Carnegie Mellon University, 5000 Forbes Ave, Pittsburgh, PA, USA.
University of Pittsburgh, 5607 Baum Blvd, Pittsburgh, PA, USA.
J Biomed Inform. 2021 Sep;121:103880. doi: 10.1016/j.jbi.2021.103880. Epub 2021 Aug 12.
Biomedical natural language processing tools are increasingly being applied for broad-coverage information extraction-extracting medical information of all types in a scientific document or a clinical note. In such broad-coverage settings, linking mentions of medical concepts to standardized vocabularies requires choosing the best candidate concepts from large inventories covering dozens of types. This study presents a novel semantic type prediction module for biomedical NLP pipelines and two automatically-constructed, large-scale datasets with broad coverage of semantic types.
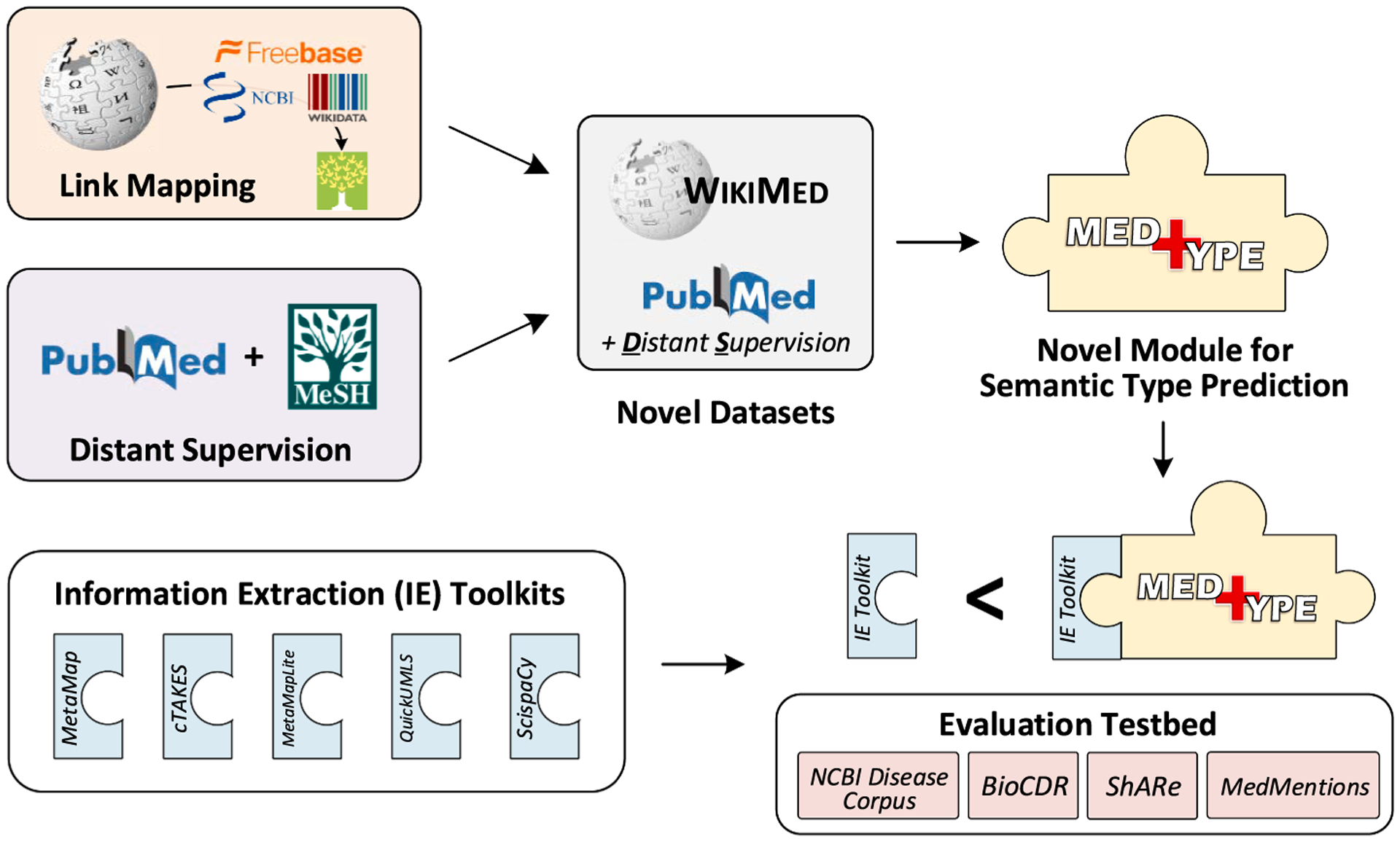
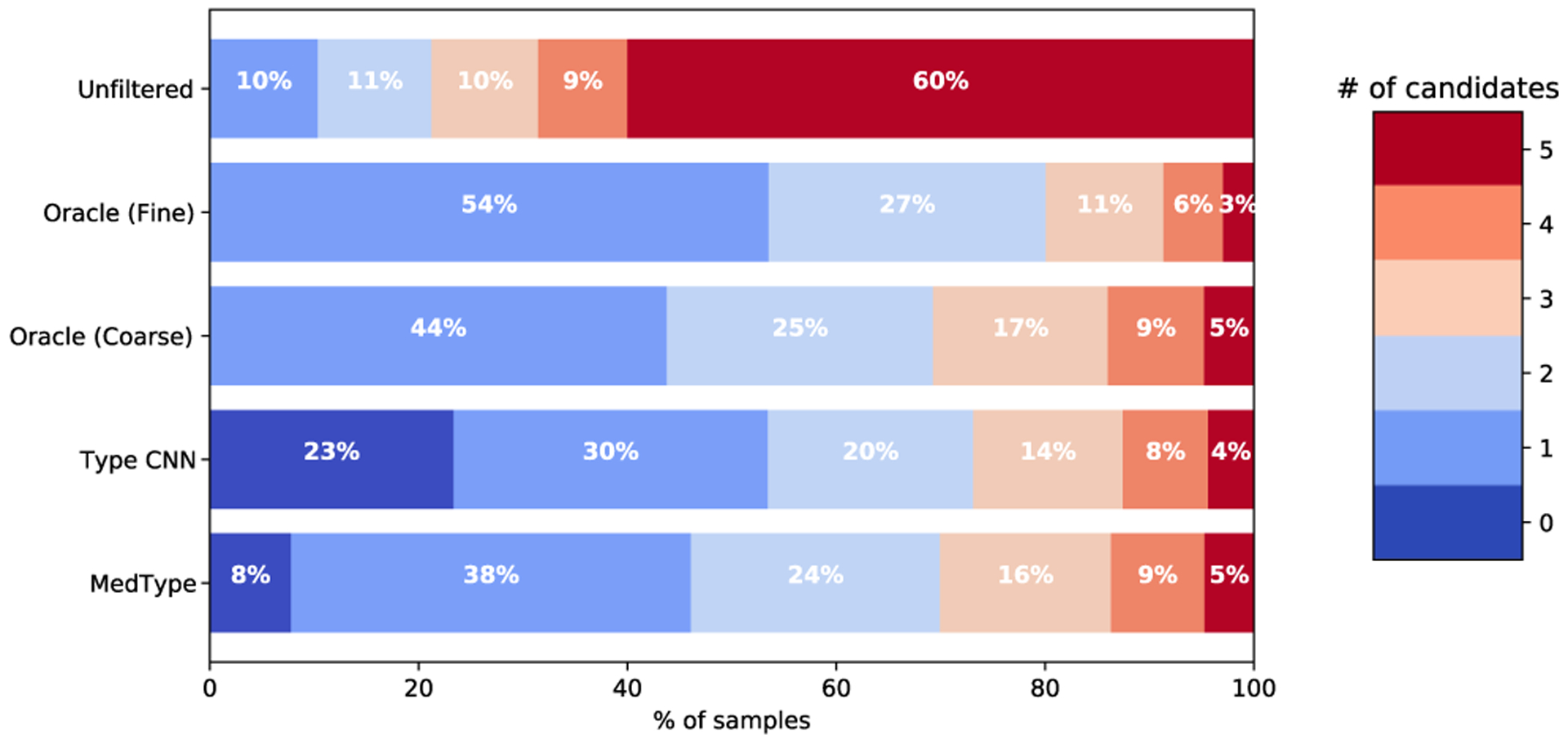
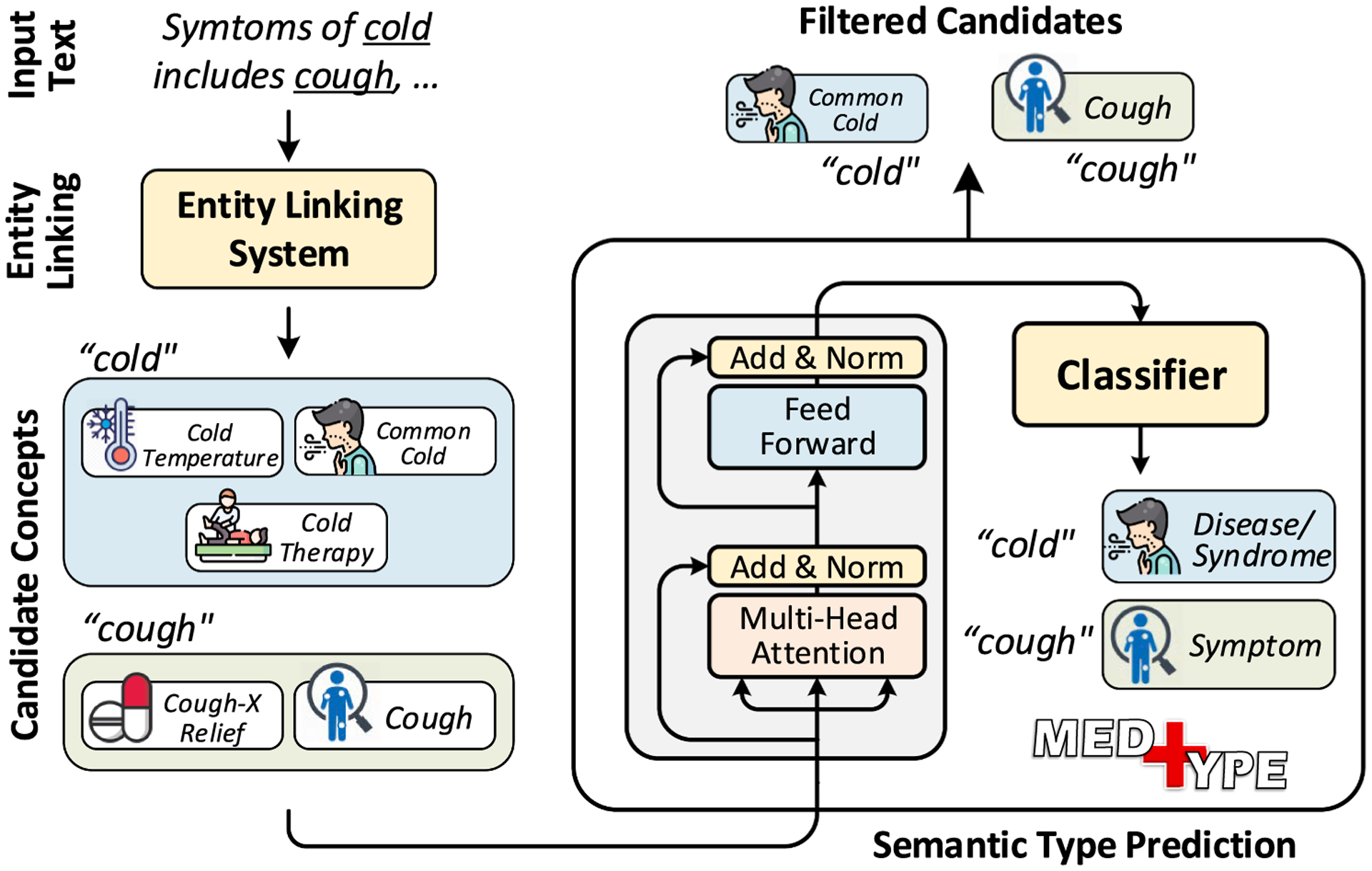
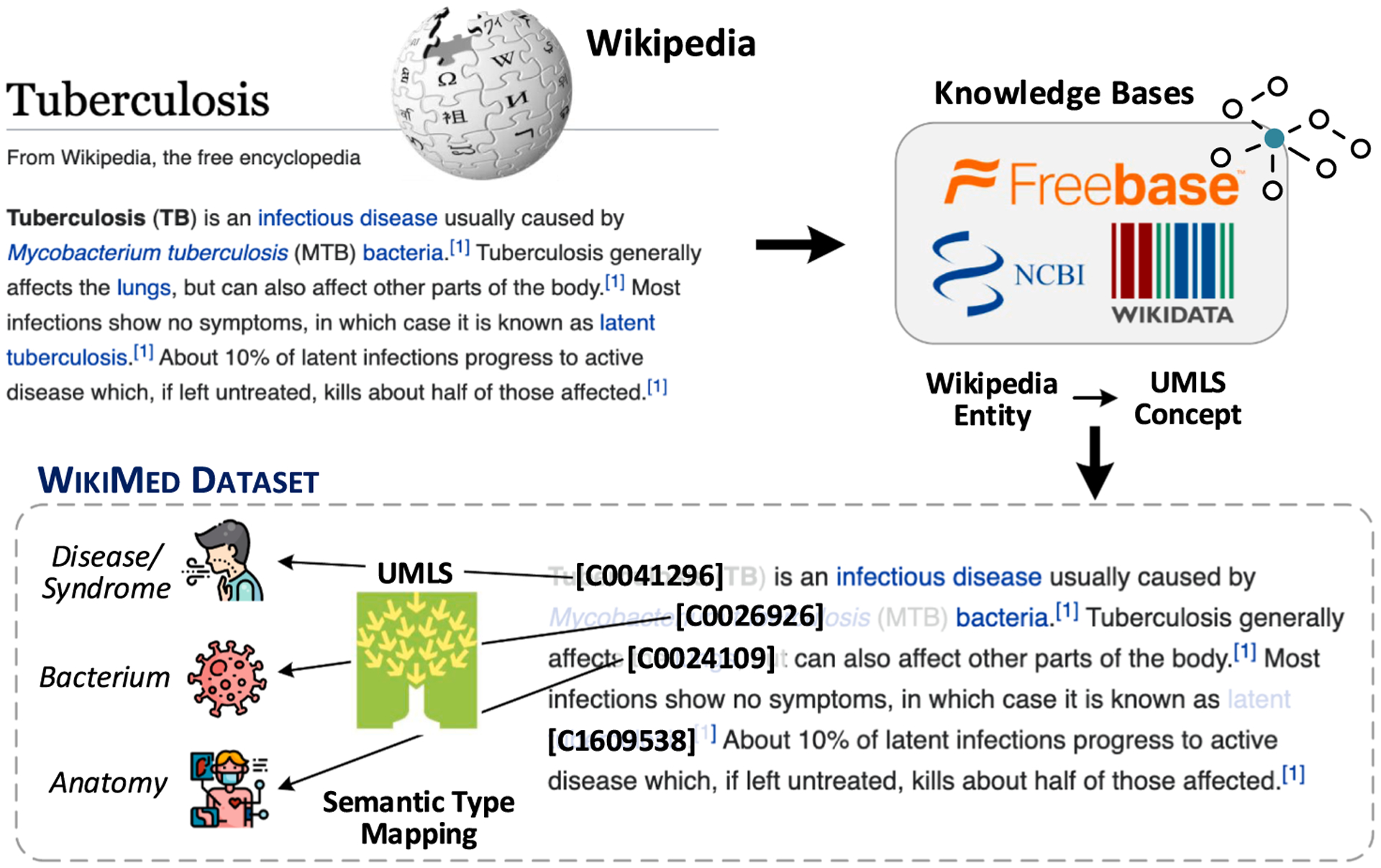
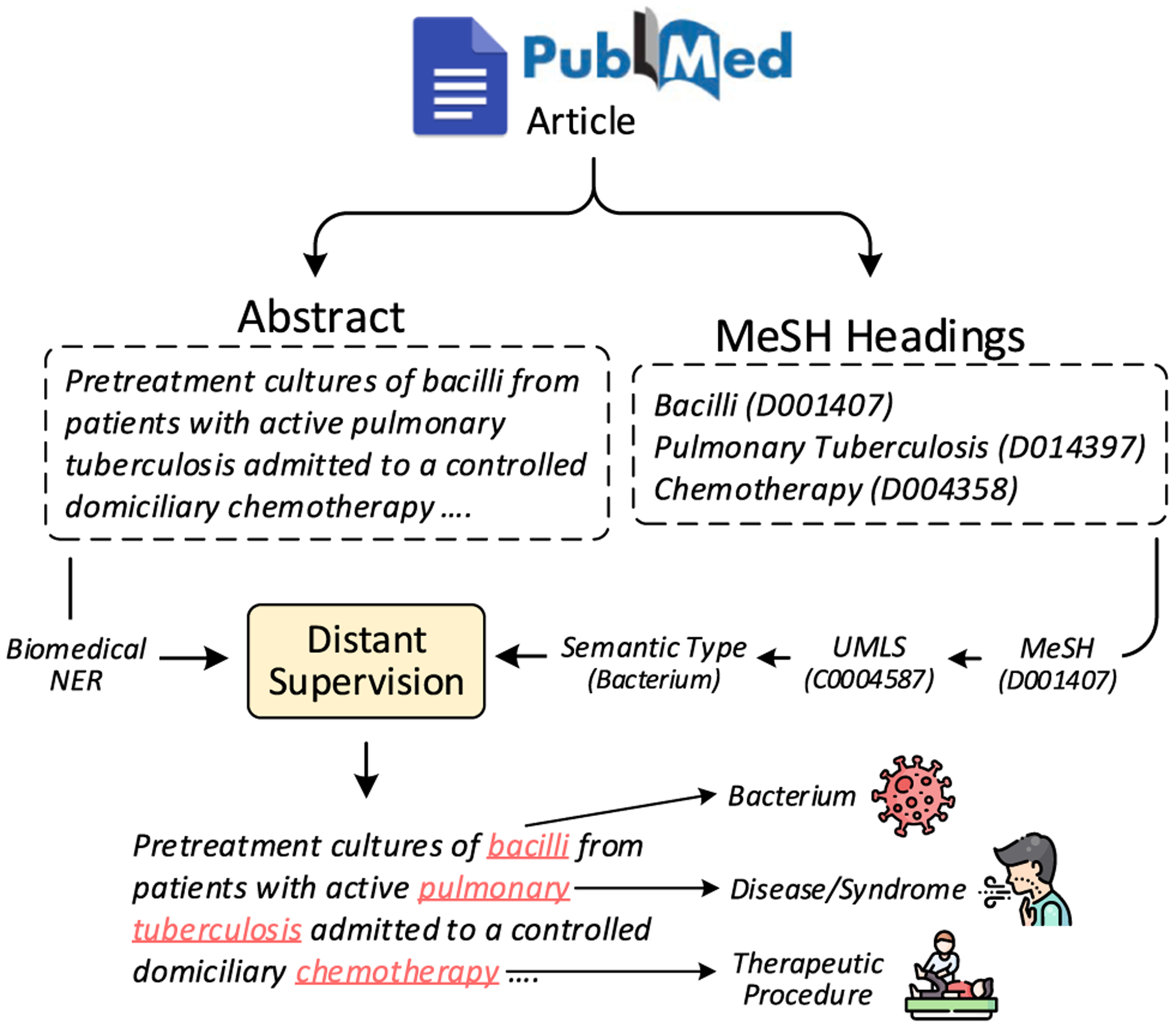
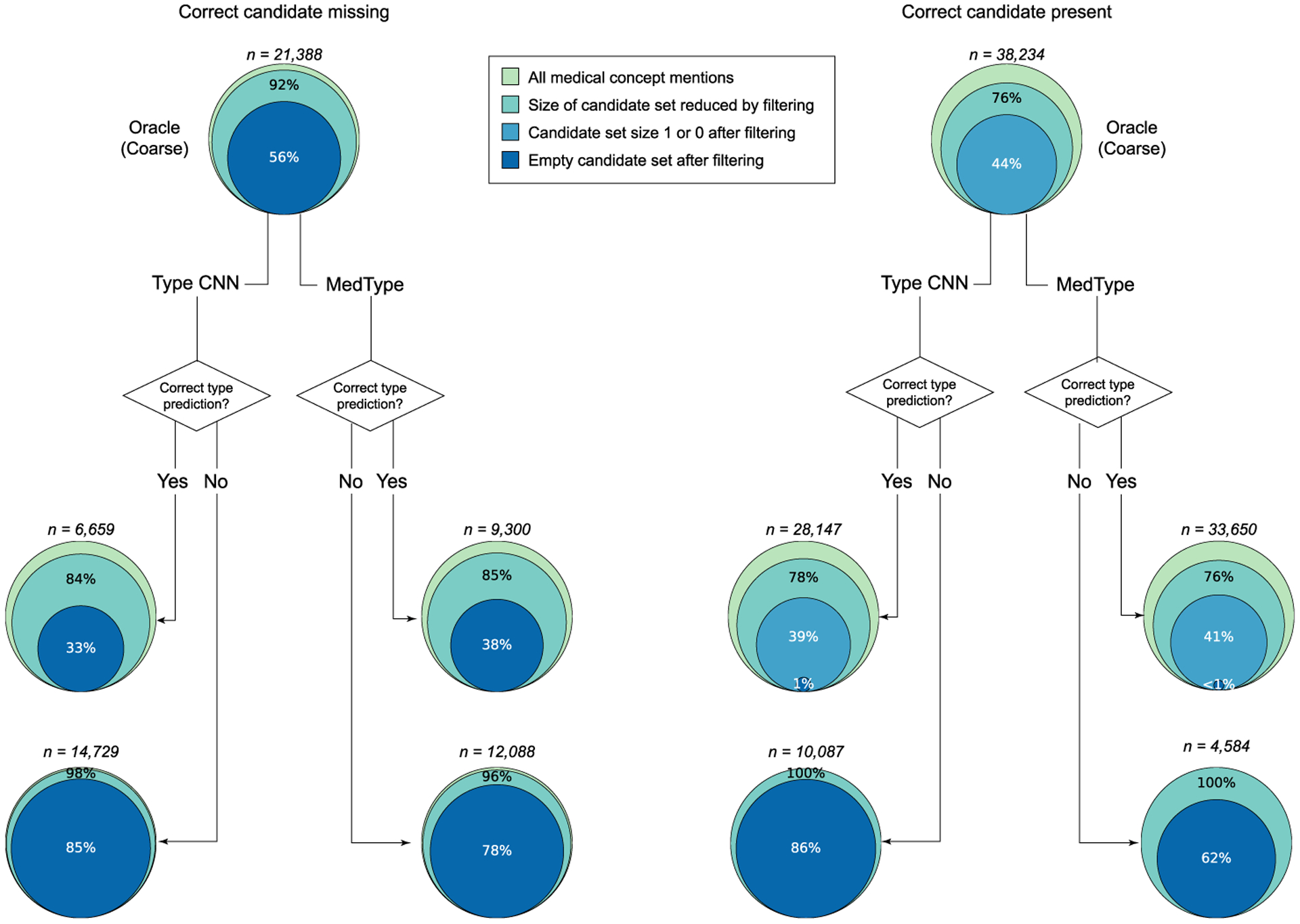
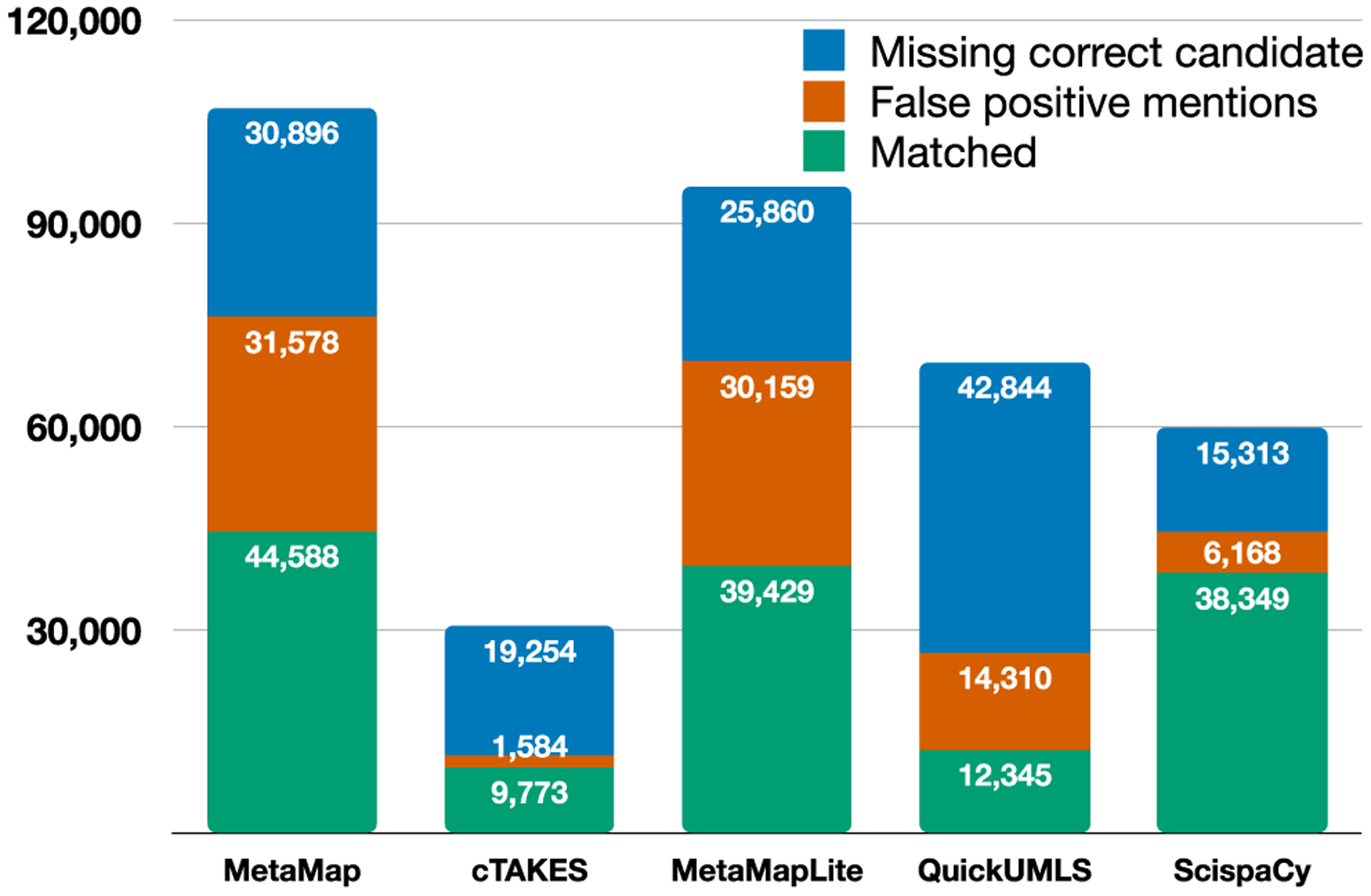
We experiment with five off-the-shelf biomedical NLP toolkits on four benchmark datasets for medical information extraction from scientific literature and clinical notes. All toolkits adopt a staged approach of mention detection followed by two stages of medical entity linking: (1) generating a list of candidate concepts, and (2) picking the best concept among them. We introduce a semantic type prediction module to alleviate the problem of overgeneration of candidate concepts by filtering out irrelevant candidate concepts based on the predicted semantic type of a mention. We present MedType, a fully modular semantic type prediction model which we integrate into the existing NLP toolkits. To address the dearth of broad-coverage training data for medical information extraction, we further present WikiMed and PubMedDS, two large-scale datasets for medical entity linking.
Semantic type filtering improves medical entity linking performance across all toolkits and datasets, often by several percentage points of F-1. Further, pretraining MedType on our novel datasets achieves state-of-the-art performance for semantic type prediction in biomedical text.
Semantic type prediction is a key part of building accurate NLP pipelines for broad-coverage information extraction from biomedical text. We make our source code and novel datasets publicly available to foster reproducible research.
生物医学自然语言处理工具越来越多地被应用于广泛覆盖的信息提取——从科学文献或临床记录中提取各种类型的医学信息。在这种广泛覆盖的环境中,将医学概念的提及与标准化词汇表联系起来需要从涵盖数十种类型的大型库存中选择最佳候选概念。本研究提出了一种新的生物医学自然语言处理管道的语义类型预测模块,以及两个具有广泛语义类型覆盖的自动构建的大规模数据集。
我们在四个用于从科学文献和临床记录中提取医学信息的基准数据集上,对五个现成的生物医学自然语言处理工具包进行了实验。所有工具包都采用分阶段的方法,即先进行提及检测,然后再进行两个阶段的医学实体链接:(1)生成候选概念列表,(2)从其中选择最佳概念。我们引入了一种语义类型预测模块,通过根据提及的预测语义类型过滤掉不相关的候选概念来缓解候选概念过度生成的问题。我们提出了 MedType,这是一种完全模块化的语义类型预测模型,我们将其集成到现有的自然语言处理工具包中。为了解决医学信息提取中缺乏广泛覆盖的训练数据的问题,我们进一步提出了 WikiMed 和 PubMedDS,这两个用于医学实体链接的大规模数据集。
语义类型过滤提高了所有工具包和数据集的医学实体链接性能,通常可以提高几个百分点的 F-1 值。此外,在我们的新数据集上对 MedType 进行预训练可以实现生物医学文本中语义类型预测的最新性能。
语义类型预测是从生物医学文本中构建准确的广泛覆盖信息提取的自然语言处理管道的关键部分。我们公开了我们的源代码和新数据集,以促进可重复的研究。