School of Computer Science and Electronic Engineering, University of Essex, Wivenhoe Park, Colchester, UK.
Medical School, University of Exeter, Barrack Road, Exeter, UK.
BMC Genomics. 2021 Jun 28;22(1):484. doi: 10.1186/s12864-021-07675-2.
Sex is an important covariate of epigenome-wide association studies due to its strong influence on DNA methylation patterns across numerous genomic positions. Nevertheless, many samples on the Gene Expression Omnibus (GEO) frequently lack a sex annotation or are incorrectly labelled. Considering the influence that sex imposes on DNA methylation patterns, it is necessary to ensure that methods for filtering poor samples and checking of sex assignment are accurate and widely applicable.
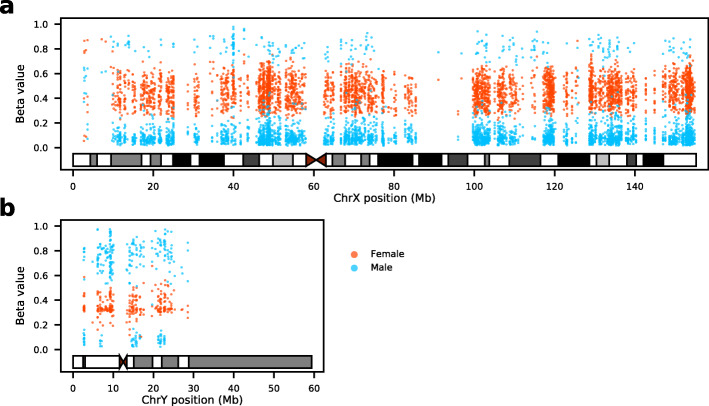
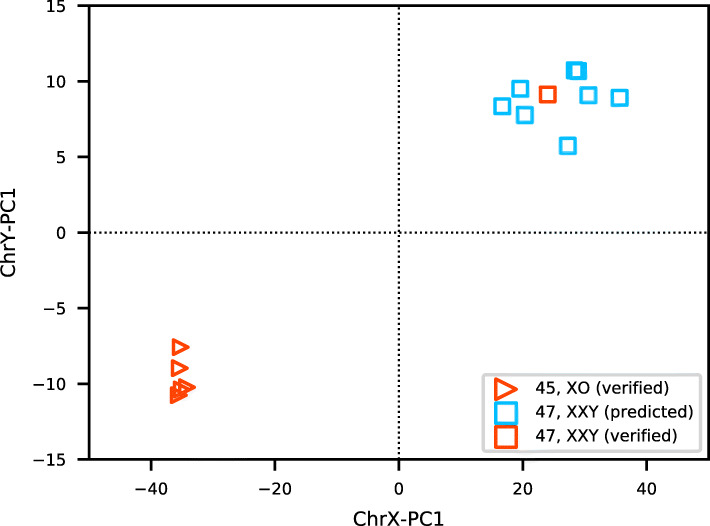
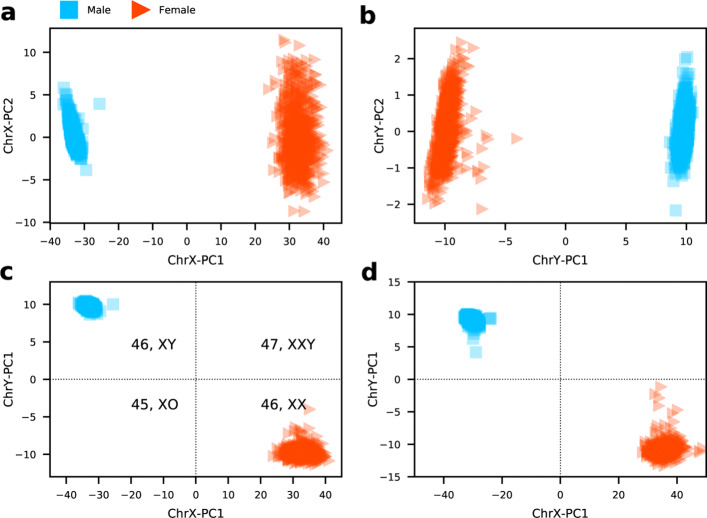
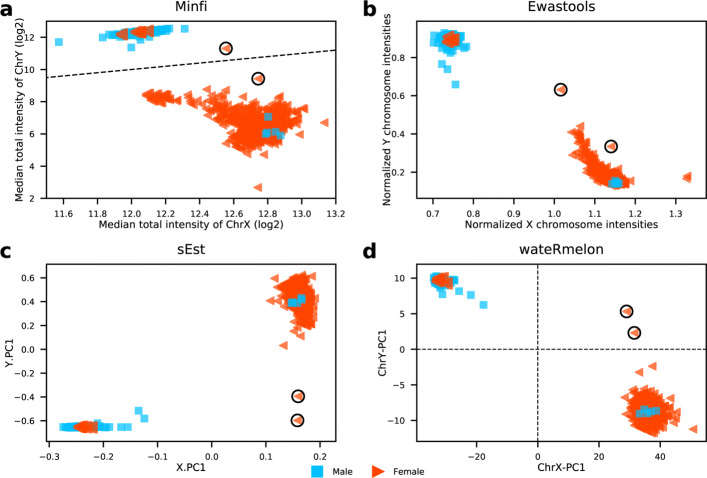
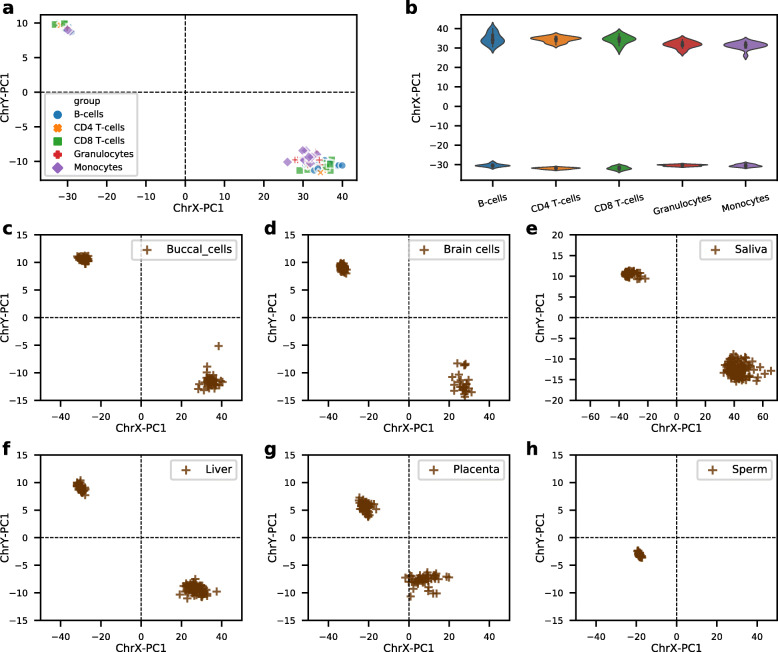
Here we presented a novel method to predict sex using only DNA methylation beta values, which can be readily applied to almost all DNA methylation datasets of different formats (raw IDATs or text files with only signal intensities) uploaded to GEO. We identified 4345 significantly (p<0.01) sex-associated CpG sites present on both 450K and EPIC arrays, and constructed a sex classifier based on the two first principal components of the DNA methylation data of sex-associated probes mapped on sex chromosomes. The proposed method is constructed using whole blood samples and exhibits good performance across a wide range of tissues. We further demonstrated that our method can be used to identify samples with sex chromosome aneuploidy, this function is validated by five Turner syndrome cases and one Klinefelter syndrome case.
This proposed sex classifier not only can be used for sex predictions but also applied to identify samples with sex chromosome aneuploidy, and it is freely and easily accessible by calling the 'estimateSex' function from the newest wateRmelon Bioconductor package ( https://github.com/schalkwyk/wateRmelon ).
由于性别的强烈影响,其对众多基因组位置的 DNA 甲基化模式具有重要影响,因此性别是全基因组关联研究中的一个重要协变量。然而,基因表达综合数据库(GEO)上的许多样本通常缺乏性别注释或标签不正确。考虑到性别对 DNA 甲基化模式的影响,有必要确保筛选不良样本和检查性别分配的方法是准确且广泛适用的。
我们在这里提出了一种仅使用 DNA 甲基化β值预测性别的新方法,该方法可以很容易地应用于几乎所有不同格式的 DNA 甲基化数据集(原始 IDAT 或仅包含信号强度的文本文件)上传到 GEO。我们确定了 4345 个在 450K 和 EPIC 阵列上均显著(p<0.01)与性别相关的 CpG 位点,并且基于映射到性染色体上与性别相关探针的 DNA 甲基化数据的两个第一主成分构建了一个性别分类器。所提出的方法是使用全血样本构建的,并且在广泛的组织中表现出良好的性能。我们进一步证明,我们的方法可以用于识别性染色体非整倍体的样本,这一功能通过五个 Turner 综合征病例和一个 Klinefelter 综合征病例得到验证。
这个提出的性别分类器不仅可以用于性别预测,还可以用于识别性染色体非整倍体的样本,并且可以通过调用最新的 wateRmelon Bioconductor 包(https://github.com/schalkwyk/wateRmelon)中的“estimateSex”函数轻松自由地使用。