Department of Methodology and Statistics, Tilburg University, Prof. Cobbenhagenlaan 225, Simon Building, Room S 820, 5037 DB , Tilburg, The Netherlands.
Department of Methodology and Statistics, Tilburg University, Tilburg, The Netherlands.
Psychometrika. 2021 Dec;86(4):893-919. doi: 10.1007/s11336-021-09773-2. Epub 2021 Jun 29.
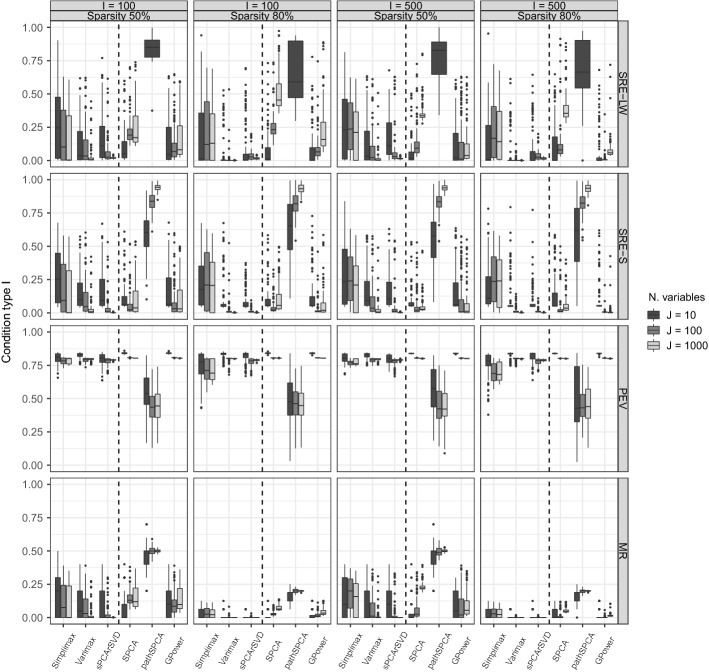
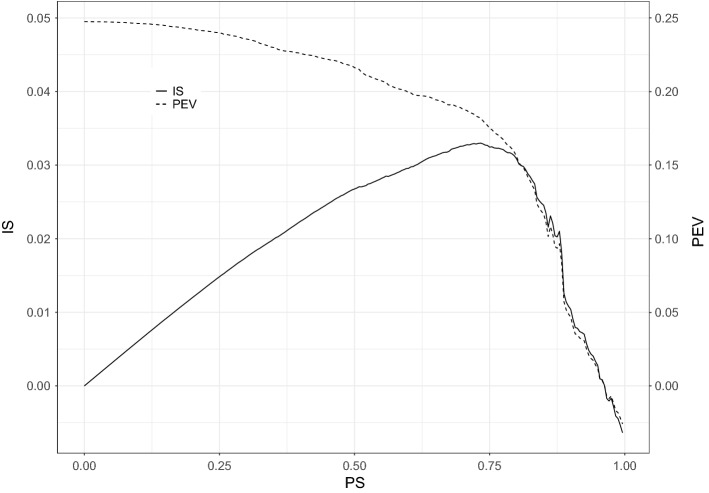
PCA is a popular tool for exploring and summarizing multivariate data, especially those consisting of many variables. PCA, however, is often not simple to interpret, as the components are a linear combination of the variables. To address this issue, numerous methods have been proposed to sparsify the nonzero coefficients in the components, including rotation-thresholding methods and, more recently, PCA methods subject to sparsity inducing penalties or constraints. Here, we offer guidelines on how to choose among the different sparse PCA methods. Current literature misses clear guidance on the properties and performance of the different sparse PCA methods, often relying on the misconception that the equivalence of the formulations for ordinary PCA also holds for sparse PCA. To guide potential users of sparse PCA methods, we first discuss several popular sparse PCA methods in terms of where the sparseness is imposed on the loadings or on the weights, assumed model, and optimization criterion used to impose sparseness. Second, using an extensive simulation study, we assess each of these methods by means of performance measures such as squared relative error, misidentification rate, and percentage of explained variance for several data generating models and conditions for the population model. Finally, two examples using empirical data are considered.
主成分分析(PCA)是探索和总结多元数据的常用工具,特别是那些由许多变量组成的数据。然而,PCA 通常不容易解释,因为组件是变量的线性组合。为了解决这个问题,已经提出了许多方法来稀疏化组件中的非零系数,包括旋转阈值方法和最近的稀疏 PCA 方法,这些方法受到稀疏诱导惩罚或约束的影响。在这里,我们提供了如何在不同的稀疏 PCA 方法之间进行选择的指导原则。目前的文献缺乏对不同稀疏 PCA 方法的性质和性能的明确指导,通常依赖于这样一种误解,即普通 PCA 的公式等价也适用于稀疏 PCA。为了指导潜在的稀疏 PCA 方法用户,我们首先根据稀疏性是施加在加载项还是权重上、所假设的模型以及用于施加稀疏性的优化标准,讨论几种流行的稀疏 PCA 方法。其次,我们使用广泛的模拟研究,通过平方相对误差、误识别率和几个数据生成模型的解释方差百分比等性能指标来评估这些方法的性能,以及总体模型的条件。最后,考虑了两个使用经验数据的示例。