School of Biomedical Engineering, Capital Medical University, No.10, Xitoutiao, You An Men, Fengtai District, Beijing, 100069, People's Republic of China.
Beijing Key Laboratory of Fundamental Research on Biomechanics in Clinical Application, Capital Medical University, Beijing, 100069, People's Republic of China.
BMC Med Inform Decis Mak. 2021 Jul 30;21(Suppl 2):58. doi: 10.1186/s12911-021-01432-x.
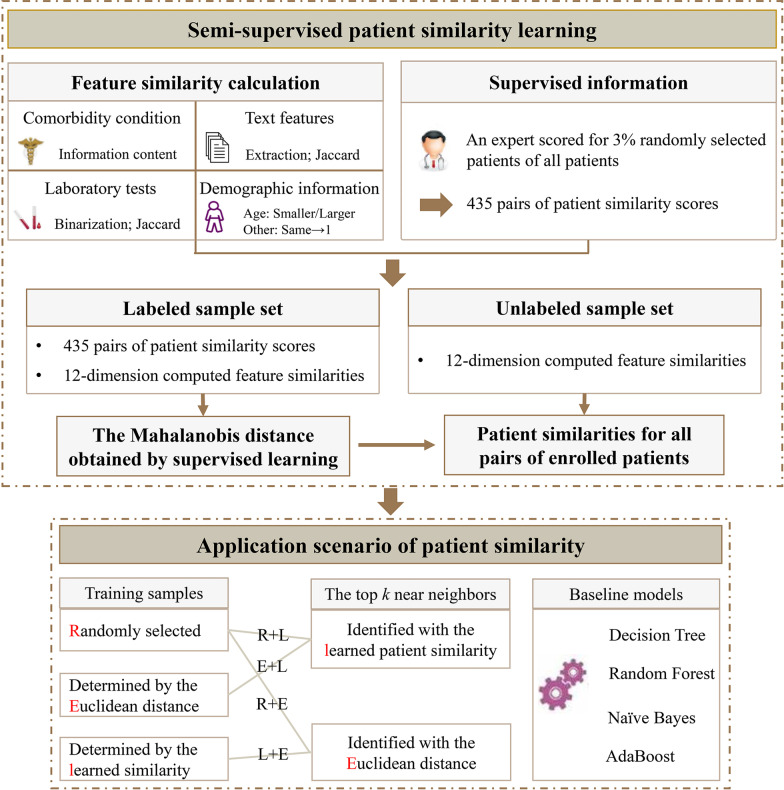
A new learning-based patient similarity measurement was proposed to measure patients' similarity for heterogeneous electronic medical records (EMRs) data.
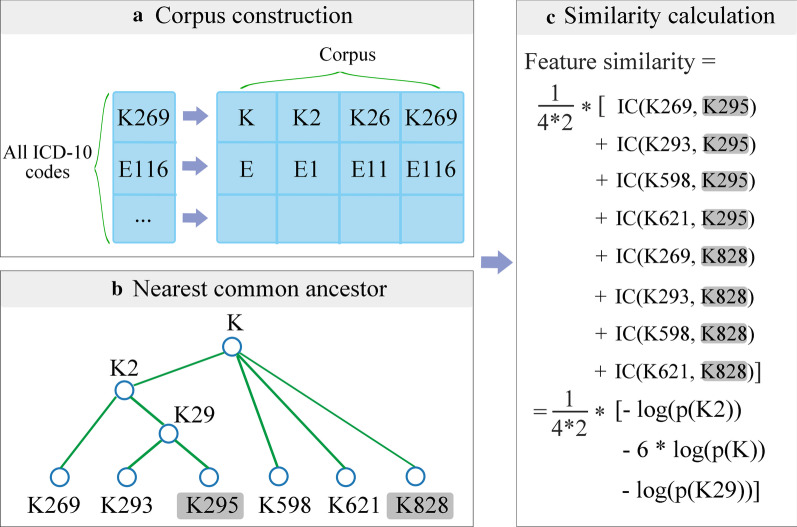
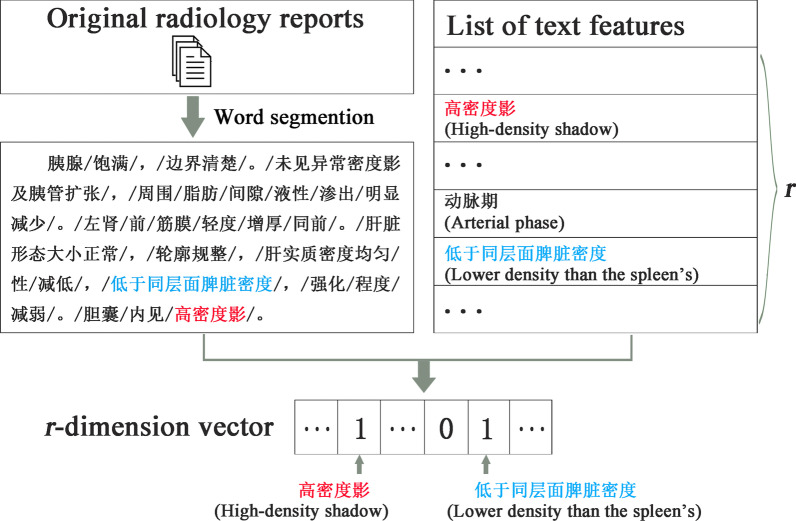
We first calculated feature-level similarities according to the features' attributes. A domain expert provided patient similarity scores of 30 randomly selected patients. These similarity scores and feature-level similarities for 30 patients comprised the labeled sample set, which was used for the semi-supervised learning algorithm to learn the patient-level similarities for all patients. Then we used the k-nearest neighbor (kNN) classifier to predict four liver conditions. The predictive performances were compared in four different situations. We also compared the performances between personalized kNN models and other machine learning models. We assessed the predictive performances by the area under the receiver operating characteristic curve (AUC), F1-score, and cross-entropy (CE) loss.
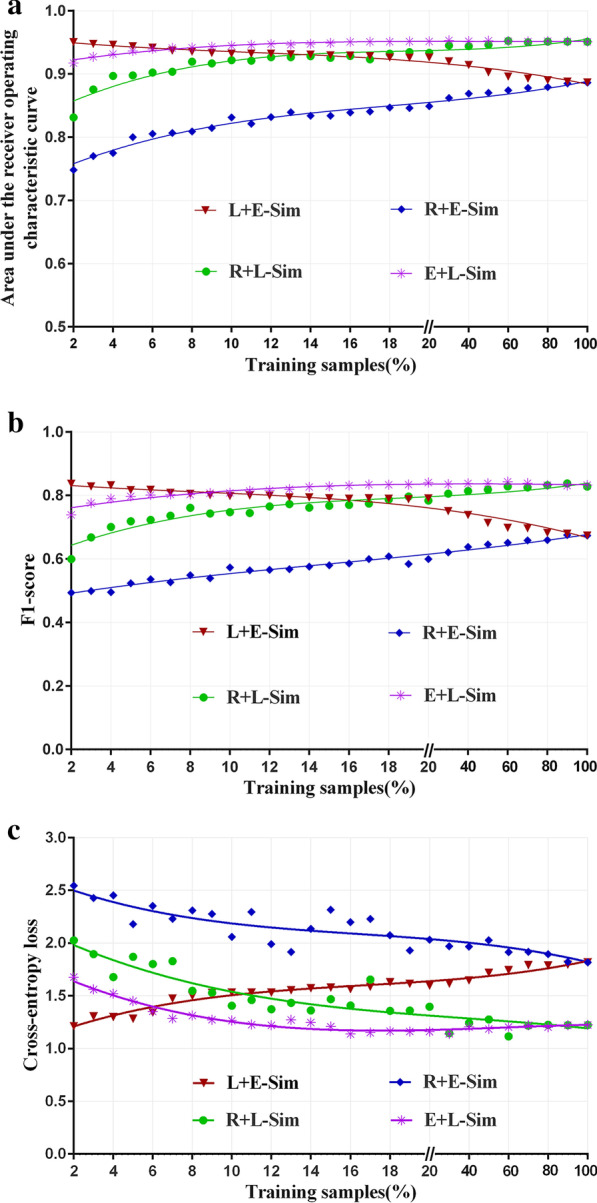
As the size of the random training samples increased, the kNN models using the learned patient similarity to select near neighbors consistently outperformed those using the Euclidean distance to select near neighbors (all P values < 0.001). The kNN models using the learned patient similarity to identify the top k nearest neighbors from the random training samples also had a higher best-performance (AUC: 0.95 vs. 0.89, F1-score: 0.84 vs. 0.67, and CE loss: 1.22 vs. 1.82) than those using the Euclidean distance. As the size of the similar training samples increased, which composed the most similar samples determined by the learned patient similarity, the performance of kNN models using the simple Euclidean distance to select the near neighbors degraded gradually. When exchanging the role of the Euclidean distance, and the learned patient similarity in selecting the near neighbors and similar training samples, the performance of the kNN models gradually increased. These two kinds of kNN models had the same best-performance of AUC 0.95, F1-score 0.84, and CE loss 1.22. Among the four reference models, the highest AUC and F1-score were 0.94 and 0.80, separately, which were both lower than those for the simple and similarity-based kNN models.
This learning-based method opened an opportunity for similarity measurement based on heterogeneous EMR data and supported the secondary use of EMR data.
为了测量异构电子病历(EMR)数据中患者的相似性,提出了一种新的基于学习的患者相似性测量方法。
我们首先根据特征的属性计算特征级相似性。一位领域专家提供了 30 名随机选择患者的患者相似性评分。这些相似性评分和 30 名患者的特征级相似性构成了有标签的样本集,用于半监督学习算法学习所有患者的患者级相似性。然后,我们使用 k-最近邻(kNN)分类器预测四种肝脏状况。在四种不同情况下比较了预测性能。我们还比较了个性化 kNN 模型和其他机器学习模型之间的性能。我们通过接收者操作特征曲线下的面积(AUC)、F1 分数和交叉熵(CE)损失来评估预测性能。
随着随机训练样本数量的增加,使用学习到的患者相似性选择近邻的 kNN 模型始终优于使用欧几里得距离选择近邻的 kNN 模型(所有 P 值均<0.001)。使用学习到的患者相似性从随机训练样本中识别前 k 个最近邻的 kNN 模型也具有更高的最佳性能(AUC:0.95 与 0.89,F1 分数:0.84 与 0.67,CE 损失:1.22 与 1.82)比使用欧几里得距离的模型。随着相似训练样本数量的增加,由学习到的患者相似性确定的最相似样本的数量增加,使用简单欧几里得距离选择近邻的 kNN 模型的性能逐渐下降。当在选择近邻和相似训练样本时交换欧几里得距离和学习到的患者相似性的角色时,kNN 模型的性能逐渐提高。这两种 kNN 模型的 AUC 最佳性能均为 0.95,F1 分数均为 0.84,CE 损失均为 1.22。在四个参考模型中,最高的 AUC 和 F1 分数分别为 0.94 和 0.80,均低于简单和基于相似性的 kNN 模型。
这种基于学习的方法为基于异构 EMR 数据的相似性测量开辟了机会,并支持 EMR 数据的二次使用。