Buchan Kevin, Filannino Michele, Uzuner Özlem
Department of Information Science, State University of New York at Albany, NY, USA.
Department of Computer Science, State University of New York at Albany, NY, USA.
J Biomed Inform. 2017 Aug;72:23-32. doi: 10.1016/j.jbi.2017.06.019. Epub 2017 Jun 27.
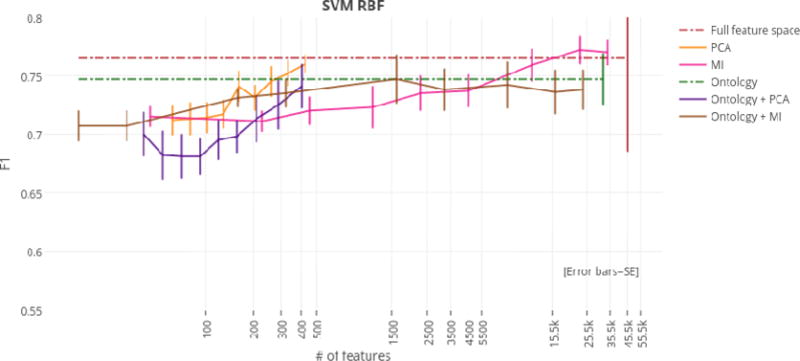
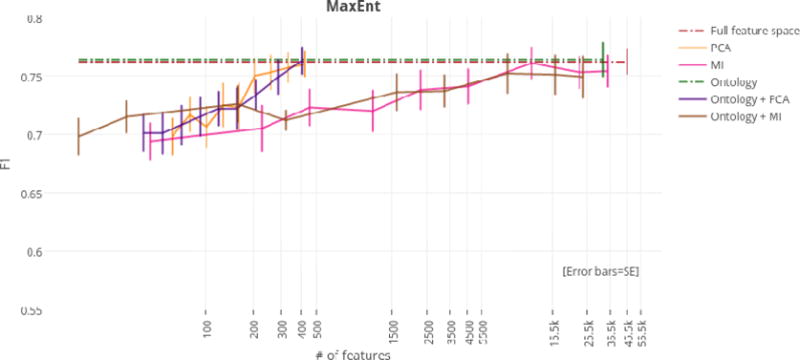
Coronary Artery Disease (CAD) is not only the most common form of heart disease, but also the leading cause of death in both men and women (Coronary Artery Disease: MedlinePlus, 2015). We present a system that is able to automatically predict whether patients develop coronary artery disease based on their narrative medical histories, i.e., clinical free text. Although the free text in medical records has been used in several studies for identifying risk factors of coronary artery disease, to the best of our knowledge our work marks the first attempt at automatically predicting development of CAD. We tackle this task on a small corpus of diabetic patients. The size of this corpus makes it important to limit the number of features in order to avoid overfitting. We propose an ontology-guided approach to feature extraction, and compare it with two classic feature selection techniques. Our system achieves state-of-the-art performance of 77.4% F1 score.
冠状动脉疾病(CAD)不仅是最常见的心脏病形式,也是男性和女性死亡的主要原因(冠状动脉疾病:MedlinePlus,2015)。我们提出了一种系统,该系统能够根据患者的叙述性病史(即临床自由文本)自动预测患者是否会患上冠状动脉疾病。尽管病历中的自由文本已在多项研究中用于识别冠状动脉疾病的危险因素,但据我们所知,我们的工作是首次尝试自动预测CAD的发展情况。我们在一小批糖尿病患者语料库上处理这项任务。这个语料库的规模使得限制特征数量以避免过拟合变得很重要。我们提出了一种本体引导的特征提取方法,并将其与两种经典的特征选择技术进行比较。我们的系统实现了77.4%的F1分数这一领先水平的性能。