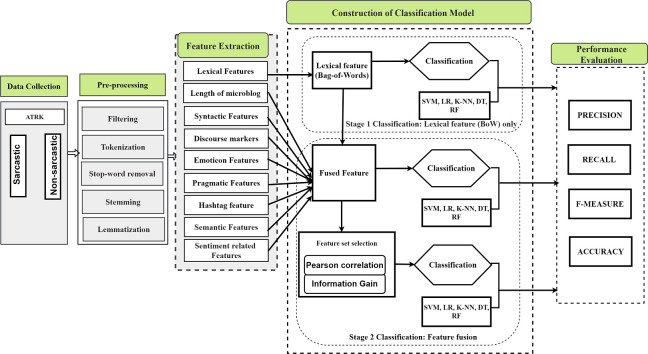
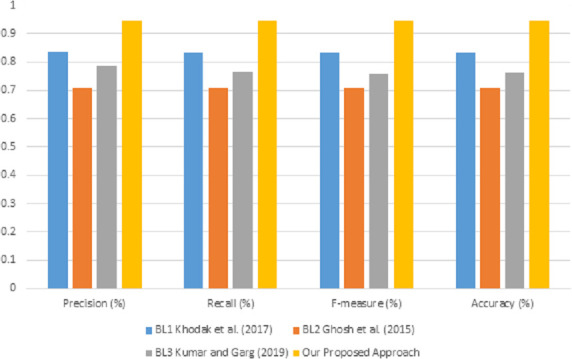
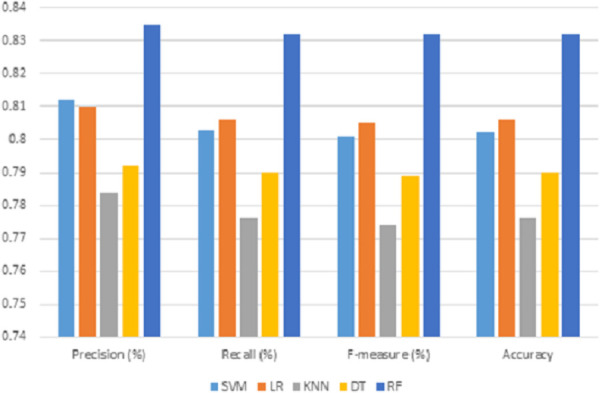
Sarcasm is the main reason behind the faulty classification of tweets. It brings a challenge in natural language processing (NLP) as it hampers the method of finding people's actual sentiment. Various feature engineering techniques are being investigated for the automatic detection of sarcasm. However, most related techniques have always concentrated only on the content-based features in sarcastic expression, leaving the contextual information in isolation. This leads to a loss of the semantics of words in the sarcastic expression. Another drawback is the sparsity of the training data. Due to the word limit of microblog, the feature vector's values for each sample constructed by BoW produces null features. To address the above-named problems, a Multi-feature Fusion Framework is proposed using two classification stages. The first stage classification is constructed with the lexical feature only, extracted using the BoW technique, and trained using five standard classifiers, including SVM, DT, KNN, LR, and RF, to predict the sarcastic tendency. In stage two, the constructed lexical sarcastic tendency feature is fused with eight other proposed features for modelling a context to obtain a final prediction. The effectiveness of the developed framework is tested with various experimental analysis to obtain classifiers' performance. The evaluation shows that our constructed classification models based on the developed novel feature fusion obtained results with a precision of 0.947 using a Random Forest classifier. Finally, the obtained results were compared with the results of three baseline approaches. The comparison outcome shows the significance of the proposed framework.
讽刺是导致推文错误分类的主要原因。它给自然语言处理(NLP)带来了挑战,因为它阻碍了人们发现真实情感的方法。各种特征工程技术正在被研究用于自动检测讽刺。然而,大多数相关技术总是只集中在讽刺表达的基于内容的特征上,将上下文信息孤立起来。这导致讽刺表达中单词的语义丢失。另一个缺点是训练数据的稀疏性。由于微博的字数限制,BoW 构建的每个样本的特征向量值都会产生空特征。为了解决上述问题,提出了一种多特征融合框架,使用两个分类阶段。第一阶段的分类仅使用词汇特征构建,使用 BoW 技术提取,并使用五种标准分类器(包括 SVM、DT、KNN、LR 和 RF)进行训练,以预测讽刺倾向。在第二阶段,构建的词汇讽刺倾向特征与其他八个建议的特征融合,以建模上下文,从而获得最终预测。通过各种实验分析来测试所开发框架的有效性,以获得分类器的性能。评估表明,我们基于所开发的新颖特征融合构建的分类模型使用随机森林分类器获得了 0.947 的精度。最后,将获得的结果与三种基线方法的结果进行了比较。比较结果表明了所提出框架的重要性。