Department of Computer Science and Engineering, Jadavpur University, Kolkata 700032, India.
Department of Information Technology, Jadavpur University, Kolkata 700106, India.
Sensors (Basel). 2021 Aug 18;21(16):5571. doi: 10.3390/s21165571.
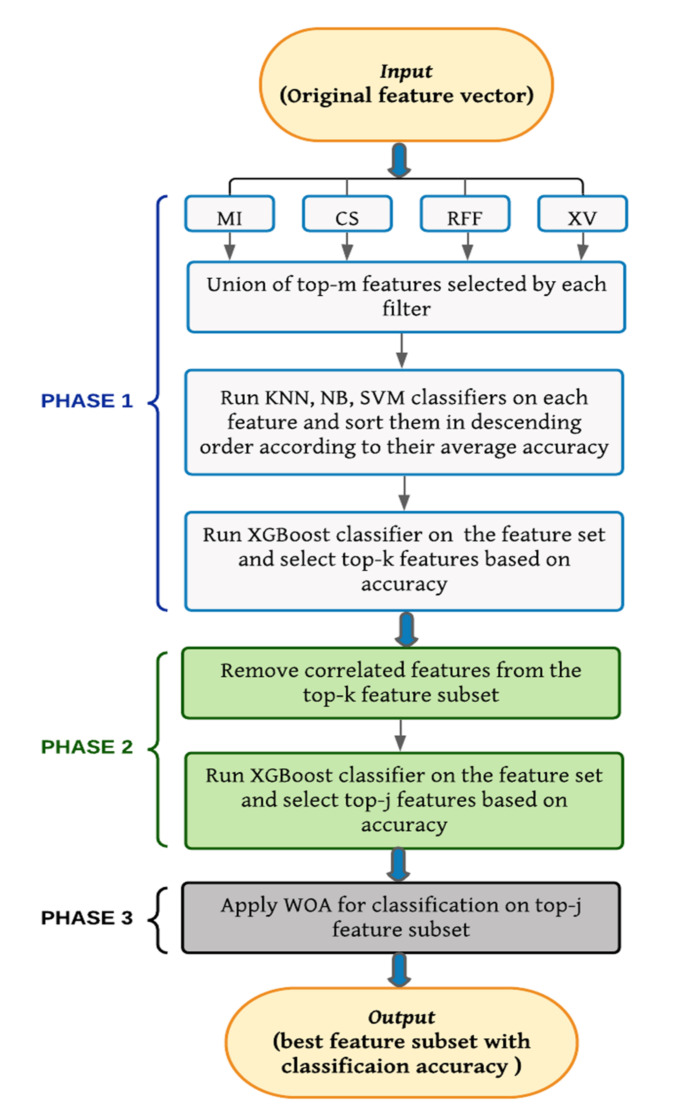
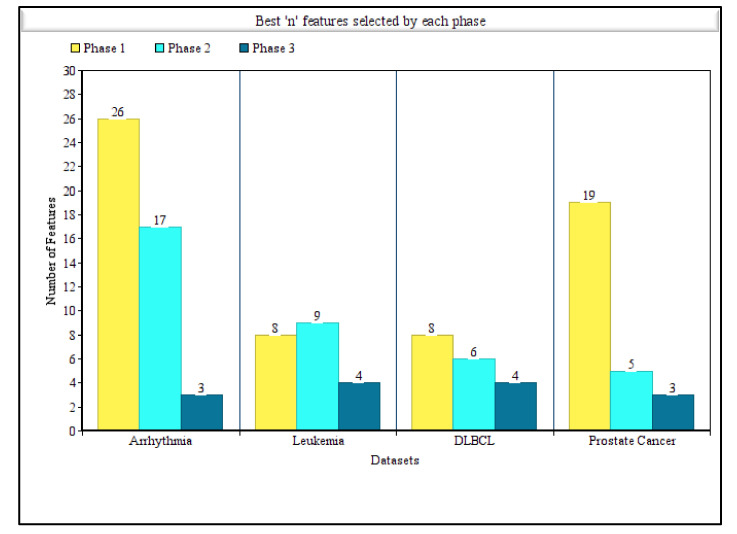
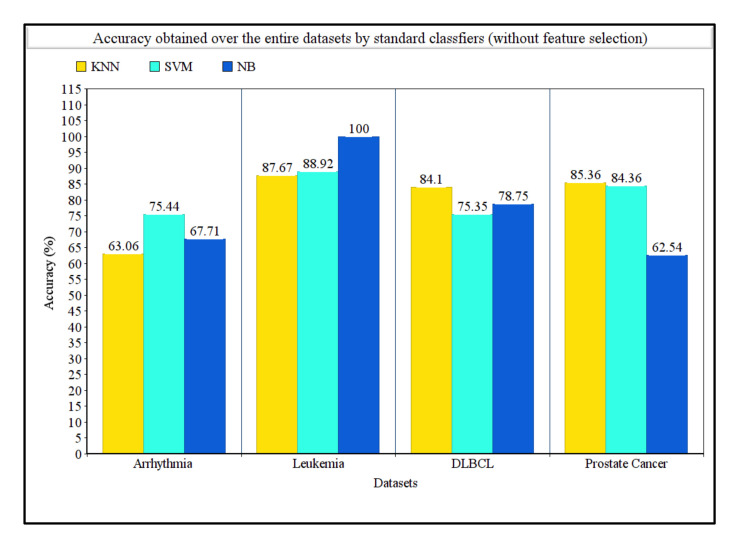
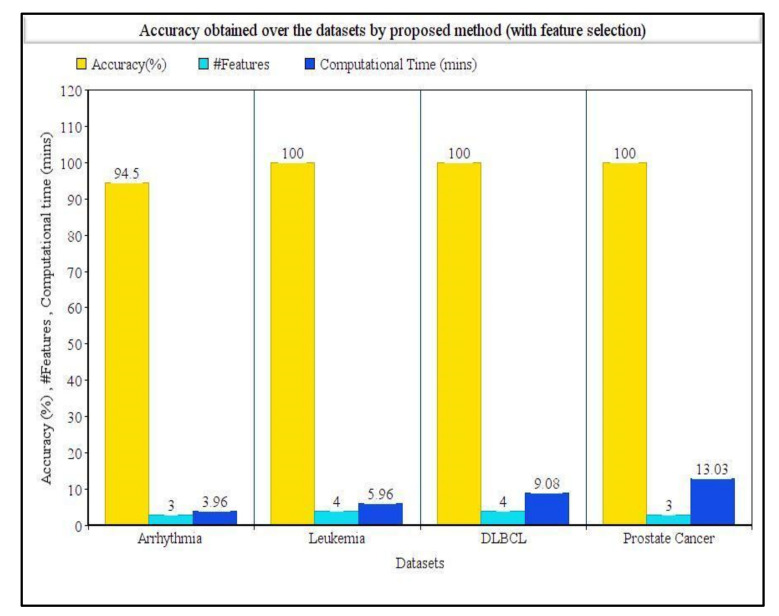
In machine learning and data science, feature selection is considered as a crucial step of data preprocessing. When we directly apply the raw data for classification or clustering purposes, sometimes we observe that the learning algorithms do not perform well. One possible reason for this is the presence of redundant, noisy, and non-informative features or attributes in the datasets. Hence, feature selection methods are used to identify the subset of relevant features that can maximize the model performance. Moreover, due to reduction in feature dimension, both training time and storage required by the model can be reduced as well. In this paper, we present a tri-stage wrapper-filter-based feature selection framework for the purpose of medical report-based disease detection. In the first stage, an ensemble was formed by four filter methods-Mutual Information, ReliefF, Chi Square, and Xvariance-and then each feature from the union set was assessed by three classification algorithms-support vector machine, naïve Bayes, and -nearest neighbors-and an average accuracy was calculated. The features with higher accuracy were selected to obtain a preliminary subset of optimal features. In the second stage, Pearson correlation was used to discard highly correlated features. In these two stages, XGBoost classification algorithm was applied to obtain the most contributing features that, in turn, provide the best optimal subset. Then, in the final stage, we fed the obtained feature subset to a meta-heuristic algorithm, called whale optimization algorithm, in order to further reduce the feature set and to achieve higher accuracy. We evaluated the proposed feature selection framework on four publicly available disease datasets taken from the UCI machine learning repository, namely, arrhythmia, leukemia, DLBCL, and prostate cancer. Our obtained results confirm that the proposed method can perform better than many state-of-the-art methods and can detect important features as well. Less features ensure less medical tests for correct diagnosis, thus saving both time and cost.
在机器学习和数据科学中,特征选择被认为是数据预处理的关键步骤。当我们直接将原始数据应用于分类或聚类目的时,有时我们会发现学习算法表现不佳。造成这种情况的一个可能原因是数据集存在冗余、嘈杂和非信息特征或属性。因此,特征选择方法用于识别可以最大化模型性能的相关特征子集。此外,由于特征维度的减少,模型所需的训练时间和存储也可以减少。在本文中,我们提出了一种基于三阶段包装-过滤器的特征选择框架,用于基于医疗报告的疾病检测。在第一阶段,通过四个过滤器方法(互信息、ReliefF、卡方和 Xvariance)形成一个集成,然后对并集的每个特征进行三种分类算法(支持向量机、朴素贝叶斯和 K-最近邻)的评估,并计算平均准确率。选择准确率较高的特征以获得初步的最佳特征子集。在第二阶段,使用 Pearson 相关性来丢弃高度相关的特征。在这两个阶段中,应用 XGBoost 分类算法以获得最有贡献的特征,进而提供最佳的最佳子集。然后,在最后一个阶段,我们将获得的特征子集输入鲸鱼优化算法(一种元启发式算法),以进一步减少特征集并获得更高的准确率。我们在 UCI 机器学习存储库中从四个公开可用的疾病数据集上评估了所提出的特征选择框架,即心律失常、白血病、DLBCL 和前列腺癌。我们的结果证实,该方法可以比许多最先进的方法表现得更好,并且可以检测到重要的特征。更少的特征可以确保正确诊断所需的医疗检查更少,从而节省时间和成本。