Nethery Rachel C, Yang Yue, Brown Anna J, Dominici Francesca
Harvard T.H. Chan School of Public Health, Boston MA, USA.
University of Chicago, Chicago IL, USA.
J R Stat Soc Ser A Stat Soc. 2020 Jun;183(3):1253-1272. doi: 10.1111/rssa.12567. Epub 2020 Apr 25.
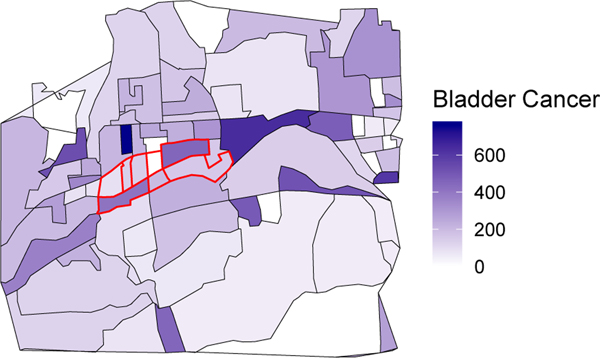
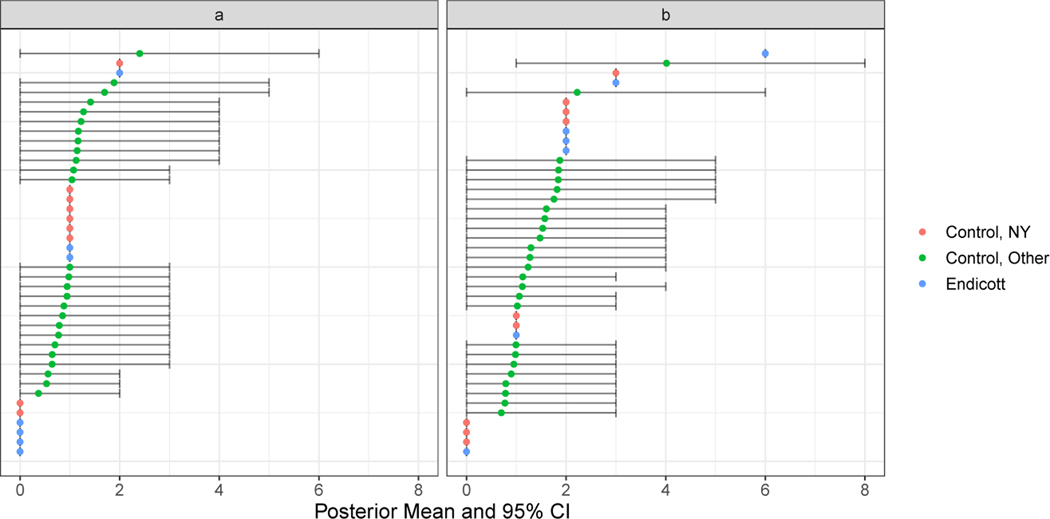
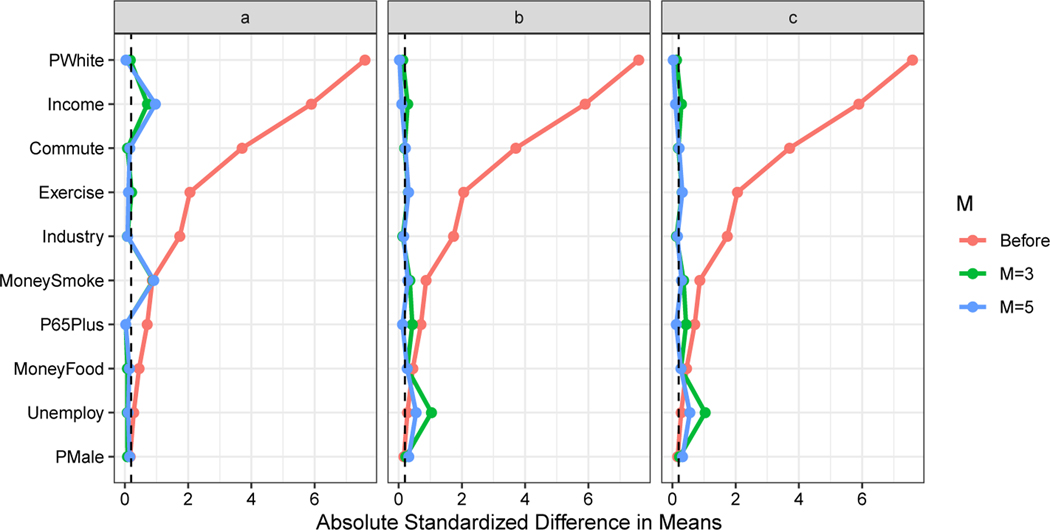
Often, a community becomes alarmed when high rates of cancer are noticed, and residents suspect that the cancer cases could be caused by a known source of hazard. In response, the US Centers for Disease Control and Prevention recommend that departments of health perform a standardized incidence ratio (SIR) analysis to determine whether the observed cancer incidence is higher than expected. This approach has several limitations that are well documented in the existing literature. In this paper we propose a novel causal inference framework for cancer cluster investigations, rooted in the potential outcomes framework. Assuming that a source of hazard representing a potential cause of increased cancer rates in the community is identified a priori, we focus our approach on a causal inference estimand which we call the causal SIR (cSIR). The cSIR is a ratio defined as the expected cancer incidence in the exposed population divided by the expected cancer incidence for the same population under the (counterfactual) scenario of no exposure. To estimate the cSIR we need to overcome two main challenges: 1) identify unexposed populations that are as similar as possible to the exposed one to inform estimation of the expected cancer incidence under the counterfactual scenario of no exposure, and 2) publicly available data on cancer incidence for these unexposed populations are often available at a much higher level of spatial aggregation (e.g. county) than what is desired (e.g. census block group). We overcome the first challenge by relying on matching. We overcome the second challenge by building a Bayesian hierarchical model that borrows information from other sources to impute cancer incidence at the desired level of spatial aggregation. In simulations, our statistical approach was shown to provide dramatically improved results, i.e., less bias and better coverage, than the current approach to SIR analyses. We apply our proposed approach to investigate whether trichloroethylene vapor exposure has caused increased cancer incidence in Endicott, New York.
通常,当注意到癌症高发率时,社区会感到恐慌,居民怀疑癌症病例可能是由已知的危害源引起的。作为回应,美国疾病控制与预防中心建议卫生部门进行标准化发病率比(SIR)分析,以确定观察到的癌症发病率是否高于预期。这种方法存在一些局限性,现有文献对此有充分记载。在本文中,我们提出了一种用于癌症聚集性调查的新型因果推断框架,该框架基于潜在结果框架。假设事先确定了一个代表社区中癌症发病率上升潜在原因的危害源,我们将方法重点放在一个我们称为因果SIR(cSIR)的因果推断估计量上。cSIR是一个比率,定义为暴露人群中的预期癌症发病率除以在无暴露(反事实)情景下同一人群的预期癌症发病率。为了估计cSIR,我们需要克服两个主要挑战:1)识别与暴露人群尽可能相似的未暴露人群,以了解在无暴露的反事实情景下预期癌症发病率的估计情况;2)这些未暴露人群的癌症发病率公开数据通常在比所需空间聚合水平(例如人口普查街区组)高得多的空间聚合水平(例如县)上可用。我们通过匹配来克服第一个挑战。我们通过构建一个贝叶斯层次模型来克服第二个挑战,该模型从其他来源借用信息,以在所需的空间聚合水平上估算癌症发病率。在模拟中,我们的统计方法显示出比当前SIR分析方法有显著改进的结果,即偏差更小且覆盖范围更好。我们应用我们提出的方法来调查三氯乙烯蒸气暴露是否导致了纽约州恩迪科特的癌症发病率上升。