Cardiovascular Division, Department of Medicine, Brigham and Women's Hospital, Harvard Medical School, Boston, Massachusetts, USA.
Department of Medicine, Brigham and Women's Hospital, Harvard Medical School, Boston, Massachusetts, USA.
Clin Cardiol. 2021 Sep;44(9):1296-1304. doi: 10.1002/clc.23687. Epub 2021 Aug 4.
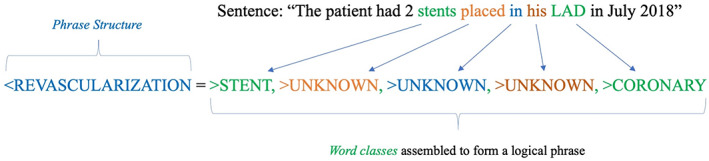
Accurate ascertainment of comorbidities is paramount in clinical research. While manual adjudication is labor-intensive and expensive, the adoption of electronic health records enables computational analysis of free-text documentation using natural language processing (NLP) tools.
We sought to develop highly accurate NLP modules to assess for the presence of five key cardiovascular comorbidities in a large electronic health record system.
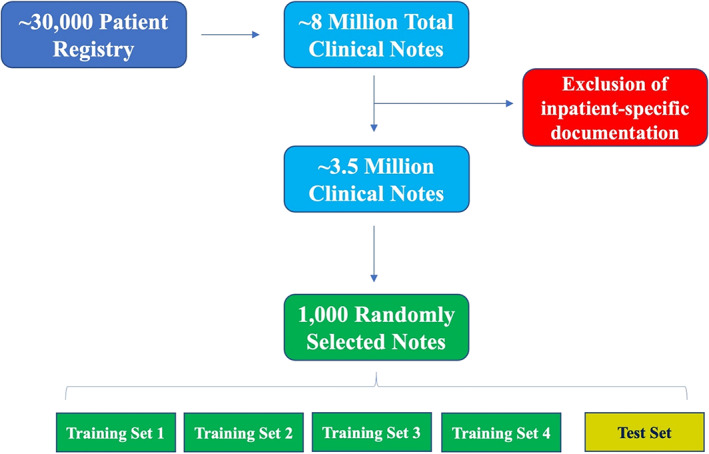
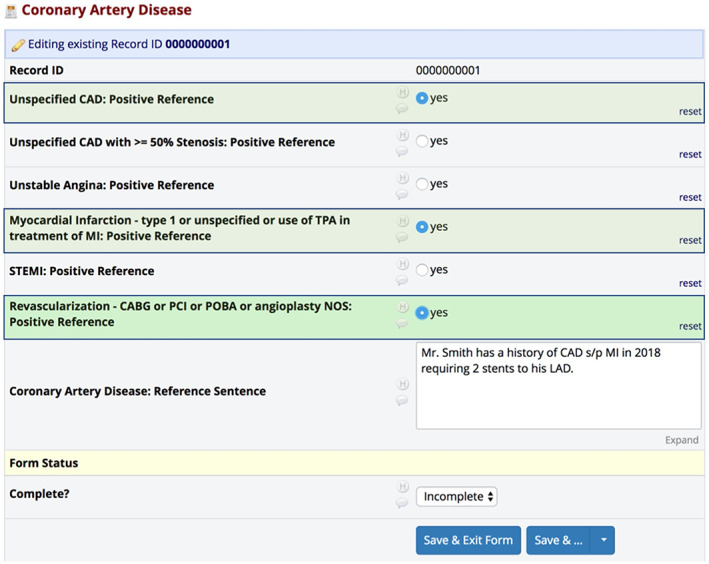
One-thousand clinical notes were randomly selected from a cardiovascular registry at Mass General Brigham. Trained physicians manually adjudicated these notes for the following five diagnostic comorbidities: hypertension, dyslipidemia, diabetes, coronary artery disease, and stroke/transient ischemic attack. Using the open-source Canary NLP system, five separate NLP modules were designed based on 800 "training-set" notes and validated on 200 "test-set" notes.
Across the five NLP modules, the sentence-level and note-level sensitivity, specificity, and positive predictive value was always greater than 85% and was most often greater than 90%. Accuracy tended to be highest for conditions with greater diagnostic clarity (e.g. diabetes and hypertension) and slightly lower for conditions whose greater diagnostic challenges (e.g. myocardial infarction and embolic stroke) may lead to less definitive documentation.
We designed five open-source and highly accurate NLP modules that can be used to assess for the presence of important cardiovascular comorbidities in free-text health records. These modules have been placed in the public domain and can be used for clinical research, trial recruitment and population management at any institution as well as serve as the basis for further development of cardiovascular NLP tools.
准确确定合并症在临床研究中至关重要。虽然手动判断既费力又昂贵,但电子健康记录的采用使使用自然语言处理 (NLP) 工具对自由文本文档进行计算分析成为可能。
我们试图开发高度准确的 NLP 模块,以在大型电子健康记录系统中评估五种主要心血管合并症的存在。
从 Mass General Brigham 的心血管登记处随机选择了 1000 份临床记录。经过培训的医生手动判断这些记录是否存在以下五种诊断合并症:高血压、血脂异常、糖尿病、冠心病和中风/短暂性脑缺血发作。使用开源 Canary NLP 系统,根据 800 份“训练集”记录设计了五个独立的 NLP 模块,并在 200 份“测试集”记录上进行了验证。
在五个 NLP 模块中,句子级和记录级的敏感性、特异性和阳性预测值始终大于 85%,且通常大于 90%。对于诊断清晰度较高的疾病(如糖尿病和高血压),准确性往往最高,而对于诊断更具挑战性的疾病(如心肌梗死和栓塞性中风),准确性可能略低,这可能导致记录不太明确。
我们设计了五个开源且高度准确的 NLP 模块,可用于评估自由文本健康记录中重要心血管合并症的存在。这些模块已被置于公共领域,可在任何机构用于临床研究、试验招募和人群管理,也可作为进一步开发心血管 NLP 工具的基础。