Institute for Visual and Analytic Computing, University of Rostock, Rostock, Germany.
Faculty of Computer Science, University of New Brunswick, Fredericton, Canada.
PLoS Comput Biol. 2021 Aug 5;17(8):e1009227. doi: 10.1371/journal.pcbi.1009227. eCollection 2021 Aug.
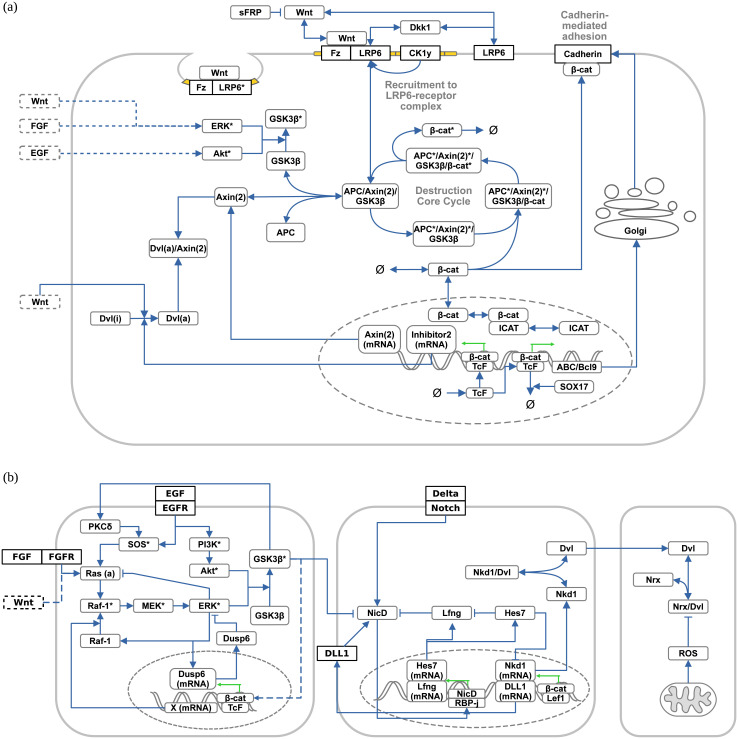
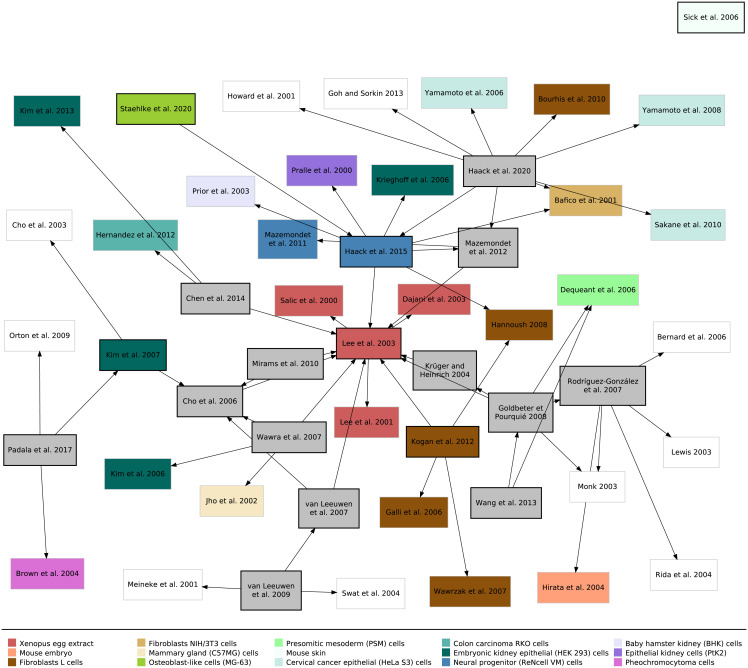
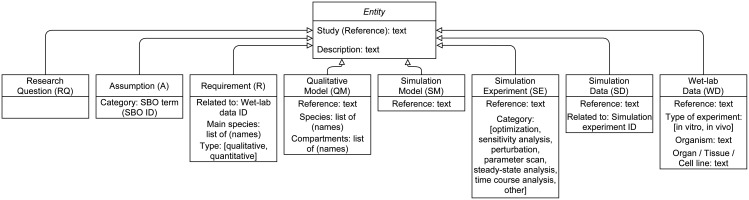
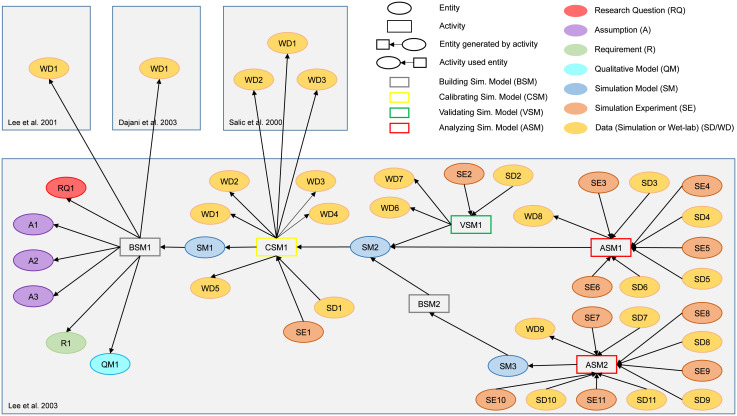
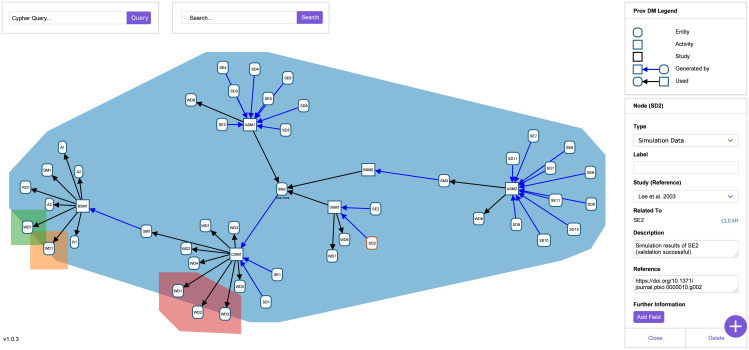
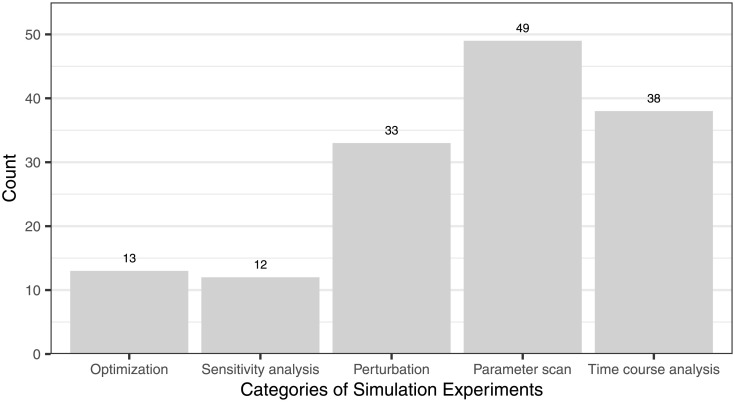
For many biological systems, a variety of simulation models exist. A new simulation model is rarely developed from scratch, but rather revises and extends an existing one. A key challenge, however, is to decide which model might be an appropriate starting point for a particular problem and why. To answer this question, we need to identify entities and activities that contributed to the development of a simulation model. Therefore, we exploit the provenance data model, PROV-DM, of the World Wide Web Consortium and, building on previous work, continue developing a PROV ontology for simulation studies. Based on a case study of 19 Wnt/β-catenin signaling models, we identify crucial entities and activities as well as useful metadata to both capture the provenance information from individual simulation studies and relate these forming a family of models. The approach is implemented in WebProv, a web application for inserting and querying provenance information. Our specialization of PROV-DM contains the entities Research Question, Assumption, Requirement, Qualitative Model, Simulation Model, Simulation Experiment, Simulation Data, and Wet-lab Data as well as activities referring to building, calibrating, validating, and analyzing a simulation model. We show that most Wnt simulation models are connected to other Wnt models by using (parts of) these models. However, the overlap, especially regarding the Wet-lab Data used for calibration or validation of the models is small. Making these aspects of developing a model explicit and queryable is an important step for assessing and reusing simulation models more effectively. Exposing this information helps to integrate a new simulation model within a family of existing ones and may lead to the development of more robust and valid simulation models. We hope that our approach becomes part of a standardization effort and that modelers adopt the benefits of provenance when considering or creating simulation models.
对于许多生物系统,存在各种模拟模型。新的模拟模型很少从零开始开发,而是修改和扩展现有的模型。然而,一个关键的挑战是确定哪个模型可能是特定问题的适当起点,以及原因。为了回答这个问题,我们需要确定对模拟模型的开发有贡献的实体和活动。因此,我们利用了万维网联盟的 PROV-DM 起源数据模型,并在以前工作的基础上,继续为模拟研究开发 PROV 本体。通过对 19 个 Wnt/β-连环蛋白信号模型的案例研究,我们确定了关键的实体和活动,以及有用的元数据,以便从单个模拟研究中捕获起源信息,并将这些信息联系起来,形成一个模型系列。该方法在 WebProv 中实现,这是一个用于插入和查询起源信息的 Web 应用程序。我们对 PROV-DM 的专业化包含了实体研究问题、假设、要求、定性模型、模拟模型、模拟实验、模拟数据和湿实验室数据,以及指称构建、校准、验证和分析模拟模型的活动。我们表明,大多数 Wnt 模拟模型通过使用(部分)这些模型与其他 Wnt 模型相关联。然而,重叠,特别是关于用于校准或验证模型的湿实验室数据,很小。使模型开发的这些方面变得显式和可查询是有效评估和重用模拟模型的重要步骤。公开这些信息有助于在现有的模型系列中集成新的模拟模型,并可能导致开发更健壮和有效的模拟模型。我们希望我们的方法成为标准化工作的一部分,并且建模人员在考虑或创建模拟模型时采用起源的好处。