Key Laboratory of Advanced Design and Intelligent Computing, Ministry of Education, Dalian University, 116622, Dalian, China.
School of Computer Science and Artificial Intelligence, Wuhan University of Technology, 430070, Wuhan, China.
BMC Bioinformatics. 2023 Mar 16;24(1):97. doi: 10.1186/s12859-023-05209-z.
The main task of medical entity disambiguation is to link mentions, such as diseases, drugs, or complications, to standard entities in the target knowledge base. To our knowledge, models based on Bidirectional Encoder Representations from Transformers (BERT) have achieved good results in this task. Unfortunately, these models only consider text in the current document, fail to capture dependencies with other documents, and lack sufficient mining of hidden information in contextual texts.
We propose B-LBConA, which is based on Bio-LinkBERT and context-aware mechanism. Specifically, B-LBConA first utilizes Bio-LinkBERT, which is capable of learning cross-document dependencies, to obtain embedding representations of mentions and candidate entities. Then, cross-attention is used to capture the interaction information of mention-to-entity and entity-to-mention. Finally, B-LBConA incorporates disambiguation clues about the relevance between the mention context and candidate entities via the context-aware mechanism.
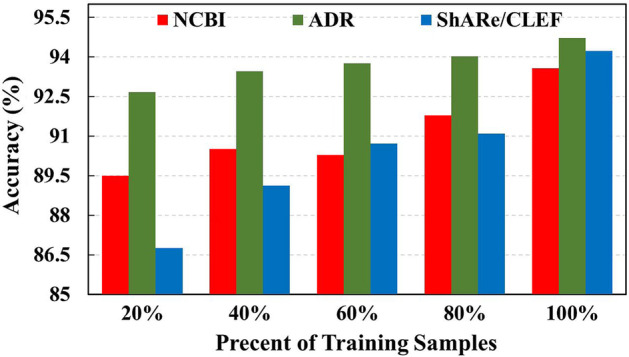
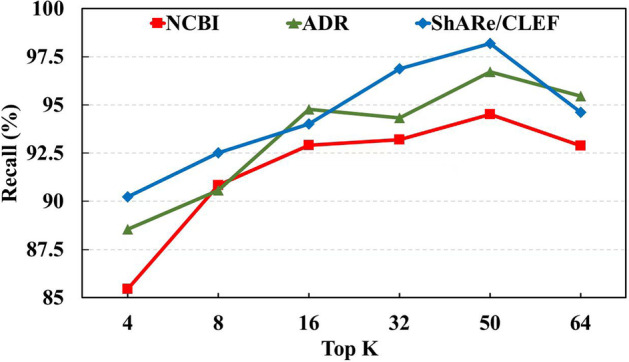
Experiment results on three publicly available datasets, NCBI, ADR and ShARe/CLEF, show that B-LBConA achieves a signifcantly more accurate performance compared with existing models.
医学实体消歧的主要任务是将提及(如疾病、药物或并发症)链接到目标知识库中的标准实体。据我们所知,基于变压器的双向编码器表示(BERT)的模型在这项任务中取得了很好的效果。不幸的是,这些模型仅考虑当前文档中的文本,无法捕获与其他文档的依赖关系,并且缺乏对上下文文本中隐藏信息的充分挖掘。
我们提出了基于生物链接 BERT 和上下文感知机制的 B-LBConA。具体来说,B-LBConA 首先利用能够学习跨文档依赖关系的生物链接 BERT,获取提及和候选实体的嵌入表示。然后,使用交叉注意力来捕获提及到实体和实体到提及的交互信息。最后,B-LBConA 通过上下文感知机制结合提及上下文和候选实体之间相关性的消歧线索。
在三个公开可用的数据集 NCBI、ADR 和 ShARe/CLEF 上的实验结果表明,B-LBConA 与现有模型相比,具有更高的准确性。