Am J Epidemiol. 2021 Dec 1;190(12):2680-2689. doi: 10.1093/aje/kwab190.
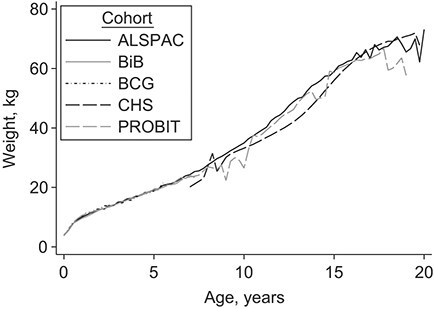
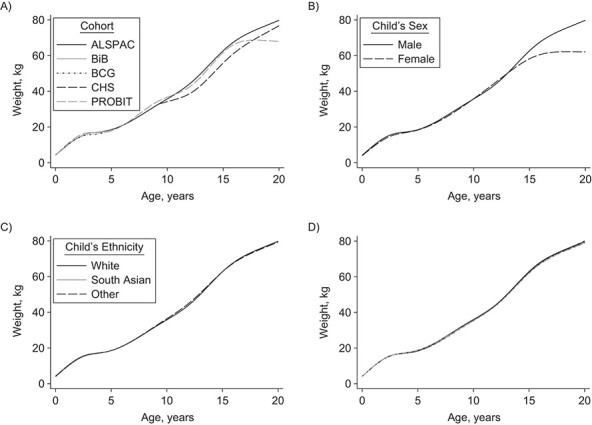
Longitudinal data are necessary to reveal changes within an individual as he or she ages. However, rarely will a single cohort study capture data throughout a person's entire life span. Here we describe in detail the steps needed to develop life-course trajectories from cohort studies that cover different and overlapping periods of life. Such independent studies are probably from heterogenous populations, which raises several challenges, including: 1) data harmonization (deriving new harmonized variables from differently measured variables by identifying common elements across all studies); 2) systematically missing data (variables not measured are missing for all participants in a cohort); and 3) model selection with differing age ranges and measurement schedules. We illustrate how to overcome these challenges using an example which examines the associations of parental education, sex, and race/ethnicity with children's weight trajectories. Data were obtained from 5 prospective cohort studies (carried out in Belarus and 4 regions of the United Kingdom) spanning data collected from birth to early adulthood during differing calendar periods (1936-1964, 1972-1979, 1990-2012, 1996-2016, and 2007-2015). Key strengths of our approach include modeling of trajectories over wide age ranges, sharing of information across studies, and direct comparison of the same parts of the life course in different geographical regions and time periods. We also introduce a novel approach of imputing individual-level covariates of a multilevel model with a nonlinear growth trajectory and interactions.
纵向数据对于揭示个体随年龄变化的情况是必要的。然而,很少有单一的队列研究能够在一个人的整个生命周期中捕获数据。在这里,我们详细描述了从涵盖不同和重叠生命阶段的队列研究中开发生命轨迹的步骤。这些独立的研究可能来自异质人群,这带来了几个挑战,包括:1)数据协调(通过在所有研究中识别共同元素,从不同测量的变量中推导出新的协调变量);2)系统缺失数据(一个队列中的所有参与者的变量未被测量);3)具有不同年龄范围和测量时间表的模型选择。我们将通过一个例子来说明如何克服这些挑战,该例子研究了父母教育、性别和种族/民族与儿童体重轨迹的关联。数据来自 5 项前瞻性队列研究(在白俄罗斯和英国的 4 个地区进行),涵盖了从出生到成年早期在不同日历期间收集的数据(1936-1964 年、1972-1979 年、1990-2012 年、1996-2016 年和 2007-2015 年)。我们方法的主要优势包括对广泛年龄范围的轨迹进行建模、在研究之间共享信息,以及在不同地理区域和时间点直接比较生命历程的相同部分。我们还介绍了一种新方法,即用非线性增长轨迹和交互作用来模拟具有多水平模型的个体水平协变量的个体水平协变量。