University of Kentucky, Lexington, Kentucky, United States of America.
Qingdao University, Qingdao, Shandong, China.
PLoS One. 2021 Sep 7;16(9):e0256648. doi: 10.1371/journal.pone.0256648. eCollection 2021.
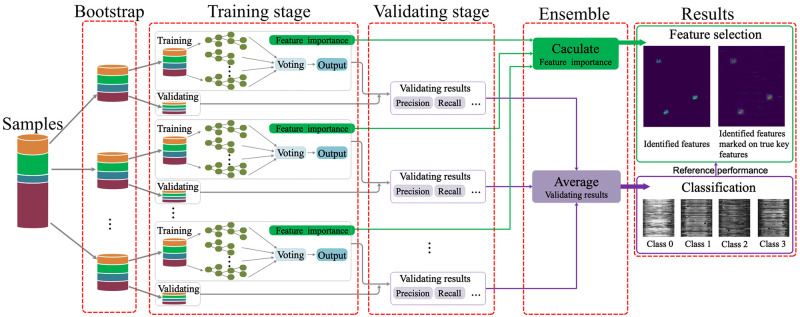
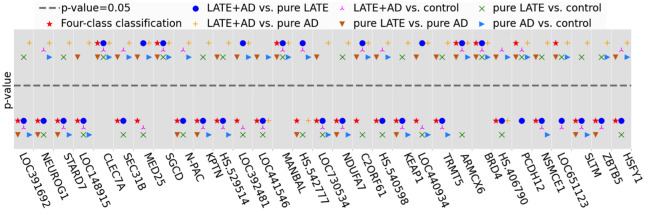
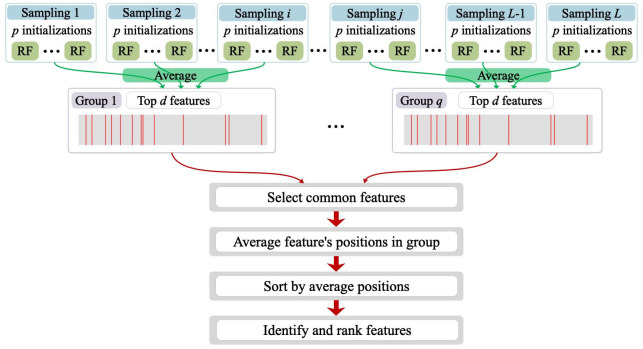
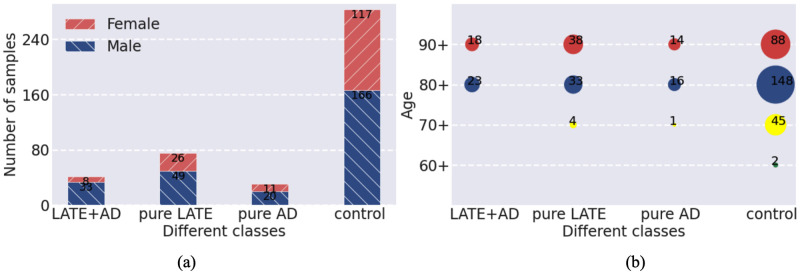
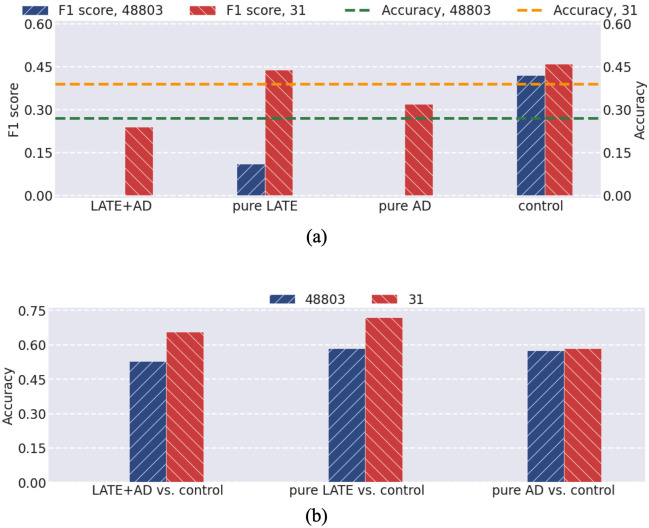
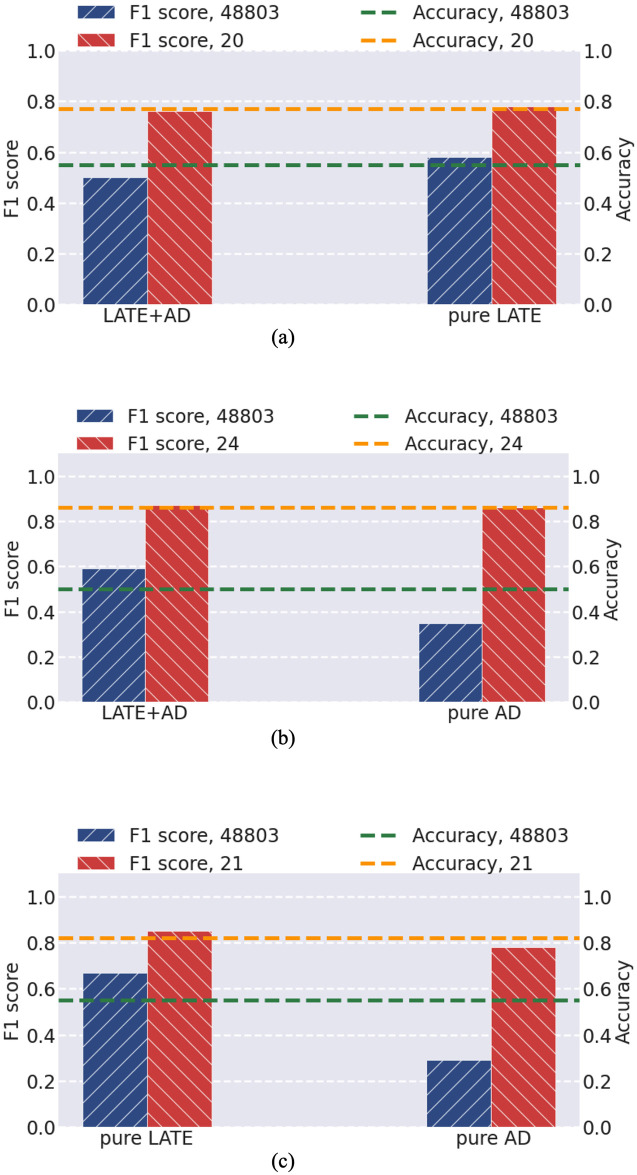
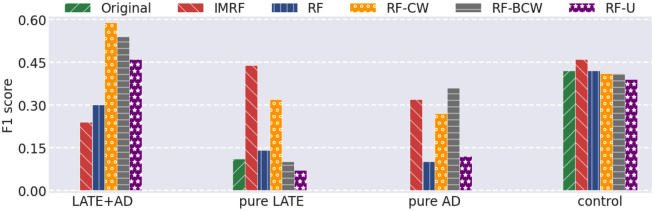
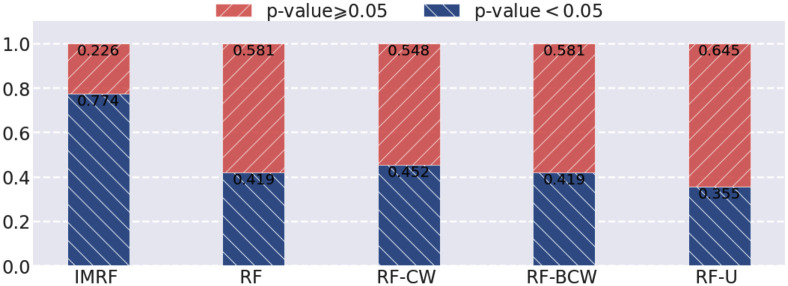
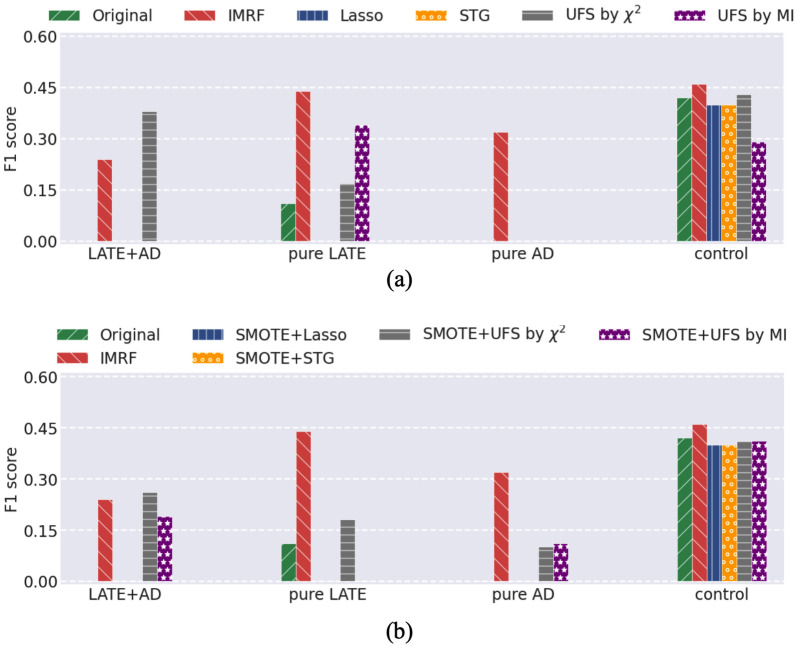
Alzheimer's disease (AD) is a complex neurodegenerative disorder that affects thinking, memory, and behavior. Limbic-predominant age-related TDP-43 encephalopathy (LATE) is a recently identified common neurodegenerative disease that mimics the clinical symptoms of AD. The development of drugs to prevent or treat these neurodegenerative diseases has been slow, partly because the genes associated with these diseases are incompletely understood. A notable hindrance from data analysis perspective is that, usually, the clinical samples for patients and controls are highly imbalanced, thus rendering it challenging to apply most existing machine learning algorithms to directly analyze such datasets. Meeting this data analysis challenge is critical, as more specific disease-associated gene identification may enable new insights into underlying disease-driving mechanisms and help find biomarkers and, in turn, improve prospects for effective treatment strategies. In order to detect disease-associated genes based on imbalanced transcriptome-wide data, we proposed an integrated multiple random forests (IMRF) algorithm. IMRF is effective in differentiating putative genes associated with subjects having LATE and/or AD from controls based on transcriptome-wide data, thereby enabling effective discrimination between these samples. Various forms of validations, such as cross-domain verification of our method over other datasets, improved and competitive classification performance by using identified genes, effectiveness of testing data with a classifier that is completely independent from decision trees and random forests, and relationships with prior AD and LATE studies on the genes linked to neurodegeneration, all testify to the effectiveness of IMRF in identifying genes with altered expression in LATE and/or AD. We conclude that IMRF, as an effective feature selection algorithm for imbalanced data, is promising to facilitate the development of new gene biomarkers as well as targets for effective strategies of disease prevention and treatment.
阿尔茨海默病(AD)是一种复杂的神经退行性疾病,影响思维、记忆和行为。以边缘系统为主的与年龄相关的 TDP-43 脑病(LATE)是一种最近发现的常见神经退行性疾病,其临床症状类似于 AD。开发预防或治疗这些神经退行性疾病的药物进展缓慢,部分原因是与这些疾病相关的基因尚未完全了解。从数据分析的角度来看,一个显著的障碍是,通常情况下,患者和对照组的临床样本高度不平衡,因此,大多数现有的机器学习算法难以直接分析此类数据集。应对这一数据分析挑战至关重要,因为更具体的疾病相关基因的鉴定可能为潜在疾病驱动机制提供新的见解,并有助于寻找生物标志物,进而提高有效治疗策略的前景。为了基于不平衡的转录组范围数据检测疾病相关基因,我们提出了一种集成多个随机森林(IMRF)算法。IMRF 基于转录组范围的数据,在区分具有 LATE 和/或 AD 的受试者与对照的假定基因方面非常有效,从而能够有效区分这些样本。各种形式的验证,例如在其他数据集上对我们方法的跨域验证、使用鉴定的基因提高和竞争分类性能、使用完全独立于决策树和随机森林的分类器测试数据的有效性,以及与先前 AD 和 LATE 研究的关系,都证明了 IMRF 在识别 LATE 和/或 AD 中表达改变的基因方面的有效性。我们得出结论,IMRF 作为一种有效的不平衡数据特征选择算法,有望促进新的基因生物标志物的开发以及有效预防和治疗疾病策略的靶点。